Linux中sed,gawk的使用
网上有关sed的介绍:
1.sed:Stream Editor文本流编辑,sed是一个“非交互式的”面向字符流的编辑器。能同时处理多个文件多行的内容,可以不对原文件改动,把整个文件输入到屏幕,可以把只匹配到模式的内容输入到屏幕上。还可以对原文件改动,但是不会再屏幕上返回结果。
2.sed 是一个比较古老的,功能十分强大的用于文本处理的流编辑器,加上正则表达式的支持,可以进行大量的复杂的文本编辑操作。sed 本身是一个非常复杂的工具,有专门的书籍讲解 sed 的具体用法,但是个人觉得没有必要去学习它的每个细节,那样没有特别大的实际意义。网上也有很多关于 sed 的教程,内容基本覆盖了 sed 的大部分的知识点。文中的内容比较简练,加以实际示例来帮助去理解 sed 的使用。
3.与vim等编辑器不同,sed 是一种非交互式编辑器(即用户不必参与编辑过程),它使用预先设定好的编辑指令对输入的文本进行编辑,完成之后再输出编辑结构。sed 基本上就是在玩正则模式匹配,所以,玩sed的人,正则表达式一般都比较强。
4.sed工作原理 :读取文件的一行,存入模式空间,然后进行所有子命令的处理,处理完后默认会将模式空间的内容输出打印到标准输出,也就是在屏幕上显示出来,接着清空模式空间的内存,继续读取下一行的内容到模式空间,继续处理,依次循环处理。
5.从程序的角度去看,其实就是sed在工作的时候占用了一些内存空间和地址,sed工作完毕就会把内存释放并归还给操作系统。
6.linux 三剑客命令(grep,sed ,awk)
linux命令行与shell脚本编程大全介绍如下:
sed编辑器会进行一下操作:
- 一次从输入中读取一行数据
- 根据所提供的编辑器命令匹配数据
- 按照命令修改流中的数据
- 将新的数据输出到STDOUT
在流编辑器将所有命令与一行数据匹配完毕后,它会读取下一行数据并重复这个过程,在流编辑器处理完所有数据行后,它就会终止。这样比交互式编辑器快得多。
在命令行定义编辑器命令

s命令,用TEST替换test,结果立刻显示出来。直接将数据通过管道输入sed编辑器进行处理。
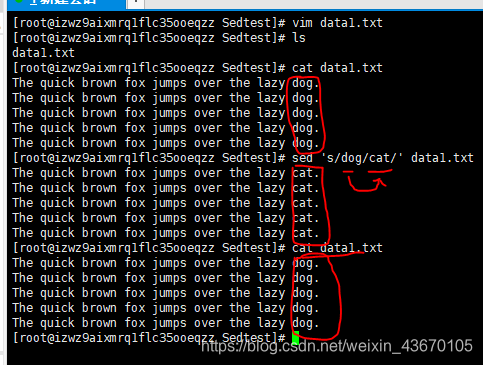
使用sed将文本中所有的dog换成cat,sed编辑器并不会修改原始本文数据,只会讲修改后的数据发送到STDOUT。
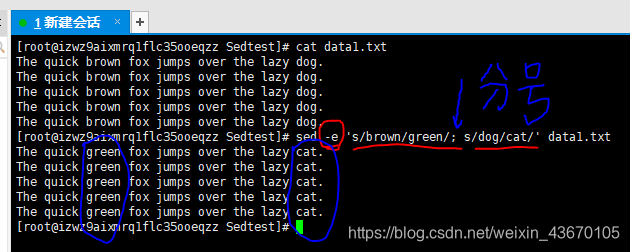
多个编辑器命令:需要用到选项 -e,命令之间用分号隔开。
另一种写法:从提示符
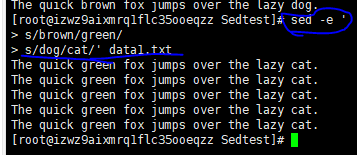
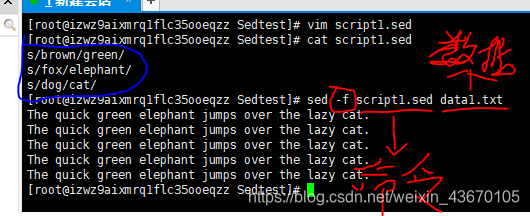
从文件中读取编辑器命令
如果有大量的sed命令,可以将他们单独放置在一个文件中 用到-f命令
更多的替换选项 s -> substitude
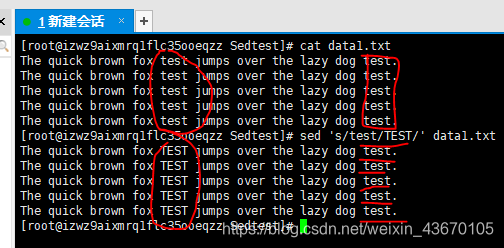
我们发现每次只替换每行的第一处test。
这样必须使用替换标记
有四种标记
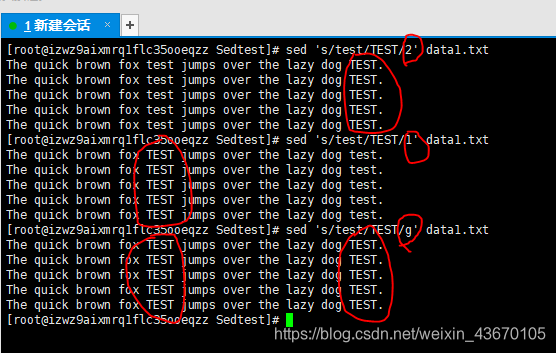
- 数字 数字代表第几处
- g 替换所有匹配的文本
- p原先行的内容打印出来
- w file 将替换的结果写入到文件中
sed -n 's/test/TEST/p' data1.txt
-n选项将禁止sed编辑器输出,但p会标记输出修改过的行,将二者配合使用的效果就是只输出被替换命令修改过的行。
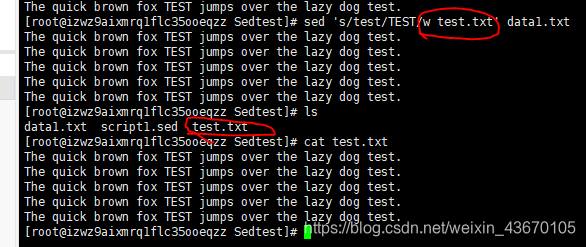
w标记回产生同样的输出,不过会将输出保存到指定的文件中。
使用地址
默认情况,sed使用的命令会作用于文本数据的全部行,如果只想作用于特定行或者某些行,则必须使用行寻址。
- 数字形式表示行区间
sed '数字s/被替换的/替换的/ 文本名' - 用文本模式过滤出行
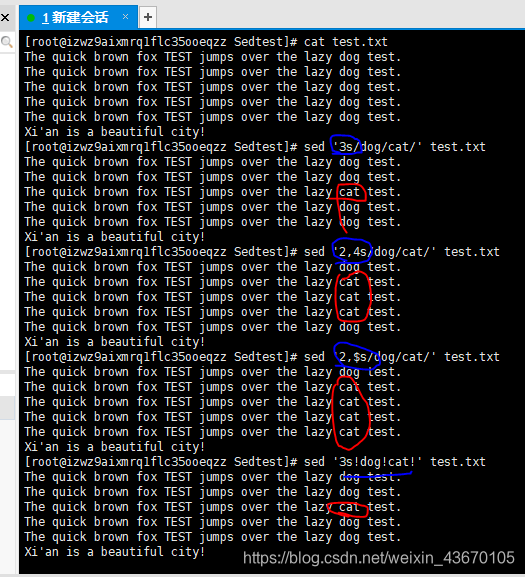
sed允许用其他字符串来代替字符串分隔符,比如用!来分割
上图:
3s 替换第三行
2,4s 替换第2至4行
2,$s 替换第2行至最后一行
文本匹配如下图:
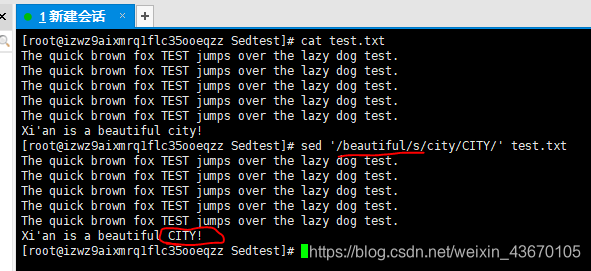
使用beautiful来匹配原文本,将命令作用于被匹配的那一行。
'/匹配的字符串/s/被替换的/替换的/ 文本名'
下面介绍 增 删 改 查
删除命令:删除文本流中的特定行 命令 d
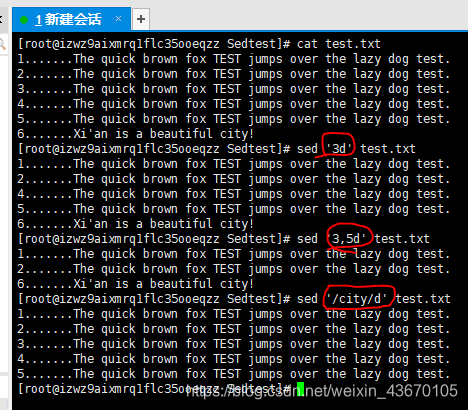
可以使用两个文本模式删除某个区间内的行****但这里请注意一点
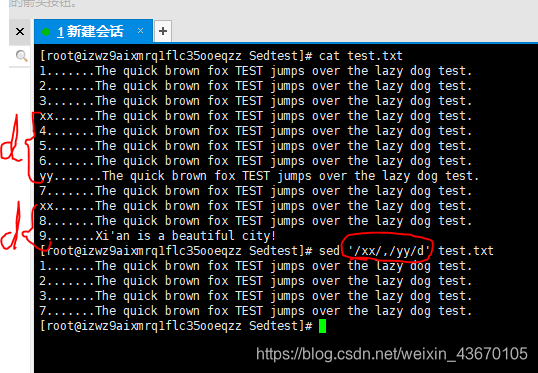
'/xx/,/yy/d' 删除匹配到的xx和yy之间包括xx,yy的行
当匹配到xx时编辑器会**打开行删除功能**,匹配到yy时会**关闭删除功能**
上图程序中,第二次遇到xx时开始删除,但没有yy,也就没有匹配到结束模式,所以后面的数据流都会被删除。
插入和附加文本
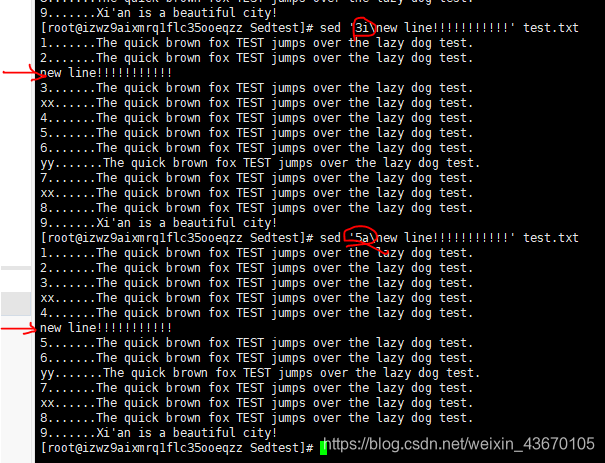
插入(insert) 命令i会在指定的行的前面增加一个新行
附加(append) 命令a会在指定的行的后面增加一个新行
sed '3i/新的行的内容' 文本名
sed '3a/新的行的内容' 文本名
修改行change:修改数据流中整行文本的内容。 必须在sed命令中单独指定新行
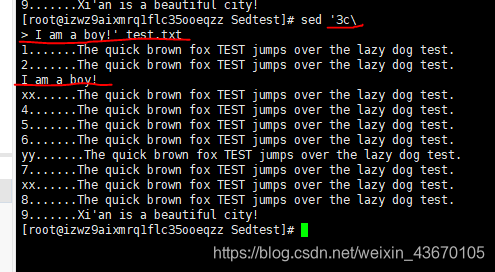
sed '3c/新的整行文本' 数据流
也可以使用匹配
转换命令 y:唯一一个可以处理单个字符的命令,一一对应

1->5
2->6
3->7
4->8
一对一映射,且两边字符的长度要相同。
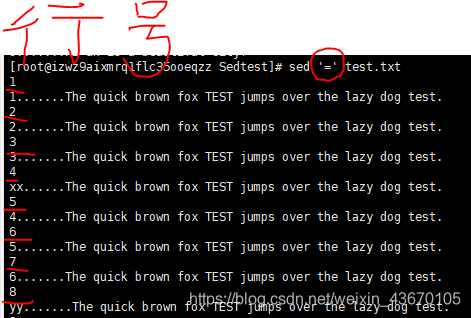
打印行号 sed '=' 文件名
gawk用法
gawk处理文件中的数据的更高级的工具,它提供一个类编程环境来修改和重新组织文件中的数。
gawk是Unix中原始awk程序的GNU版本,它提供一种编程语言而不只是编辑器命令。
可以完成下面的事情:
(1)定义变量来保存数据;
(2)使用算数和字符串操作符来处理数据;
(3)使用结构化编程概念(比如if-then语句和循环)来为数据处理增加处理逻辑;
(4)通过提取数据文件中的数据元素,将其重新排列或格式化,生成格式化报表;
gawk程序及脚本用一对花括号{}来定义。你必须将命令放到两个花括号“{}”中。如果你错误的使用了圆括号来包含gawk脚本,就会出错。
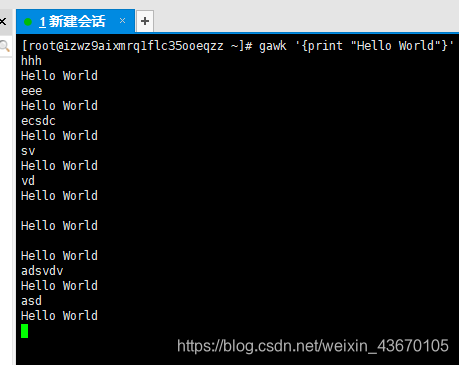
运行这个命令,你可能会有些失望,因为什么都不会发生。原因在于没有在命令行上指定文件名,所有gawk程序会从STDIN接受数据。在运行这个程序时,它会一直等待从STDIN输入的文本。
如果你输入一行文本并按下回车键,gawk会对这行文本运行一遍程序脚本。跟sed编辑器一样,gawk程序会针对数据流中的每一行文本执行程序。由于程序脚本被设为显示一行固定的文本字符串,因此不管你在数据流中输入什么文本,都会得到同样的文本输出。
使用数据字段变量
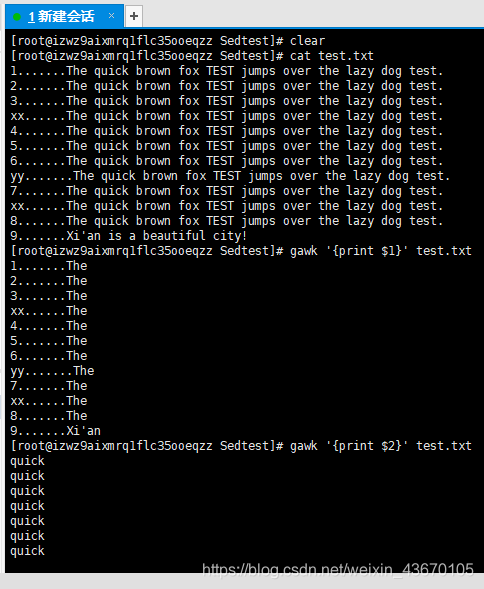
gawk的主要特征之一是其处理文本文件中数据的能力。它会自动给一行的每个数据元素分配一个变量。默认情况下,gawk会将如下变量分配给它在文本中发现的数据字段:
$0 代表整个文本行
$1 代表文本行的第一个数据段
$2 代表文本行的第二个数据段
$n 代表文本行的第n个数据段
在文本行中,每个数据段都是通过字段分隔符划分的。gawk在读取一行文本时,会用预定义的字段分隔符划分每个字段。gawk中默认的字段分隔符是任意的空白字符(例如空格或者制表符)。
例如,用-F指定字段分隔符。显示系统密码文件的第一个数据字段。由于/etc/passwd用冒号来分隔数据字段,因而可以将冒号指定为字段分隔符。
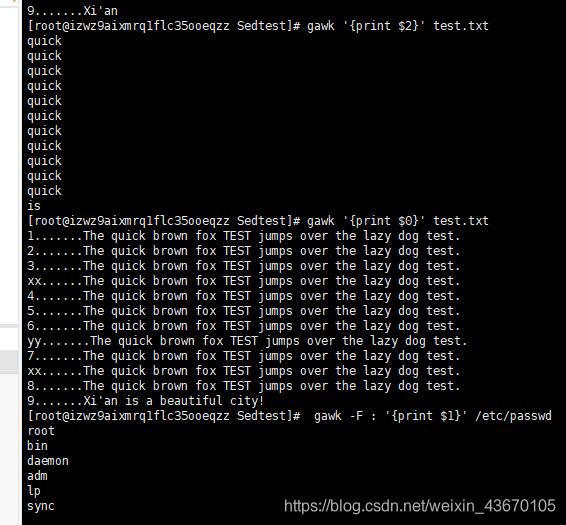
[root@centos7 ~]# gawk -F : '{print $1}' /etc/passwd
root
bin
daemon
adm
lp
sync
shutdown
halt
mail
operator
[……]
gawk编程语言允许将多条命令组合成一个正常程序。要在命令行上的程序脚本中使用多条命令,只要在命令之间放个分号即可。
