参考文章1:http://www.cnblogs.com/baiboy/p/jieba2.html
参考文章2:https://www.jianshu.com/p/0eee07a5bf38
参考文章3:https://blog.csdn.net/sinat_33741547/article/details/78867039
多篇文章相辅相成,才能更好理解,该篇需要一定的HMM算法原理基础。
1 中文分词介绍
中文分词特点:
-
词是最小的能够独立活动的有意义的语言成分
-
汉语是以字位单位,不像西方语言,词与词之间没有空格之类的标志指示词的边界
-
分词问题为中文文本处理的基础性工作,分词的好坏对后面的中文信息处理其关键作用
中文分词的难点 :
-
分词规范,词的定义还不明确 (《统计自然语言处理》宗成庆)
-
歧义切分问题,交集型切分问题,多义组合型切分歧义等 结婚的和尚未结婚的 => 结婚/的/和/尚未/结婚/的 结婚/的/和尚/未/结婚/的
-
未登录词问题有两种解释:一是已有的词表中没有收录的词,二是已有的训练语料中未曾出现过的词,第二种含义中未登录词又称OOV(Out of Vocabulary)。对于大规模真实文本来说,未登录词对于分词的精度的影响远超歧义切分。一些网络新词,自造词一般都属于这些词。
汉语分词方法:
-
基于字典、词库匹配的分词方法(基于规则) 基于字符串匹配分词,机械分词算法。将待分的字符串与一个充分大的机器词典中的词条进行匹配。分为正向匹配和逆向匹配;最大长度匹配和最小长度匹配;单纯分词和分词与标注过程相结合的一体化方法。所以常用的有:正向最大匹配,逆向最大匹配,最少切分法。实际应用中,将机械分词作为初分手段,利用语言信息提高切分准确率。优先识别具有明显特征的词,以这些词为断点,将原字符串分为较小字符串再机械匹配,以减少匹配错误率,或将分词与词类标注结合。
-
基于词频度统计的分词方法(基于统计) 相邻的字同时出现的次数越多,越有可能构成一个词语,对语料中的字组频度进行统计,基于词的频度统计的分词方法是一种全切分方法。jieba是基于统计的分词方法,jieba分词采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合,对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法。
-
基于知识理解的分词方法。 该方法主要基于句法、语法分析,并结合语义分析,通过对上下文内容所提供信息的分析对词进行定界,它通常包括三个部分:分词子系统、句法语义子系统、总控部分。在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断。这类方法试图让机器具有人类的理解能力,需要使用大量的语言知识和信息。由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式。因此目前基于知识的分词系统还处在试验阶段。
2 结巴分词算法思想
1. 基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG);
作者这个版本中使用前缀字典实现了词库的存储(即dict.txt文件中的内容),而弃用之前版本的trie树存储词库,想想也是,python中实现的trie树是基于dict类型的数据结构而且dict中又嵌套dict 类型,这样嵌套很深,导致内存耗费严重,详情见作者把trie树改成前缀词典的 缘由, 具体实现见 gen_pfdict(self, f_name)。接着说DAG有向无环图, 生成句子中汉字所有可能成词情况所构成的有向无环图。DAG根据我们生成的前缀字典来构造一个这样的DAG,对一个sentence DAG是以{key:list[i,j…], …}的字典结构存储,其中key是词的在sentence中的位置,list存放的是在sentence中以key开始且词sentence[key:i+1]在我们的前缀词典中 的以key开始i结尾的词的末位置i的列表,即list存放的是sentence中以位置key开始的可能的词语的结束位置,这样通过查字典得到词, 开始位置+结束位置列表。
例如:句子“抗日战争”生成的DAG中{0:[0,1,3]} 这样一个简单的DAG, 就是表示0位置开始, 在0,1,3位置都是词, 就是说0~0,0~1,0~3 即 “抗”,“抗日”,“抗日战争”这三个词 在dict.txt中是词。 2. 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合; 基于上面的DAG利用动态规划查找最大概率路径,这个理解DP算法的很容易就能明白了。根据动态规划查找最大概率路径的基本思路就是对句子从右往左反向计算最大概率,..依次类推, 最后得到最大概率路径, 得到最大概率的切分组合(这里满足最优子结构性质,可以利用反证法进行证明),这里代码实现中有个小trick,概率对数(可以让概率相乘的计算变成对数相加,防止相乘造成下溢,因为在语料、词库中每个词的出现概率平均下来还是很小的浮点数). 3. 对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法; 未登录词中说的OOV, 其实就是词典 dict.txt 中没有记录的词。这里采用了HMM模型,HMM是个简单强大的模型,可以参考这个网络资源进行学习,HMM在实际应用中主要用来解决3类问题:
-
a. 评估问题(概率计算问题) :即给定观测序列 O=O1,O2,O3…Ot和模型参数λ=(A,B,π),怎样有效计算这一观测序列出现的概率. (Forward-backward算法)
-
b. 解码问题(预测问题) :即给定观测序列 O=O1,O2,O3…Ot和模型参数λ=(A,B,π),怎样寻找满足这种观察序列意义上最优的隐含状态序列S。 (viterbi算法,近似算法)
-
c. 学习问题 :即HMM的模型参数λ=(A,B,π)未知,如何求出这3个参数以使观测序列O=O1,O2,O3…Ot的概率尽可能的大. (即用极大似然估计的方法估计参数,Baum-Welch,EM算法)
模型的关键相应参数λ=(A,B,π),经过作者对大量语料的训练, 得到了finalseg目录下的三个文件(初始化状态概率(π)即词语以某种状态开头的概率,其实只有两种,要么是B,要么是S。这个就是起始向量, 就是HMM系统的最初模型状态,对应文件prob_start.py;隐含状态概率转移矩A 即字的几种位置状态(BEMS四个状态来标记, B是开始begin位置, E是end, 是结束位置, M是middle, 是中间位置, S是single, 单独成词的位置)的转换概率,对应文件prob_trans.py;观测状态发射概率矩阵B 即位置状态到单字的发射概率,比如P(“狗”|M)表示一个词的中间出现”狗”这个字的概率,对应文件prob_emit.py)。
3 使用Viterbi算法实现中文分词
3.1 模型 HMM的典型模型是一个五元组: StatusSet: 状态值集合 ObservedSet: 观察值集合 TransProbMatrix: 转移概率矩阵 EmitProbMatrix: 发射概率矩阵 InitStatus: 初始状态分布
3.2 基本假设
HMM模型的三个基本假设如下:
有限历史性假设:
P(Status[i]|Status[i-1],Status[i-2],… Status[1]) = P(Status[i]|Status[i-1])
齐次性假设(状态和当前时刻无关):
P(Status[i]|Status[i-1]) = P(Status[j]|Status[j-1])
观察值独立性假设(观察值只取决于当前状态值):
P(Observed[i]|Status[i],Status[i-1],…,Status[1]) = P(Observed[i]|Status[i])
3.3 五元组
3.3.1 状态值集合(StatusSet)
为(B, M, E, S): {B:begin, M:middle, E:end, S:single}。分别代表每个状态代表的是该字在词语中的位置,B代表该字是词语中的起始字,M代表是词语中的中间字,E代表是词语中的结束字,S则代表是单字成词。
如: 给你一个隐马尔科夫链的例子。 可以标注为: 给/S 你/S 一个/BE 隐马尔科夫链/BMMMME 的/S 例子/BE 。/S
3.3.2 观察值集合(ObservedSet) 为就是所有汉字(东南西北你我他…),甚至包括标点符号所组成的集合。 状态值也就是我们要求的值,在HMM模型中文分词中,我们的输入是一个句子(也就是观察值序列),输出是这个句子中每个字的状态值。 3.3.3 初始状态概率分布(InitStatus ) 如:
B -0.26268660809250016 E -3.14e+100 M -3.14e+100 S -1.4652633398537678
数值是对概率值取【对数】之后的结果(可以让概率【相乘】的计算变成对数【相加】)。其中-3.14e+100作为负无穷,也就是对应的概率值是0。
也就是句子的第一个字属于{B,E,M,S}这四种状态的概率。
3.3.4 转移概率矩阵(TransProbMatrix ) 【有限历史性假设】 转移概率是马尔科夫链。Status(i)只和Status(i-1)相关,这个假设能大大简化问题。所以,它其实就是一个4x4(4就是状态值集合的大小)的二维矩阵。矩阵的横坐标和纵坐标顺序是BEMS x BEMS。(数值是概率求对数后的值)
3.3.5 发射概率矩阵(EmitProbMatrix ) 【观察值独立性假设】 P(Observed[i], Status[j]) = P(Status[j]) * P(Observed[i]|Status[j]) 其中,P(Observed[i]|Status[j])这个值就是从EmitProbMatrix中获取。
3.4 使用Viterbi算法
这五元的关系是通过一个叫Viterbi的算法串接起来,ObservedSet序列值是Viterbi的输入,而StatusSet序列值是Viterbi的输出,输入和输出之间Viterbi算法还需要借助三个模型参数,分别是InitStatus, TransProbMatrix, EmitProbMatrix。
以下句子为例:
小明硕士毕业于中国科学院计算所
定义变量
二维数组 weight[4][15],4是状态数(0:B,1:E,2:M,3:S),15是输入句子的字数。比如 weight[0][2] 代表 状态B的条件下,出现’硕’这个字的可能性。
二维数组 path[4][15],4是状态数(0:B,1:E,2:M,3:S),15是输入句子的字数。比如 path[0][2] 代表 weight[0][2]取到最大时,前一个字的状态,比如 path[0][2] = 1, 则代表 weight[0][2]取到最大时,前一个字(也就是明)的状态是E。记录前一个字的状态是为了使用viterbi算法计算完整个 weight[4][15] 之后,能对输入句子从右向左地回溯回来,找出对应的状态序列。
B:-0.26268660809250016 E:-3.14e+100 M:-3.14e+100 S:-1.4652633398537678 且由EmitProbMatrix可以得出 Status(B) -> Observed(小) : -5.79545 Status(E) -> Observed(小) : -7.36797 Status(M) -> Observed(小) : -5.09518 Status(S) -> Observed(小) : -6.2475 所以可以初始化 weight[i][0] 的值如下: weight[0][0] = -0.26268660809250016 + -5.79545 = -6.05814 weight[1][0] = -3.14e+100 + -7.36797 = -3.14e+100 weight[2][0] = -3.14e+100 + -5.09518 = -3.14e+100 weight[3][0] = -1.4652633398537678 + -6.2475 = -7.71276 注意上式计算的时候是相加而不是相乘,因为之前取过对数的原因。 //遍历句子,下标i从1开始是因为刚才初始化的时候已经对0初始化结束了 for(size_t i = 1; i < 15; i++) { // 遍历可能的状态 for(size_t j = 0; j < 4; j++) { weight[j][i] = MIN_DOUBLE; path[j][i] = -1; //遍历前一个字可能的状态 for(size_t k = 0; k < 4; k++) { double tmp = weight[k][i-1] + _transProb[k][j] + _emitProb[j][sentence[i]]; if(tmp > weight[j][i]) // 找出最大的weight[j][i]值 { weight[j][i] = tmp; path[j][i] = k; } } } }
确定边界条件和路径回溯 边界条件如下: 对于每个句子,最后一个字的状态只可能是 E 或者 S,不可能是 M 或者 B。 所以在本文的例子中我们只需要比较 weight[1(E)][14] 和 weight[3(S)][14] 的大小即可。 在本例中: weight[1][14] = -102.492; weight[3][14] = -101.632; 所以 S > E,也就是对于路径回溯的起点是 path[3][14]。 回溯的路径是: SEBEMBEBEMBEBEB 倒序一下就是: BE/BE/BME/BE/BME/BE/S 所以切词结果就是: 小明/硕士/毕业于/中国/科学院/计算/所
这里可以通过理解上文提到的所有,进行分词。
给出原作者的github练习源码:
https://github.com/longgb246/pythonstudy/blob/master/longgb/Algorithm/TextMining/NLP/HMM/HMM.py
以及数据:
https://github.com/longgb246/pythonstudy/tree/master/longgb/Algorithm/TextMining/Data
如果对以上内容还不了解,可以继续往下看,看懂的就可以跳过了!
4、进一步理解Viterbi算法
如果对该算法还不了解,先看一下我上一篇的文章:
梦里寻梦:(六)通俗易懂理解——viterbi算法zhuanlan.zhihu.com
为了进一步理解Viterbi算法的实现,下面将使用一个例子来说明。
维特比算法是基于动态规划思想的隐马尔科夫模型解法。动态规划原理提到,假设存在一条最优路径,那么将该路径切分成N段,那么这N段小路径都分别是该环境下的最优路径,否则就存在着其他未知小路径,能组成一个比最优路径还更好的路径,这显然不成立。
基于上述原理,我们只需要从时刻t=1开始,递归的计算子安时刻t状态为i的各条部分路径的最大概率,直至得到时刻t=T的状态为i的各条路径的最大概率,便可以得到最优路径。
假设HMM模型,隐藏状态={1,2,3},观测序列={红,白,红},模型参数如下,求解最大概率隐藏状态序列。
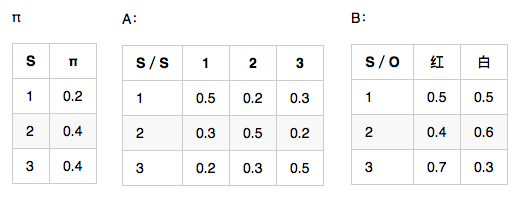
4.1、计算t=1时刻的概率
已知t=1时刻,观测为红,分别计算在在状态1,2,3的条件下得到观测的概率:
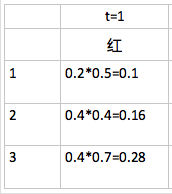
由上图,此时取状态=3时,得到最大局部概率,但是,这个节点并不一定会是最优路径的节点。
4.2、计算t>1时刻的概率
在t=2时刻观测到白,t=3时刻观测到红,分别计算观测概率如下:
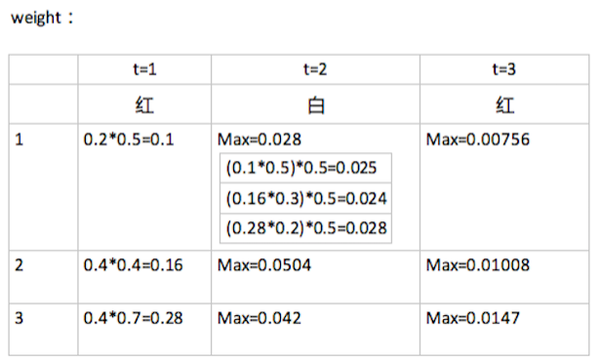
如上图,在t=2时,对于状态s=1,分别计算由t-1时刻的状态s={1,2,3}的局部概率计算得到的t时刻的局部概率,得到最大的t时刻概率,以此类推。其中,0.1*0.5中的0.5来自于隐藏状态1转移到隐藏状态1的概率,0.16*0.3中的0.3来自于隐藏状态2转移到隐藏状态1的概率,以此类推。
4.3、递归结束
在t=3时刻,可以得到最大概率p=0.0147,此时可以得到最优路径的终点是i_3 = 3.
4.4、回溯最优路径
由最优路径的终点3开始,向前找到之前时刻的最优点:
(1)在t=2时刻,因为i_3 = 3,状态3的最大概率来源于状态3(上图没有显示出来,但可以参考状态1的计算过程)
(2)在t=1时刻,因为i_2 = 3,也可以得到最大概率来源于状态3
最后得到最优路径为(3,3,3)