序言
做IT的都知道数据的重要性,尤其在这个万物互联的时代,一方面TB、PB级的数据迅速增长,另一方面需要从这些数据中获取各种各样的复杂信息。基于传统的关系数据库技术的数据分析已经满足不了海量数据的需求,这种情况下基于分布式的大数据技术诞生了,它是为了解决海量数据的存储和计算的。
毫无疑问的是,就当前形式来看,大数据和人工智能是未来的两大核心技术,即使人工智能很多时候也是建立在大数据基础上,比如深度学习就需要海量的数据样本,机器学习可能需要大量标记数据等。
然而有一点,大数据底层理解起来更加困难了:传统的自顶向下的分层结构,即使我们不理解相应的构建技术,但是整个工作流程无非是一层层调用下层服务反馈结果,对于调用者来说,下层是一层层累加的黑盒,对于单机程序可能是可执行->对应dll/so->系统API,对于Web服务端可能是网页->服务器->数据库;但是到基于分布式的大数据技术这里,分布式的处理需要协调成千上万台机器并行处理,这就有些难理解了,毕竟人脑还是习惯于串行思维。
当今大数据技术栈基本上都是构建在Hadoop生态体系上,Hadoop不仅是一个大数据系统,也越来越成为一个平台,说Hadoop掌握了整个大数据技术的走向也不为过。本文旨在通过Hadoop,从宏观上普及整个大数据处理技术的架构和方案,我始终相信好技术一定是最简单的,通过本系列教程相信你对Hadoop乃至之后的大数据技术有更深刻的认识,基于这些认识,整个大数据处理尽在掌握之中,至于说优化Hadoop处理流程和时间、阅读Hadoop源码更是易如反掌。
Hadoop的基本概念
Hadoop是Doug Cutting基于Google开源的三大论文实现的,主要包括如下几个方面:
- HDFS:一个分布式文件系统,Google File System(GFS)的开源实现,解决了海量数据怎么存的问题。
- MapReduce:Google MapReduce的开源实现,解决了海量数据如何算的问题。
- HBase:一个大型的分布式数据库,Google Bigtable的开源实现,解决了如何结构化存储和分析海量数据的问题。
归根结底,Hadoop是如何存和如何算的问题。
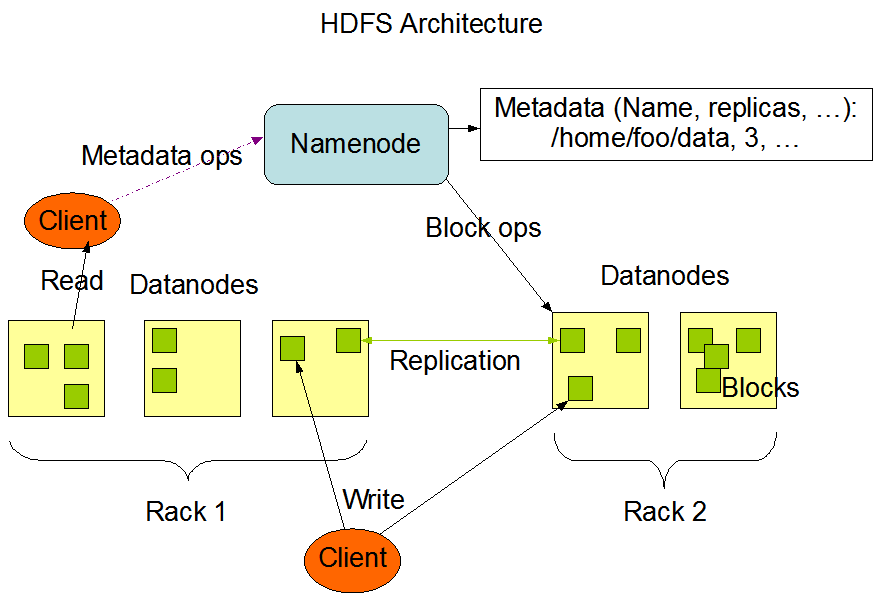
先说,如何存的问题,这就是HDFS解决的问题,传统的存储都是单机,存储有限,现在要做分布式存储,要如何做呢?先看如下hdfs的架构图,数据内容是分布式存储在Datanodes(数据节点)上的,那么具体的一个文件存在哪些Datanodes上呢?答案是引入一个统一管理节点,即图中的Namenode(名字节点),Namenode上保存了每个文件对应的Datanodes位置,也就是所谓的MetaData(元数据)。客户端存储文件时,通过Client提交文件,Namenode会分析拆解文件成不同的Blocks(块)分别存储到各个节点上;客户端取文件时查询Namenode获取各个块的位置,取回并拼接成之前存入的文件。相比单机存储,分布式存储为了数据的高可靠、高可用性,同一份数据会存多个副本(Replication),这就是常说的多备。
再说,如何算的问题,这是MapReduce计算模型要解决的问题。传统的单机处理程序始终有上限,要想获得更高处理能力,必须升级现有单机配置,然而单机处理的性能始终是有限的且很难动态扩展;现代大数据分布式架构,强调分布式协调处理,一台处理不过来就一百台,一百台处理不过来就一千一万台,这样不仅可以分布式并行处理,而且扩展简单且容错能力强。在这种情况下,需要有一种并行计算的模型,最大程度的利用分布式的优势,这就是MapReduce计算模型。
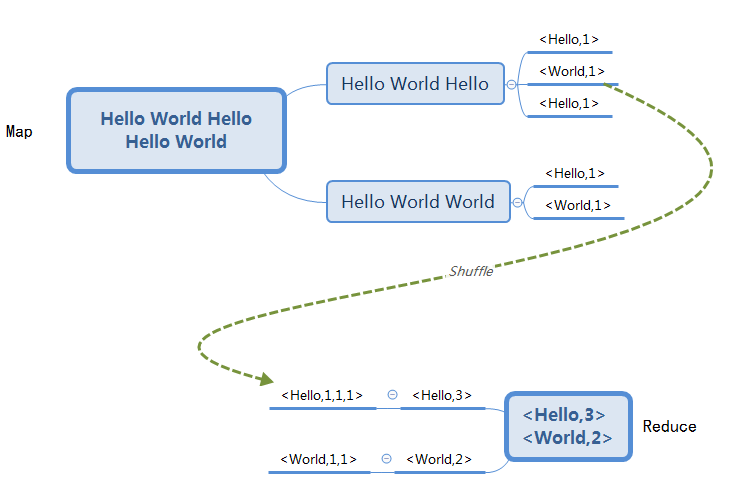
实际上,MapReduce并不是什么新概练,在分布式处理之前,LIsp和其他函数式语言早就出现了map和reduce原语,只不过在分布式时代,将这一概念延伸到分布式,并提供了可实现的方法。如下,以最经典的WordCount为例,为了统计文件中单词的个数,将文件分割成多个部门,分别给不同机器处理,生成<单词,次数>映射,如<Hello,1><World,1>,即为Map过程,然后将不同机器上相同单词的映射归到一起如<Hello,1,1,1>,统一计算每个单词的出现次数,如<Hello,3><World,2>,即为Reduce过程。这两个过程都不复杂,很容易理解也很容易实现并行化,难的是Map到Reduce的中间过程,也就是常说的Shuffle过程,分布式实现难点和集群调优针对的主要是这一过程,后续会详述。
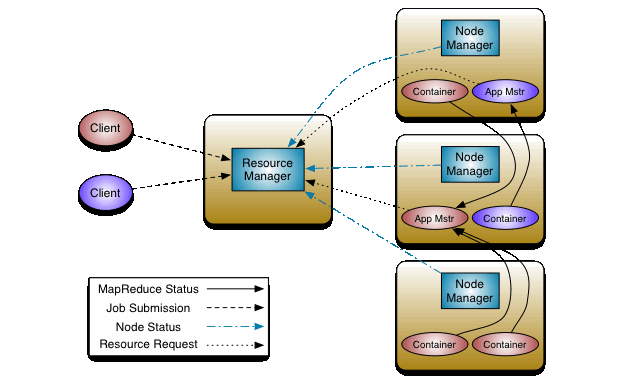
刚刚说的是计算模型的问题,这个模型承载了我们的算法模型,但是对于分布式有个问题还没解决,就是分布式协调的问题,哪一步该哪些机器做什么,需要统一调度处理,这就是Yarn调度框架负责的事情。如下,Yarn框架通过Resource Manager来管理整个计算资源(CPU和内存),Node Manager为实际执行器,每当客户端(Client)提交一个执行任务,Resource Manager协调指定数目Node Manager分配Container(执行容器),每个任务的实际执行又分为管理者App Master和对应的实际执行YarnChild,他们都在Container中运行。每个Node Manager上可能同时运行多个Container,他们公用节点计算资源,但是互不影响。通常为了提高运行效率,HDFS的节点和Node Manager在同一节点上,这样执行任务时只需要像数据在本地一样从本机读取数据执行。在日常使用中,通常使用简称,如下:
- RM :ResourceManager
- AM :ApplicationMaster
- NM :NodeManager
HDFS、Mapreduce计算模型、Yarn调度框架就是常说的Hadoop三大组件。
Hadoop生态
Hadoop的诞生极大推动了大数据的发展,然而即实际应用来说只用HDFS和写MR效率很低,并不能解决全部问题。为此围绕Hadoop,开发各种各样的组件,这里挑选目前最常用的几个简要介绍如下:
-
Flume
日志采集系统,支持不同数据源(Source)采集后发送到不同的接收器(Sink)上,如HDFS、Kafka等
-
Hive
提供类似SQL的HQL,可以类似数据库建表,数据分析人员直接编写SQL语句来分析数据,Hive引擎会将SQL编译成MR任务,但是只能查询不能修改数据,可以理解为一种数据仓库工具
-
HBase
一个大型的分布式数据库,Google Bigtable的开源实现,列式存储
-
Cassandra
类似HBase,更加易用,提供的特性更加灵活
-
Spark
基于Hadoop的新一代计算引擎,相比MapReduce基于磁盘的计算,Spark基于内存,拥有更加高效的DAG计算结构,效率和速度均有较大挺高,支持流式计算(Spark Streaming)在实时计算领域应用越来越广
-
Flink
专注于流式计算的新框架,应用越来越广
本系列教程主要是针对Hadoop基础技术,对于Hive也会涉猎,他山之石可以攻玉,其他的技术或多或少都是基于hadoop系列技术,了解了基础技术再看其他技术相信困难也不会太大。
推荐学习资料
书籍
《hadoop权威指南》 入门和提高都用的上,强烈推荐
源代码解析参考如下三本,有难度
- 《Hadoop技术内幕:深入解析YARN架构设计与实现原理》
- 《Hadoop技术内幕:深入解析Hadoop Common和HDFS架构设计与实现原理》
- 《Hadoop技术内幕:深入解析MapReduce架构设计与实现原理》
视频
- 段海涛 功力比较深厚,对于原理解析图示非常清楚,但是混杂了很多细节,建议有一定基础再看。链接: https://pan.baidu.com/s/10pxxysTJCJ9Q_NPerYJfNg 提取码: yqga
- 尚学堂https://www.bjsxt.com/dashujushipin.html 比较系统,可以对比《hadoop权威指南》学习
文档
英文没问题的话,官方文档https://hadoop.apache.org/docs/ 对于理解基本原理和快速上手MR是非常好的,深入理解不太合适
原创,转载请注明来自