这是一系列深度学习的介绍,本文不会涉及公式推导,主要是一些算法思想的随笔记录。
适用人群:深度学习初学者,转AI的开发人员。
编程语言:Python
参考资料:吴恩达老师的深度学习系列视频
吴恩达老师深度学习笔记整理
深度学习500问
唐宇迪深度学习入门视频课程
笔记下载:深度学习个人笔记完整版
图像分类
图片分类问题已经并不陌生了,例如,输入一张图片到多层卷积神经网络,它会输出一个特征向量,并反馈给softmax单元来预测图片类型。
目标定位 Object Localization
定位分类问题:不仅要用算法判断图片中是不是一辆汽车,还要在图片中标记出它的位置,用边框或红色方框把汽车圈起来。通常只有一个较大的对象位于图片中间位置,我们要对它进行识别和定位。
对象检测问题:图片可以含有多个对象,甚至单张图片中会有多个不同分类的对象。
因此,图片分类的思路可以帮助学习分类定位,而对象定位的思路又有助于学习对象检测。
示例 Example
如果你正在构建汽车自动驾驶系统,那么对象可能包括以下几类:行人、汽车、摩托车和背景,这意味着图片中不含有前三种对象,也就是说图片中没有行人、汽车和摩托车,输出结果会是背景对象,这四个分类就是softmax函数可能输出的结果。
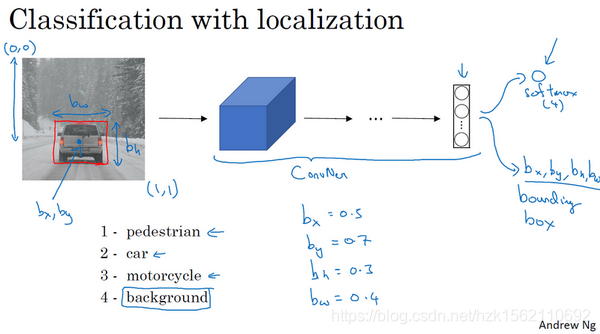
这有四个分类,神经网络输出的是这四个数字和一个分类标签,或分类标签出现的概率。目标标签的定义如下:
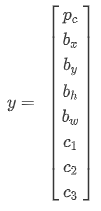
它是一个向量,第一个组件表示是否含有对象,如果对象属于前三类(行人、汽车、摩托车),则,如果是背景,则图片中没有要检测的对象,则。我们可以这样理解,它表示被检测对象属于某一分类的概率,背景分类除外。
损失函数的定义,采用平方误差策略,损失值等于每个元素相应差值的平方和:

特征点检测 Landmark Detection
神经网络可以通过输出图片上特征点的坐标来实现对目标特征的识别。
脸部特征检测、人体姿态检测
需要人工辛苦地标注出来。
目标检测 Object Detection
如何通过卷积网络进行对象检测,采用的是基于滑动窗口的目标检测算法。
滑动窗口目标检测算法也有很明显的缺点,就是计算成本,因为你在图片中剪切出太多小方块,卷积网络要一个个地处理。如果你选用的步幅很大,显然会减少输入卷积网络的窗口个数,但是粗糙间隔尺寸可能会影响性能。反之,如果采用小粒度或小步幅,传递给卷积网络的小窗口会特别多,这意味着超高的计算成本。