MapReduce原理可以用一个成语概括“分而治之”,Map端主要进行数据转换、清洗,Reduce端进行具体的计算。官方描述的过程如下所示。
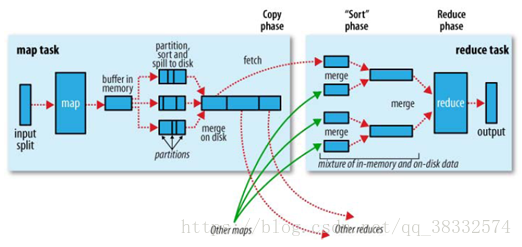
所有的数据都是存储在hdfs上,是一个个的block块。Map端输入block数据块,经过接口InputFormat类(jave的一个类),主要有两个功能对block数据块进行split(也解决了一个跨block的问题)和用record记录物理块,即数据分割Data Splits,另一功能是RecordReader记录的读取,方便调用map函数时先执行记录的读取,将map和记录的数据串起来,再执行map函数(该函数是需要我们自己开发的)。map出来的数据(key,value)会存储在buffer in memory内存中,在这里会有一个partition,对key进行hash取模,所以buffer in memory中的数据是三元组的形式(partition,key,value),buffer in memory的大小一般为100M,当达到阈值80%时,会将这80%的数据锁住,通过溢写线程对这部分数据溢写,写出来的位置都是在map所在进程的物理机的本地磁盘上;还会存在另外一个从map到缓存区的线程,主要负责缓存区中剩余20%数据的写操作,所以最后一个文件可能不足80M。在buffer in memory中还会执行一次Combiner 、sort对key排序的操作,对同一个key进行合并(相同的key提前执行一次reduce,这样写出的数据就会减少,合并的过程中产生的数据量会变小,整个网络传输的数据量就会降低,缩短了传输时间),之后对这些文件相同的partition进行merge合并,最终生成如图所示的map阶段的大文件,其他的map也会进行相同的操作。
Reduce端在reducetask执行之前的工作就是不断地拉取每个map task的最终结果,即copy过程,reduce进程会启动数据的copy线程(fetcher),通过HTTP方式请求map端的输出文件。然后对从不同地方拉取过来的数据不断地做merge,即merge阶段,Copy过来的数据会先放入buffer in memory内存缓冲区中,同map阶段的内存缓冲区一样,满80%之后开始写出文件。merge的三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。默认情况下第一种形式不启用,当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。这个过程中若设置Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的文件。不断地merge后,最后会生成一个“最终文件”。该文件可能存在于磁盘上,也可能存在于内存中。默认情况下,这个文件是存放于磁盘中的。最后执行Reducer,通过接口OutputFormat类把结果存到HDFS上。
关于Shuffle的理解
从Map输出到Reduce输入的整个过程广义地称为Shuffle过程。包括map端的Shuffle过程和reduce端的Shuffle过程,在Map端包括partition、sort、spill、merge、combiner、disk等,在Reduce端包括copy、memory、sortcombiner过程。