一、卷积层、池化层的一般设置
1、卷积层
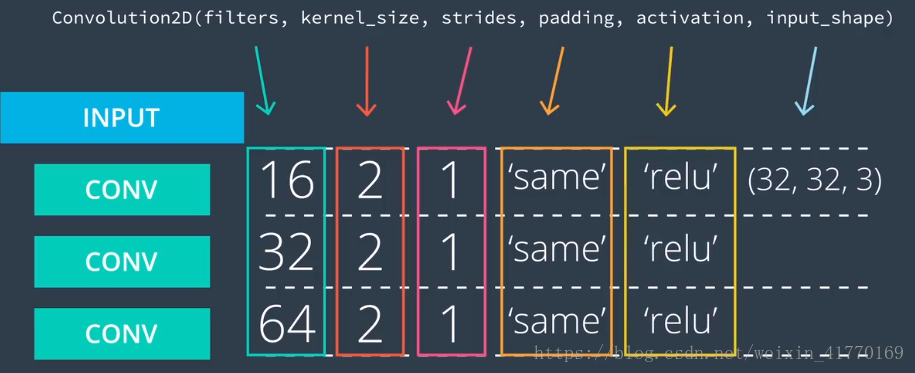
滤波器数量逐渐增加,kernel_size范围2*2~5*5,一般设置为2*2,strides设置为1, padding='same',并在最后添加Relu激活。如果对于第一层,还要增加input_shape。
深度从输入层的3,变成16,再到32,再到64,维度越来越大。深度要更深,于是我们考虑减少宽度、高度。
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
model = Sequential()
model.add(Conv2D(filters=16, kernel_size=2, padding='same', activation='relu', input_shape=(32,32,3)))
model.add(Conv2D(filters=32, kernel_size=2, padding='same', activation='relu', input_shape=(32,32,3)))
model.add(Conv2D(filters=64, kernel_size=2, padding='same', activation='relu', input_shape=(32,32,3)))
model.summary()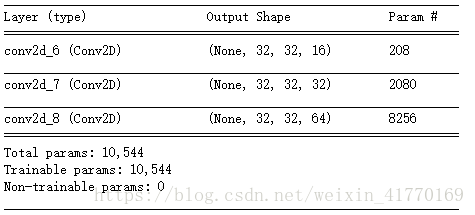
2、池化层
这时,池化层上场。一般设置pool_size=2, stride=2,这样正好pool输出的宽和高都是输入的一半。

from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
model = Sequential()
model.add(Conv2D(filters=16, kernel_size=2, padding='same', activation='relu', input_shape=(32,32,3)))
model.add(MaxPooling2D(pool_size=2))
model.add(Conv2D(filters=32, kernel_size=2, padding='same', activation='relu', input_shape=(32,32,3)))
model.add(MaxPooling2D(pool_size=2))
model.add(Conv2D(filters=64, kernel_size=2, padding='same', activation='relu', input_shape=(32,32,3)))
model.add(MaxPooling2D(pool_size=2))
model.summary()
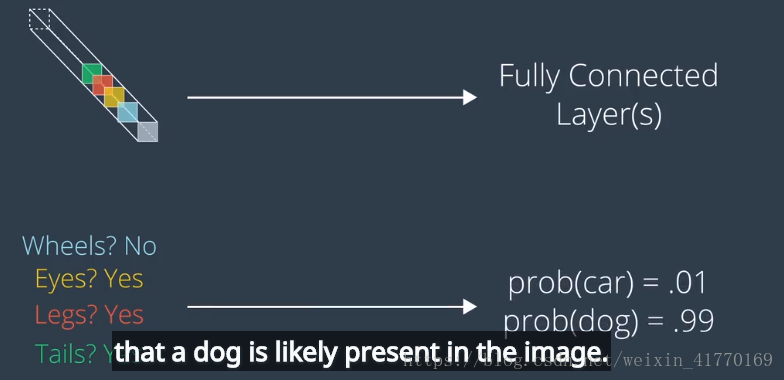
3、扁平,全连接层概率判断
当信息不再具有空间关系,而是变成不同属性,则可以进行扁平,并通过全连接层进行概率预测。
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
model = Sequential()
model.add(Conv2D(filters=16, kernel_size=2, padding='same', activation='relu', input_shape=(32,32,3)))
model.add(MaxPooling2D(pool_size=2))
model.add(Conv2D(filters=32, kernel_size=2, padding='same', activation='relu', input_shape=(32,32,3)))
model.add(MaxPooling2D(pool_size=2))
model.add(Conv2D(filters=64, kernel_size=2, padding='same', activation='relu', input_shape=(32,32,3)))
model.add(MaxPooling2D(pool_size=2))
model.add(Flatten())
model.add(Dense(500, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.summary()
二、CIFAR-10图像库介绍

CIFAR10数据集包含有5万张32*32的训练彩色图,共标记了超过10个分类;还有1万张测试图片。
三、MLP实现CIFAR10图像库分类
1 加载CIFAR10数据库
import keras
from keras.datasets import cifar10
(x_train, y_train),(x_test, y_test) = cifar10.load_data()
print(x_train.shape)
print(x_test.shape)
2 可视化前36幅图像
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
fig = plt.figure(figsize=(20,5))
for i in range(36):
ax = fig.add_subplot(3, 12, i + 1, xticks=[], yticks=[])
ax.imshow(np.squeeze(x_train[i]))
3 归一化
x_train = x_train.astype('float32')/255
x_test = x_test.astype('float32')/2554 切分训练集、验证集、测试集
from keras.utils import np_utils
num_classes = len(np.unique(y_train))
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
(x_train, x_valid) = x_train[5000:], x_train[:5000]
(y_train, y_valid) = y_train[5000:], y_train[:5000]
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train examples')
print(x_valid.shape[0], 'valid examples')
print(x_test.shape[0], 'test examples')
5 定义模型
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
model = Sequential()
model.add(Flatten(input_shape = x_train.shape[1:]))
model.add(Dense(1000, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(num_classes, activation='softmax'))
model.summary()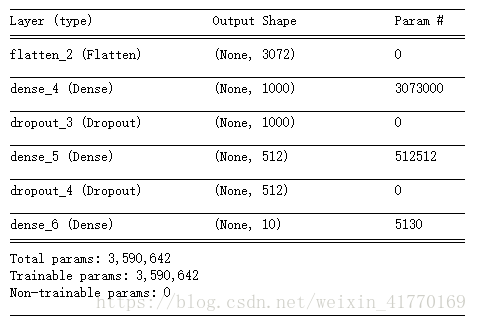
6 编译模型
model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])7 训练模型
from keras.callbacks import ModelCheckpoint
checkpoint = ModelCheckpoint(filepath='MLP.weights.best.hdf5', verbose=1, save_best_only=True)
hist = model.fit(x_train, y_train, batch_size=32, epochs=20, validation_data=(x_valid, y_valid), callbacks=[checkpoint],
verbose=2, shuffle=True)


多个epoch,通过checkpoint选择validation_error最小的epoch时的模型参数。就是下面的意图:
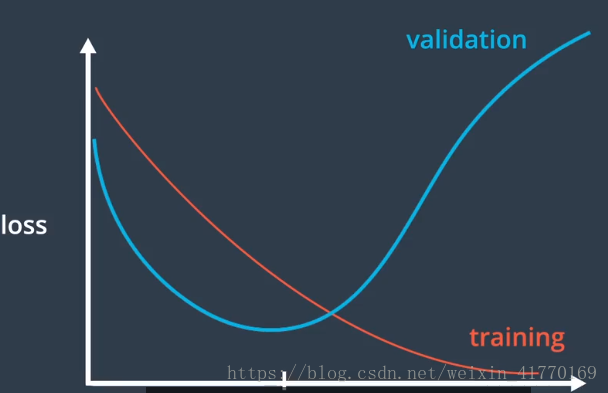
8 加载在验证集上分类正确率最高的一组模型参数
model.load_weights('MLP.weights.best.hdf5')9 测试集上计算分类正确率
score = model.evaluate(x_test, y_test, verbose=0)
print('\n', 'Test accuracy:', score[1])
我们看到,MLP的正确率只有40%,接下来看看CNN可以达到多少。
四、CNN实现CIFAR10图像库分类
1-9个步骤中,就第5步不一样,另外新增了第10个步骤可视化。
1 加载CIFAR10数据库
import keras
from keras.datasets import cifar10
(x_train, y_train),(x_test, y_test) = cifar10.load_data()
2 可视化前36幅图像
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
fig = plt.figure(figsize=(20*5))
for i in range(36):
ax = fig.add_sbuplot(3, 12, i+1, xticks=[], yticks=[])
ax.imshow(np.squeeze(x_train[i]))3 归一化
x_train = x_train.astype('float32')/255
x_test = x_test.astype('float32')/2554 切分训练集、验证集、测试集
from keras.utils import np_utils
num_classes = len(np.unique(y_train))
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
(x_train, x_valid) = x_train[5000:], x_train[:5000]
(y_train, y_valid) = y_train[5000:], y_train[:5000]
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train examples')
print(x_valid.shape[0], 'valid examples')
print(x_test.shape[0], 'test examples')5 定义模型
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
model = Sequential()
model.add(Conv2D(filters=16, kernel_size=2, padding='same', activation='relu', input_shape=(32,32,3)))
model.add(MaxPooling2D(pool_size=2))
model.add(Conv2D(filters=32, kernel_size=2, padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(Conv2D(filters=64, kernel_size=2, padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(Dropout(0.3))
model.add(Flatten())
model.add(Dense(500, activation='relu'))
model.add(Dropout(0.4))
model.add(Dense(num_classes, activation='softmax'))
model.summary()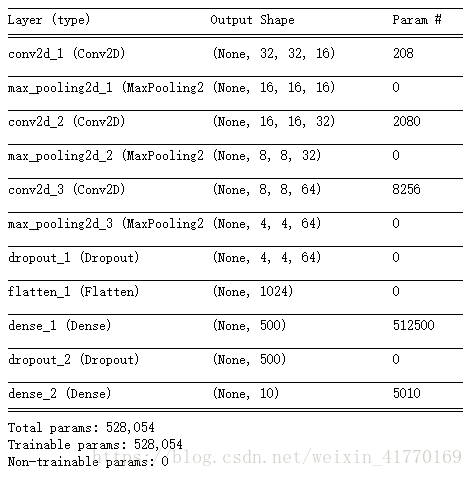
CNN的参数为52万多,而之前MLP有359万多,参数少了1个数量级。
6 编译模型
model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])7 训练模型
from keras.callbacks import ModelCheckpoint
checkpoint = ModelCheckpoint(filepath='MLP.weights.best.hdf5', verbose=1, save_best_only=True)
hist = model.fit(x_train, y_train, batch_size=32, epochs=20, validation_data=(x_valid, y_valid), callbacks=[checkpoint],
verbose=2, shuffle=True)


可以看到,每个epoch的运算速度比之前快了1倍。
8 加载在验证集上分类正确率最高的一组模型参数
model.load_weights('MLP.weights.best.hdf5')9 测试集上计算分类正确率
score = model.evaluate(x_test, y_test, verbose=0)
print('\n', 'Test accuracy:', score[1])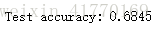
测试准确率比之前的40%多提高了接近50%,当然还可以通过修改参数来优化网络结构。
10 可视化部分预测
y_hat = model.predict(x_test)
cifar10_labels = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']fig = plt.figure(figsize=(20, 8))
for i, idx in enumerate(np.random.choice(x_test.shape[0], size=32, replace=False)):
ax = fig.add_subplot(4, 8, i + 1, xticks=[], yticks=[])
ax.imshow(np.squeeze(x_test[idx]))
pred_idx = np.argmax(y_hat[idx])
true_idx = np.argmax(y_test[idx])
ax.set_title("{} ({})".format(cifar10_labels[pred_idx], cifar10_labels[true_idx]),
color=("green" if pred_idx == true_idx else "red"))
五、kaggle竞赛最优结果,正确率达到95%以上
2015年,GPU训练时间:90小时,测试正确率:95%以上