需要解决的:
- 如何为每个数据块分配一个Map计算任务,也就是代码是如何发送到数据块所在的服务器上面的,发送后如何启动的,启动之后如何知道自己需要计算的数据在文件什么位置(BlockID是什么)。
- 处于不同服务器的map输出的<key,value>,如何把相同的key聚合在一起发送给Reduce任务处理。

作业启动和运行 数据合并和连接


MapReduce 的主服务器就是 JobTracker,从服务器就是 TaskTracker
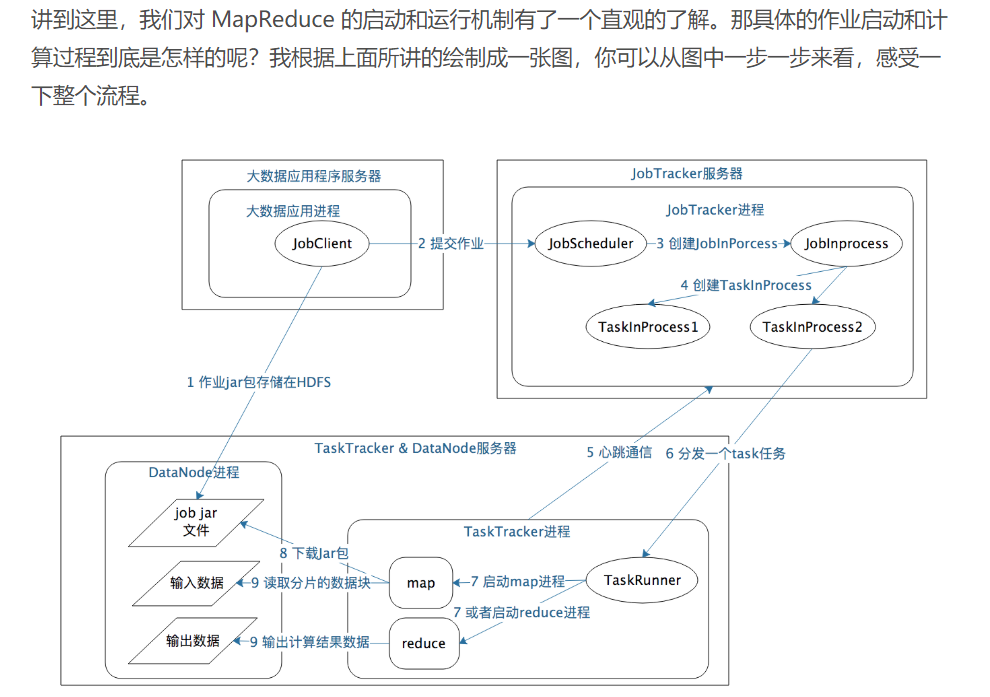
计算过程的旅行:
1.应用进程JobClient将用户作业JAR包储存在HDFS中,将来这些jar包会分发到Hadoop集群中的服务器质性MapReduce计算; 2.应用程序提交job作业给jobTracker; 3.JobTracker 根据作业调度策略创建 JobInProcess 树,每个作业都会有一个自己的 JobInProcess 树; 4.JobInProcess 根据输入数据分片数目(通常情况就是数据块的数目)和设置的Reduce数目创建相应数量的TaskInProcess; TaskTracker进程和JobTracker进程进行定时通信 6.如果 TaskTracker 有空闲的计算资源(有空闲 CPPU 核心),JobTracker 就会给它分配任务,分配任务的时候会根据 TaskTracker 的服务器名字匹配在同一台机器上的数据块计算任务给它,使启动的计算任务正好处理本机上的数据,以实现我们一开始就提到的“移动计算比移动数据更划算“ 7.TaskTracker 收到任务后根据任务类型(是 Map 还是 Reduce)和任务参数(作业 JAR 包路径、输入数据文件路径、要处理的数据在文件中的起始位置和偏移量、数据块多个备份的DataNode 主机名等),启动相应的 Map 或者 Reduce进程 8.Map 或者 Reduce 进程启动后,检查本地是否有要执行任务的 JAR 包文件,如果没有,就去HDFS 上下载,然后加载 Map 或者 Reduce 代码开始执行 9.如果是 Map 进程,从 HDFS 读取数据(通常要读取的数据块正好存储在本机);如果是Reduce 进程,将结果数据写出到 HDFS

/** Use {@link Object#hashCode()} to partition. */ public int getPartition(K2 key, V2 value, int numReduceTasks) { return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; }
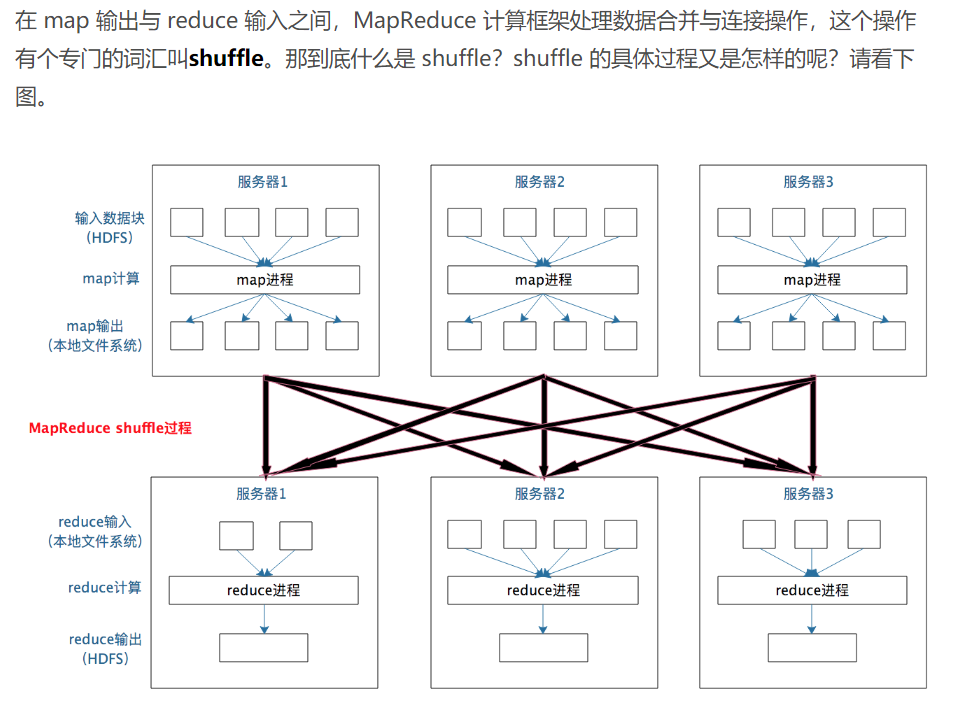
分布式计算需要将不同服务器上的相关数据合并到一起进行下一步计算,这就是 shuffle
mapper计算完的结果要放到硬盘呢?那再发送到reducer不是还有个读取再发送的过程吗?这中间不就有一个重复的写和读的过程吗?
作者回复: 是的,主要为了可靠性,spark就不写硬盘,所以快。
当某个key聚集了大量数据,shuffle到同一个reduce来汇总,考虑数据量很大的情况,这个会不会把reduce所在机器节点撑爆?这样任务是不是就失败了?
作者回复: 会的,数据倾斜,会导致任务失败。严重的数据倾斜可能是数据本身的问题,需要做好预处理
移动计算主要是map阶段,reduce阶段数据还是要移动数据合并关联