一、Hadoop下载
命令行下载具体的hadoop版本
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.9.2/hadoop-2.9.2.tar.gz
二、Hadoop安装
1、解压
在安装前规划好安装目录,建议安装在 /usr/loacl/hadoop/
解压Hadoop安装包
sudo tar -zxvf hadoop-2.9.2.tar.gz
sudo mv hadoop-2.9.2/ /usr/local/hadoop
2、环境变量
sudo gedit ~/.bashrc
将下面的文本添加至~/.bashrc中,其中javahadoop都以实际目录为准。
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-DJava.library.path=$HADOOP_HOME/lib"
export JAVA_lIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_lIBRARY_PATH
执行完上一步之后,需要将环境变量文件应用,执行下面的命令。
source ~/.bashrc
sudo gedit hadoop-2.9.2/etc/hadoop/hadoop-env.sh
修改文件中JDK环境变量。
3、Hadoop配置文件
下面的修改都是在配置文件的configuration便签中添加下面的内容
sudo gedit hadoop-2.9.2/etc/hadoop/core-site.xml
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property> sudo gedit hadoop-2.9.2/etc/hadoop/yarn-site.xml
// 本句话不要copy,下面两个是单节点部署时需要添加的
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
// 本句话不要copy,在集群部署时,也要把下面几个添加上
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8025</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8050</value>
</property>sudo cp hadoop-2.9.2/etc/hadoop/mapred-site.xml.template hadoop-2.9.2/etc/hadoop/mapred-site.xml
sudo gedit hadoop-2.9.2/etc/hadoop/mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>sudo gedit hadoop-2.9.2/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/datanode</value>
</property>sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode
sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
sudo chown ubuntu:ubuntu -R /usr/local/hadoop
三、集群部署
1、节点Copy
将之前部署的单节点进行clone,分为master、data1、data2、data3四个节点。
2、SSH免密登录设置
先通过命令试试是否已经设置成功。
ssh ubuntu@data1 'mkdir -p .ssh && cat >> .ssh/authorized_keys' < ~/.ssh/id_rsa.pub
ssh ubuntu@data2 'mkdir -p .ssh && cat >> .ssh/authorized_keys' < ~/.ssh/id_rsa.pub
ssh ubuntu@data3 'mkdir -p .ssh && cat >> .ssh/authorized_keys' < ~/.ssh/id_rsa.pub
ssh ubuntu@data1 'chmod 600 .ssh/authorized_keys'
ssh ubuntu@data2 'chmod 600 .ssh/authorized_keys'
ssh ubuntu@data3 'chmod 600 .ssh/authorized_keys'
3、网卡设置
目前只是做单网卡设置,先查询IP和网关信息,再进行安装。
在VMware的编辑菜单中,有个虚拟网络编辑器,打开。

VMnet1仅主机模式(用于虚拟机之间通信)
VMnet8 NAT模式(用于连接外部网络,上网)




将上面截图中的信息都记录下来。
查询节点的动态IP,然后通过VMware改为手工静态地址。


根据信息选择需要配置IP和网关。如下进行配置

将上面的配置完成后,还需要修改几个配置文件
/etc/hostname
里面设置主机名,eg:data1、data2、data3、master
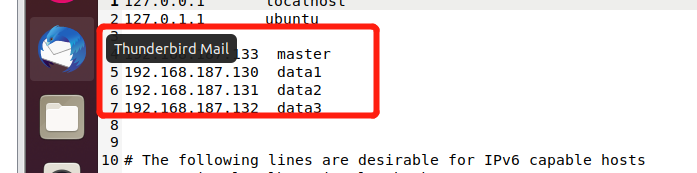
/etc/hosts
192.168.187.133 master
192.168.187.130 data1
192.168.187.131 data2
192.168.187.132 data3
4、配置文件修改
修改几个配置文件后,重新进行hadoop格式化。
hadoop namenode format