该小节我们从源代码上分析,应用程序申请Buffer的调用过程,下面是一个从应用程序开始的流程图:
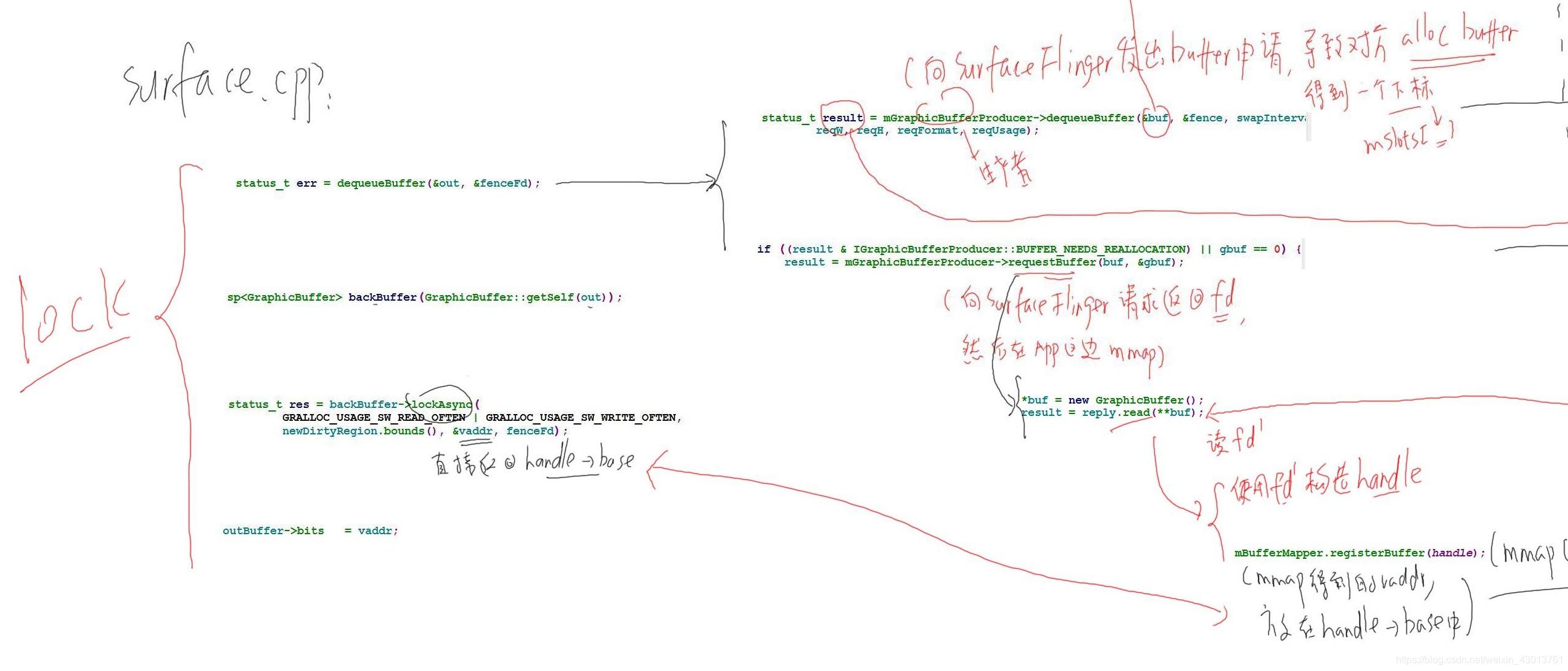
应用程序在调用surface->lock(&outBuffer,NULL);函数的时候,会发起Surface::dequeueBuffer()的操作,进入调用:
/*代理端的生产者*/
status_t result = mGraphicBufferProducer->dequeueBuffer(&buf, &fence,reqWidth, reqHeight, reqFormat, reqUsage);
发起一个远程调用,该函数会查询SurfaceFlinger边的mSlots,输出结果放入buf中,他得到的是数组mSlots的一个下标,表示已经分配了一个mSlots的下标。那么这个远程调用会导致那个函数被调用呢?
进入IGraphicBufferProducer.cpp文件,查找到class BpGraphicBufferProducer (代理类),在找到其中的dequeueBuffer:
virtual status_t dequeueBuffer(int *buf, sp<Fence>* fence, uint32_t width,uint32_t height, PixelFormat format, uint32_t usage) {
/*构建数据*/
data.writeInterfaceToken(IGraphicBufferProducer::getInterfaceDescriptor());
data.writeUint32(width);
data.writeUint32(height);
data.writeInt32(static_cast<int32_t>(format));
data.writeUint32(usage);
/*发起远程调用,到最后调用本文件中的status_t BnGraphicBufferProducer::onTransact方法*/
status_t result = remote()->transact(DEQUEUE_BUFFER, data, &reply);
其中上的所说的onTransact函数如下:
status_t BnGraphicBufferProducer::onTransact(
case DEQUEUE_BUFFER: {
/*此处的dequeueBuffer由他的派生类BufferQueueProducer实现*/
int result = dequeueBuffer(&buf, &fence, width, height, format,usage);
在BufferQueueProducer.cpp文件中:
status_t BufferQueueProducer::dequeueBuffer(int *outSlot,sp<android::Fence> *outFence, uint32_t width, uint32_t height,PixelFormat format, uint32_t usage) {
/*等待空闲的Slot,得到以后把他锁定*/
status_t status = waitForFreeSlotThenRelock(FreeSlotCaller::Dequeue,&found);
const sp<GraphicBuffer>& buffer(mSlots[found].mGraphicBuffer);
/*如果GraphicBuffer 中获取的buffer是空的,或者参数和申请的参数不一样*/
if ((buffer == NULL) ||buffer->needsReallocation(width, height, format, usage))
/*标记为需要重新分配*/
returnFlags |= BUFFER_NEEDS_REALLOCATION;
/*如果需要重新分配*/
if (returnFlags & BUFFER_NEEDS_REALLOCATION) {
/*重新分配*/
sp<GraphicBuffer> graphicBuffer(mCore->mAllocator->createGraphicBuffer(width, height, format, usage,{mConsumerName.string(), mConsumerName.size()}, &error));
现在我们详细的分析一下graphicBuffer,看看其是怎么分配buffer的。之前的小节我们提到过,生产者和消费者指向同一个mCore(BufferQueueCore类),mAllocator(GraphicBufferAlloc类)。
进入GraphicBufferAlloc.cpp,查看其createGraphicBuffer函数:
sp<GraphicBuffer> GraphicBufferAlloc::createGraphicBuffer(uint32_t width,uint32_t height, PixelFormat format, uint32_t usage,std::string requestorName, status_t* error) {
sp<GraphicBuffer> graphicBuffer(new GraphicBuffer(width, height, format, usage, std::move(requestorName)));
进入GraphicBuffer.cpp文件,查看其构造函数:
GraphicBuffer::GraphicBuffer(uint32_t inWidth, uint32_t inHeight,PixelFormat inFormat, uint32_t inUsage, std::string requestorName): BASE(),mOwner(ownData), mBufferMapper(GraphicBufferMapper::get()),mInitCheck(NO_ERROR),mId(getUniqueId()), mGenerationNumber(0){
mInitCheck = initSize(inWidth, inHeight, inFormat, inUsage,std::move(requestorName));
GraphicBufferAllocator& allocator = GraphicBufferAllocator::get();
status_t err = allocator.allocate(inWidth, inHeight, inFormat,inUsage,&handle, &outStride, mId, std::move(requestorName));
我们猜测一下initSize会调用gralloc HAL分配buffer,那么肯定是在GraphicBufferAllocator的构造函数中打开HAL了。进入GraphicBufferAllocator的构造函数:
GraphicBufferAllocator::GraphicBufferAllocator(): mLoader(std::make_unique<Gralloc1::Loader>()),mDevice(mLoader->getDevice()) {}
可以知道,其继承于Loader与mDevice,其中Loader的构造函数如下:
Loader::Loader()
: mDevice(nullptr)
{
hw_module_t const* module;
int err = hw_get_module(GRALLOC_HARDWARE_MODULE_ID, &module);
uint8_t majorVersion = (module->module_api_version >> 8) & 0xFF;
uint8_t minorVersion = module->module_api_version & 0xFF;
gralloc1_device_t* device = nullptr;
if (majorVersion == 1) {
gralloc1_open(module, &device);
} else {
if (!mAdapter) {
mAdapter = std::make_unique<Gralloc1On0Adapter>(module);
}
device = mAdapter->getDevice();
}
mDevice = std::make_unique<Gralloc1::Device>(device);
}
可以看到,与我们猜测的一致。下面我们在来分析:
GraphicBufferAllocator& allocator = GraphicBufferAllocator::get();
status_t err = allocator.allocate(inWidth, inHeight, inFormat,inUsage,&handle, &outStride, mId, std::move(requestorName));
中的allocator.allocate:
/*通过Ashmem分配buf,得到fd,使用fd构造handle,并且memap,这边memp得到的虚拟地址只是给SurfaceFlinger进程使用*/
status_t GraphicBufferAllocator::allocate(uint32_t width, uint32_t height,PixelFormat format, uint32_t usage, buffer_handle_t* handle,uint32_t* stride, uint64_t graphicBufferId, std::string requestorName)
auto descriptor = mDevice->createDescriptor();
auto error = descriptor->setDimensions(width, height);
error = descriptor->setFormat(static_cast<android_pixel_format_t>(format));
error = descriptor->setProducerUsage()
error = descriptor->setConsumerUsage(
在SurfaceFlinger生产者roducer.cpp中包含了mCore与mslots[],分配内存就是选定空余的mslots,然后对其进行构造。
打开生产者,BufferQueueProducer.h,可以找到
/*typedef BufferSlot SlotsType[NUM_BUFFER_SLOTS];*/
BufferQueueDefs::SlotsType& mSlots;
可以知道mSlots是一个SlotsType的引用,BufferSlot定义如下(主要成员):
struct BufferSlot {
sp<GraphicBuffer> mGraphicBuffer;
GraphicBuffer中存在函数initSize():
mInitCheck = initSize(inWidth, inHeight, inFormat, inUsage,std::move(requestorName));
GraphicBufferAllocator& allocator = GraphicBufferAllocator::get();
status_t err = allocator.allocate(inWidth, inHeight, inFormat,inUsage,&handle, &outStride, mId, std::move(requestorName));
可以知道GraphicBuffer包括了handle,handle中至少包括了文件句柄,以及base。与之对应在我们应用程序的Surface也尊在mslots[],其中的BufferSlot中的GraohicBuffer也包含了handle,并且handle中也存在fd与base。
现在我们分析了SurfaceFlinger如何创建buffer,下小节我们继续分析,分析其如何传递回去给我们编写的应用程序。