版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/QXC1281/article/details/84715774
Hadoop伪集群环境搭建
配置环境变量
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
配置hadoop
配置hadoop-core配置项目 core-site.xml
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000/</value>
<description>默认的HDFS端口,用于NameNode与DataNode之间到的通讯,IP为NameNode的地址</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/BigData/hadoop-3.0.0/tmp</value>
<description>存放hadoop文件系统依赖的基本配置</description>
</property>
</configuration>
HDFS设置hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>设置副本数</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/study/hdfs/namenode</value>
<description>设置存放NameNode的文件路径</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/study/hdfs</value>
<description>设置存放DataNode的文件路径</description>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>权限还是不要的好</description>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序</description>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>0.0.0.0:8088</value>
<description>0.0.0.0所有ID都可以访问web页面,默认不可以</description>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>设置资源调度</description>
</property>
</configuration>
格式化namenode
hadoop namenode -format
配置域名
vim /etc/hosts
添加
127.0.0.1 master
启动
启动命令
start-all.sh
sbin/mr-jobhistory-daemon.sh start historyserver
start-all.sh = start-dfs.sh + start-yarn.sh
start-dfs.sh = hadoop-daemon.sh start namenode + hadoop-daemons.sh start datanode
start-yarn.sh = yarn-daemon.sh start resourcemanager + yarn-daemons.sh start nodemanager
启动历史服务器
sbin/mr-jobhistory-daemon.sh start historyserver
HDFS页面

yarn页面
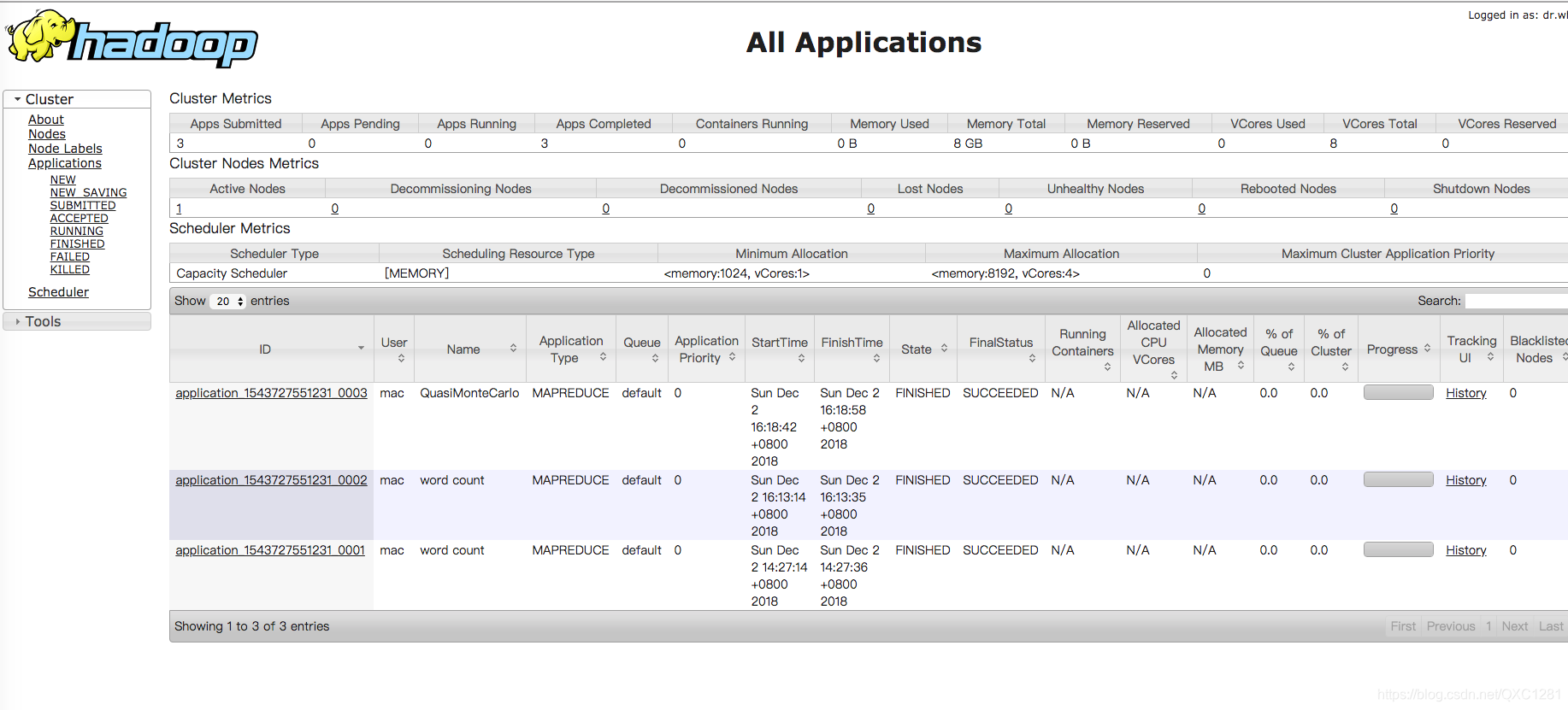
提交作业
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar pi 5 10

注意事项
MAC开启ssh
系统偏好->共享->远程登录
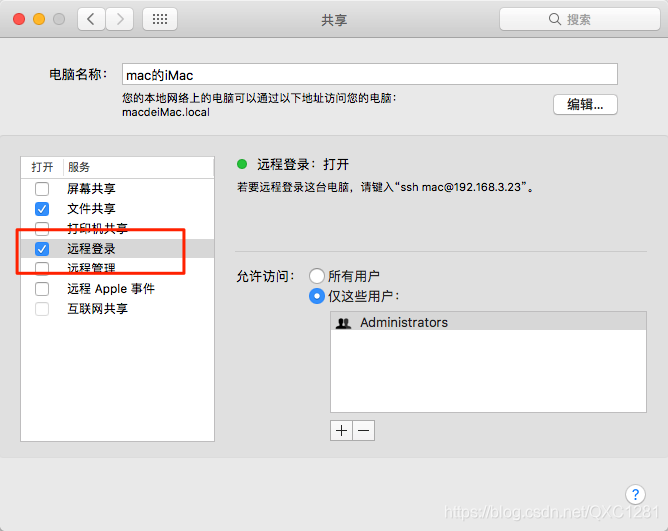
MAC本地ssh免登录
#大家可以copy指令依次执行即可。
ssh-keygen -t rsa
#Press enter for each line 提示输入直接按回车就好
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod og-wx ~/.ssh/authorized_keys
#第四步才是最重要的一步,这一步不做的话每次ssh localhost都会让你输密码,恶心死了。
chmod 750 $HOME