提示:如果还不了解Hadoop的,可以下查看这篇文章Hadoop生态系统,通过这篇文章,我们可以首先大致了解Hadoop及Hadoop的生态系统中的工具的使用场景。
搭建一个分布式的hadoop集群环境,下面是详细步骤,使用cdh5 。
一、硬件准备
基本配置:
| 操作系统 |
64位 |
| CPU |
(英特尔)Intel(R) I3处理器 |
| 内存 |
8.00 GB ( 1600 MHz) |
| 硬盘剩余空间 |
50G |
流畅配置:
| 操作系统 |
64位 |
| CPU |
(英特尔)Intel(R) I5处理器或以上配置 |
| 内存 |
16.00 GB ( 1600 MHz) |
| 硬盘剩余空间 |
100G |
注意:上面是在单个pc机上搭建集群,所以对内存要求较高。若是在多台pc机上搭建集群环境,则只需要内存足够即可。
二、软件环境准备
这篇文章是搭建CDH5集群环境,以上软件可以在此网址下载
三、主机规划
由于我们要安装5个节点的集群环境,所以我们分配好ip地址和主机功能
| |
CDHNode1 /192.168.3.188 |
CDHNode2 /192.168.3.189 |
CDHNode3 /192.168.3.190 |
CDHNode4 /192.168.3.191 |
CDHNode5 /192.168.3.192 |
| namenode |
是 |
是 |
否 |
否 |
否 |
| datanode |
否 |
否 |
是 |
是 |
是 |
| resourcemanager |
是 |
是 |
否 |
否 |
否 |
| journalnode |
是 |
是 |
是 |
是 |
是 |
| zookeeper |
是 |
是 |
是 |
否
|
否
|
注意:Journalnode和ZooKeeper保持奇数个,最少不少于 3 个节点。具体原因,以后详叙。
我的主机分配情况是在两台pc的虚拟机上安装centos系统,具体分配情况如下:
| |
CDHNode1 |
CDHNode2 |
CDHNode3 |
CDHNode4 |
CDHNode4 |
| PC1 |
是 |
|
是 |
|
|
| PC2 |
|
是 |
|
是 |
是 |
这样分配的原因是为了采用HA时,两台namenode在不同pc上,若有一台pc出现异常,导致一个namenode无法运作,而standy namenode(备用namenode)可以active(激活),而不会影响整个集群的运作。
三、详细安装步骤
我们首先在1个主机(CHDNode1/192.168.3.188)上安装centos6.5操作系统,使用root用户配置网络,创建hadoop用户,关闭防火墙,安装一些必备软件。为记下来的集群软件安装做准备。
CentOS6.5安装
在主机CHDNode1/192.168.3.188,安装CentOS6.5操作系统。详细安装步骤可以查看CentOS安装这篇文章。此处就不再赘叙。
网络配置
1.打开安装好的CentOS虚拟机CDHNode1
2、登录CentOS系统

3.输入ifconfig命令,先查看ip地址
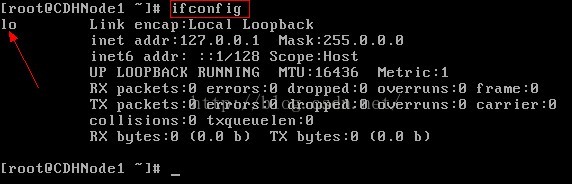
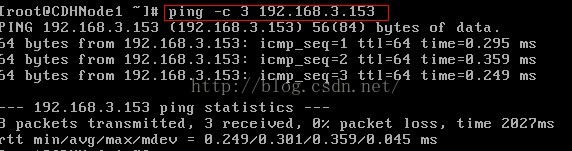
4、这个时候我们发现除了回环地址以外,我们并不能和外界通信,比如我们可以使用ping命令进行测试。
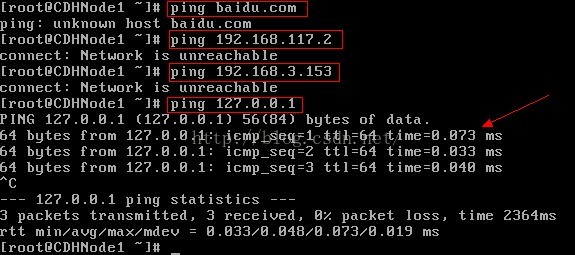
注意:ping 127.0.0.1时,结束icmp报文,使用Ctrl+C命令
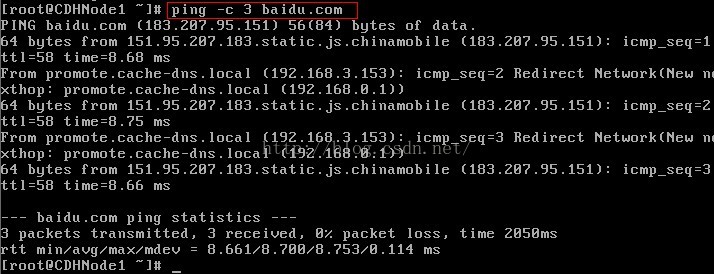
第一次ping 百度,ping不通,说明虚拟机无法连接外网
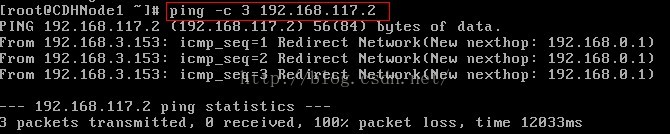
第二次ping 虚拟机NAT网关,ping不通
注:虚拟机网关查看方法
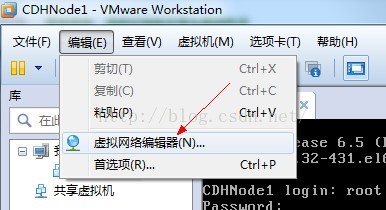
点击虚拟机网络编辑器,点击VMnet8
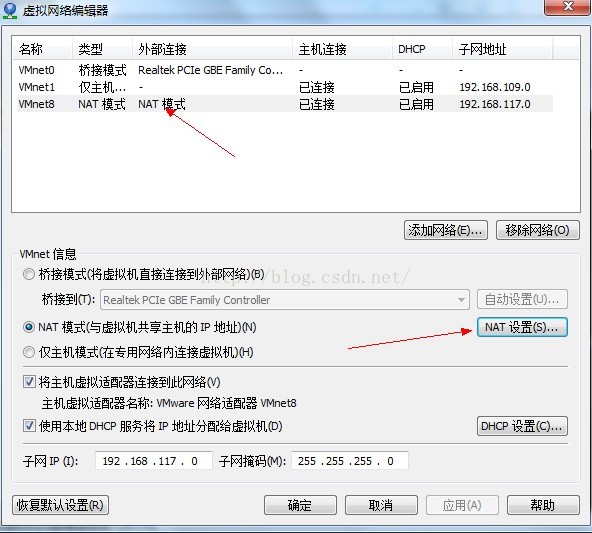
点击Nat设置
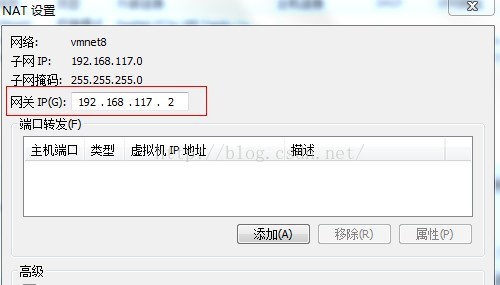
第三次ping物理机ip地址,ping不通
注:查看物理机IP地址,开启cmd.exe ,输入ipconfig
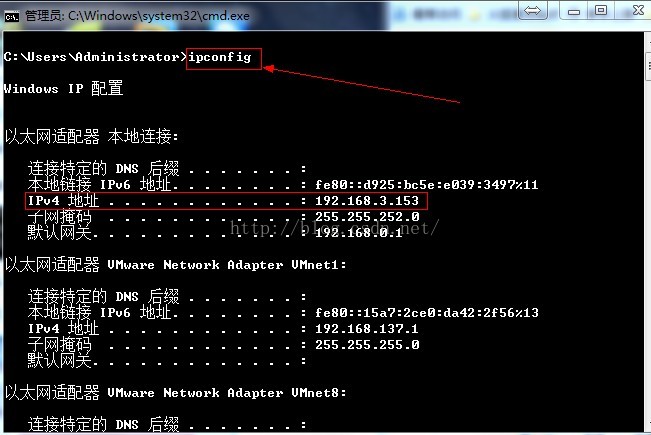
第四次ping虚拟机的回环地址,ping成功,说明虚拟机的网络协议是正确的
5、修改网卡的配置文件

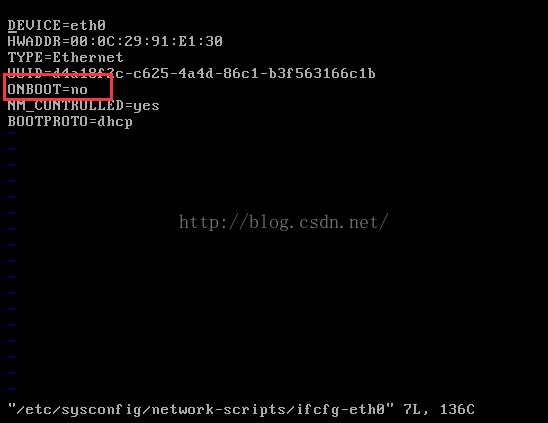
可以看到虚拟机网卡没有开启,因此修改ONBOOT=yes,然后保存退出(按Esc键,然后输入:wq)
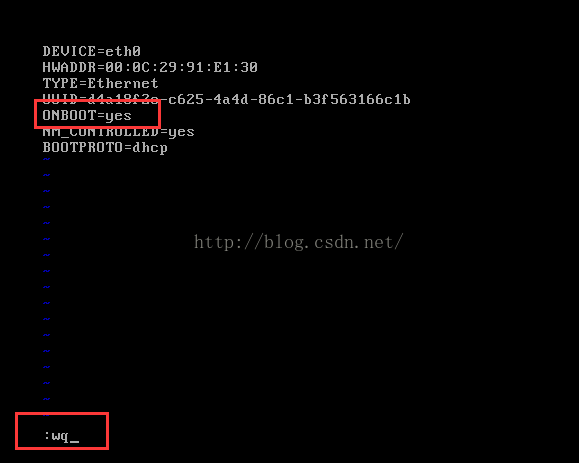
6、重启网络服务
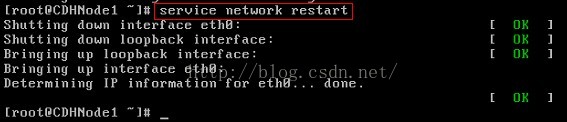
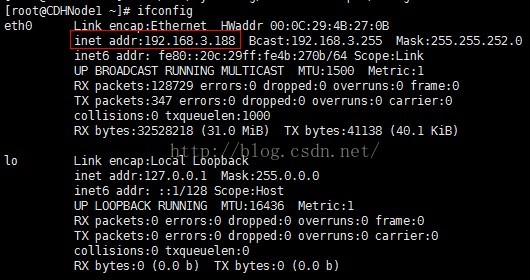
7、再次输入ifconfig命令,查看ip地址。
注意:我的虚拟机设置的是桥接模式,所以ip地址是192.168.2.X网段,或192.168.3.X网段;因为桥接模式是直接使用物理网卡,而我的物理主机的网关是192.168.0.1,子网掩码是255.255.252.0,所以我的虚拟机ip地址可以在192.168.0.2-192.168.3.255之间任意选择(除了物理主机的ip)。若你的虚拟机是使用nat模式,可能就是,如:以我的虚拟机为例,nat网关是192.168.117.2,子网掩码为255.255.255.0,所以虚拟机的ip地址可以在192.168.117.3-192.168.117.255之间任意选择。
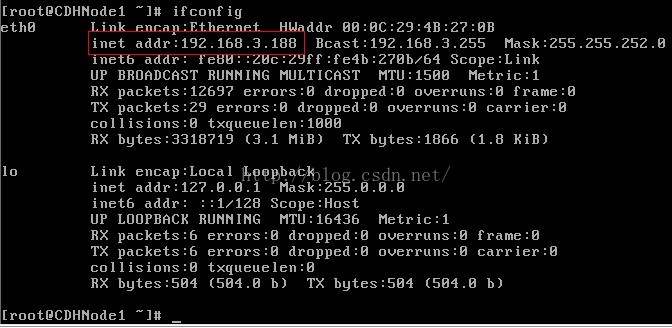
此时网卡已经成功开启。
8.再次ping步骤4的ip或域名,查看具体情况
检查本机网络协议
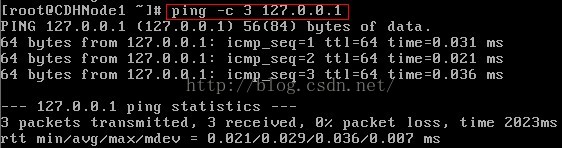
检查网卡链路
检查Nat网关
检查外网
此时虚拟机连接互联网成功,但使用dhcp(动态主机配置协议)配置ip地址,此时的IP地址时动态生成的,不方便以后hadoop集群环境的搭建。所以我们还需要配置静态Ip地址,配置详情,下面细说。
9、使用ifconfig命令可以查看动态ip地址为192.168.3.188,所以接下来我们把此ip作为CDHNode1的静态ip地址。注:你可以使用你的动态ip作为你当前主机的静态ip。然后后面几台IP地址可以紧跟着设置成,如192.168.3.189。DHCP生成ip地址是随机的,你可具体问题具体分析。
10、修改网卡配置信息,把BOOTPROTO=dhcp修改为BOOTPROTO=static,并且添加上设置的ip地址,子网掩码,和网关。

注意:由于我是在两台pc上配置集群环境,所以我使用的是桥接模式。若你是在一台主机上建议你使用Nat(网络地址转换)模式。因为nat模式的网关在不同的电脑上虚拟机VMWare虚拟出来的网段是不同的。不方便使用Xshell连接。
下面是桥接模式的配置,IPADDR是设置ip地址,NETMASK(子网掩码)与GATEWAY(网关)可以设置成与物理主机一样的NETMASK(子网掩码)与GATEWAY(网关)。注:物理主机ip配置具体查看,看上面的步骤4。
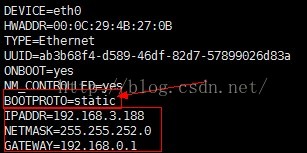
下面是Nat模式的配置,IPADDR是设置ip地址,NETMASK(子网掩码)与GATEWAY(网关)可以设置成与物理主机一样的NETMASK(子网掩码)与GATEWAY(网关)。注:Nat模式ip配置具体查看,看上面的步骤4。
上面步骤中我们可以看到Nat模式的网关是192.168.117.2,子网掩码为255.255.255.0
所以具体可配置成
BOOTPROTO=static
IPADDR=192.168.117.40
NETMASK=255.255.255.0
GATEWAY=192.168.117.2
最后按Esc,然后:wq保存退出。(注意编辑按i或a即可进入编辑模式,具体操作查看vi命令的使用说明)
11、重启网络服务

至此网络配置完毕。
下载必备软件
注:1、在CDHNode1节点上安装,使用yum命令 ,参数-y表示,下载过程中的自动回答yes,有兴趣的话,可以试试不加的情况;install表示从网上下载安装。
2、使用yum命令安装软件必须是root用户。
1、安装lrzsz,可以方便在Xshell上,上传和下载文件,输入rz命令,可以上传文件,sz命令可以从远程主机上下载文件到本地。

2、安装ssh服务器。
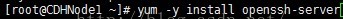
3、安装ssh客户端。

用户创建户
1、使用useradd命令添加用户hadoop,并同时创建用户的home目录,关于useradd的参数使用可以使用 useradd -h查看参数

2、可以切换到/home目录下查看,是否创建成功
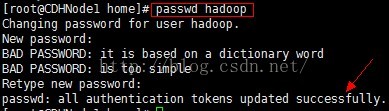
3、为hadoop用户创建密码,这是为了接下来使用XShell软件远程连接CDHNode1节点做准备,出现successfully表示创建密码成功,注意:密码创建必须是root用户。
4、可以切换到hadoop用户,使用 su命令,可以看到,此时root@CDHNode1已经改成hadoop@CDHNode1。

5、从hadoop用户退出,使用exit命令
克隆虚拟机
由于我们使用VMware创建的Centos虚拟机,所以我们可以直接克隆虚拟机,就减少了安装的时间,提高效率。
若你是在一台pc机上配置集群环境,就可以按照以下步骤连续克隆出四个虚拟机分别是CDHNode2、CDHNode3、CDHNode4、CDHNode5;我是在两个pc机上配置的所以,我就需要在另一台pc上重新按照第一台pc机上安装CDHNode1一样,再安装CDHNode2,然后从CDHNode2克隆CDHNode4、CDHNode5。
下面我以在CDHNode2上克隆出CDHNode5虚拟机为例,演示以下克隆的步骤。
1、右键CDHNode2虚拟机--》快照--》拍摄快照
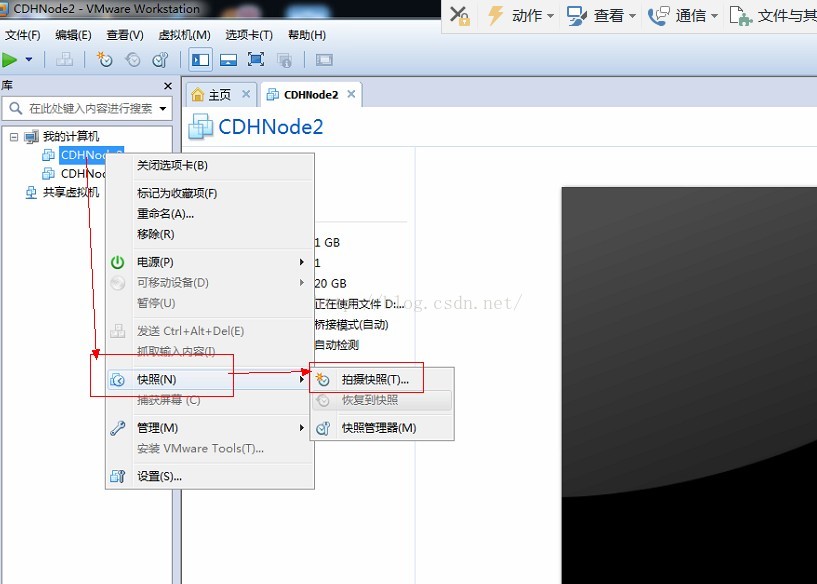
2、点击拍摄快照,快照拍摄成功

3、再右键CDHNode2虚拟机--》管理--》克隆
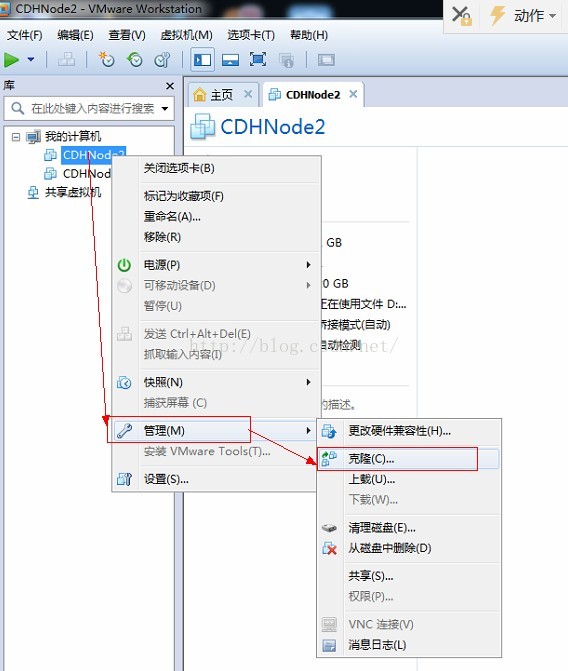
4、下一步
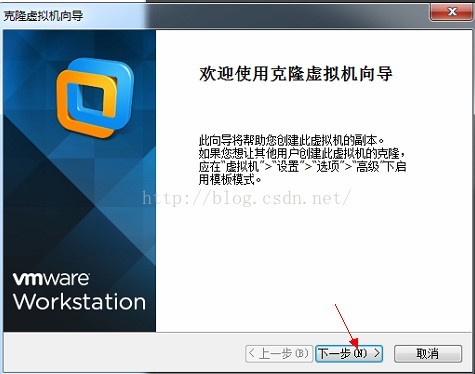
5、选择现有快照--》下一步
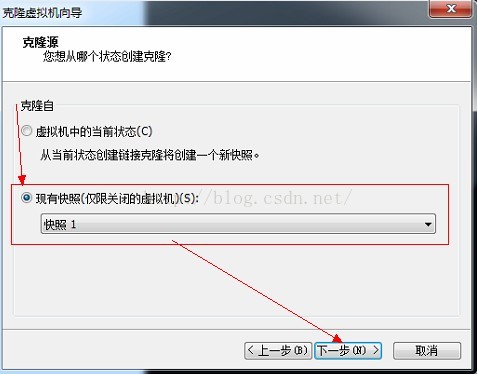
6、选择创建完整克隆--》下一步
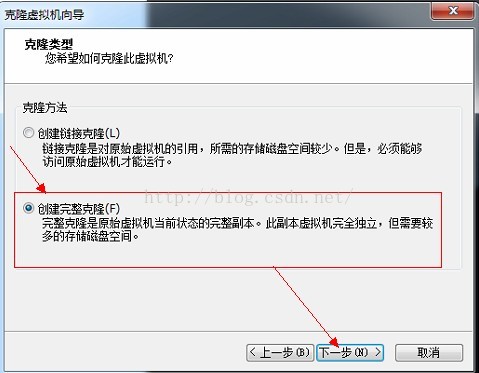
7、输入虚拟机名称,点击完成,等待克隆完成。
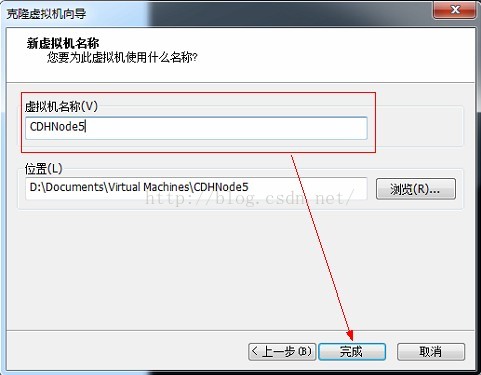
8、至此我们完成了克隆虚拟机的任务
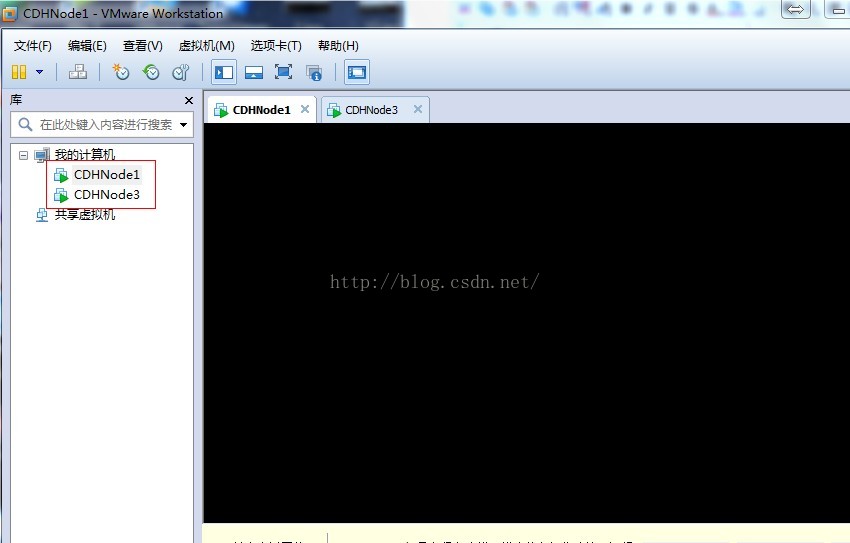
9、接下来是修改配置虚拟机的网卡信息,下面我们在CDHNode5为例,其他节点自己按照下面的自行配置。
首先打开CDHNode5,此时显示的主机名称为CDHNode2,因为CDHNode5是从CDHNode2克隆来的,所以主机名称还是CDHNode2。
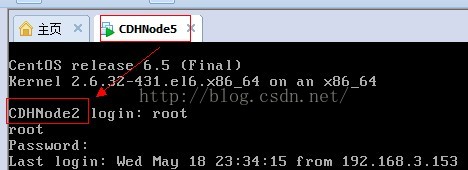
10、暂时不该主机名,我们先查看一下,此时显示没有网卡

11、克隆后的网卡变成了eth1,如果想改回eth0,则需要修改配置文件70-persistent-net.rules配置文件

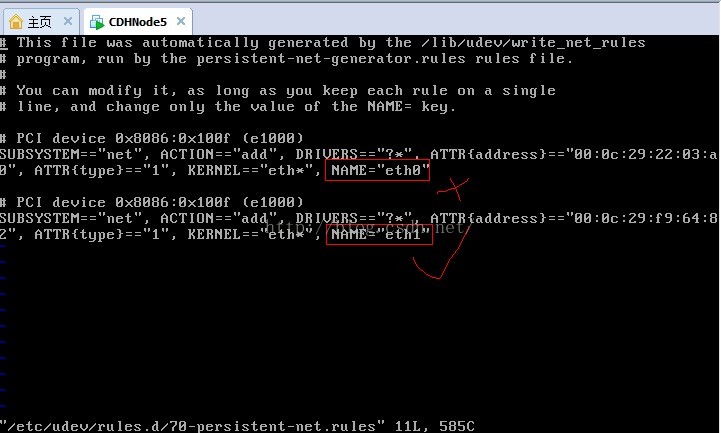
11、我们先设置行号输入:set number,我们需要修改第8行和第11行,然后输入i或a进入编辑模式,使用#注释第8行,并把第10行的eth1改为eth0,可以记一下第二个网卡的mac硬件地址
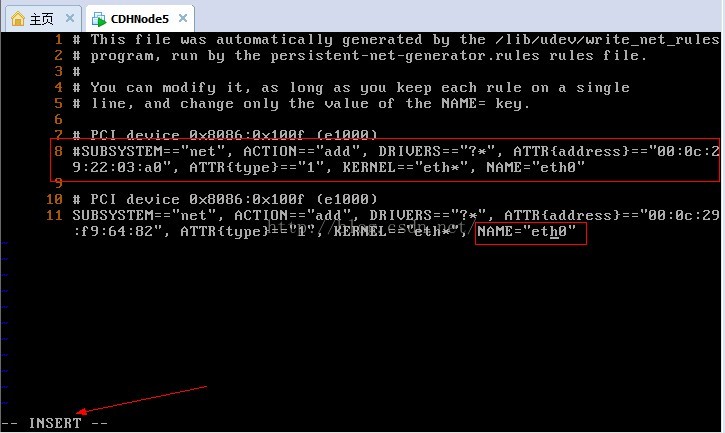
12、我们先移除网卡e1000,使用modprobe -r e1000命令
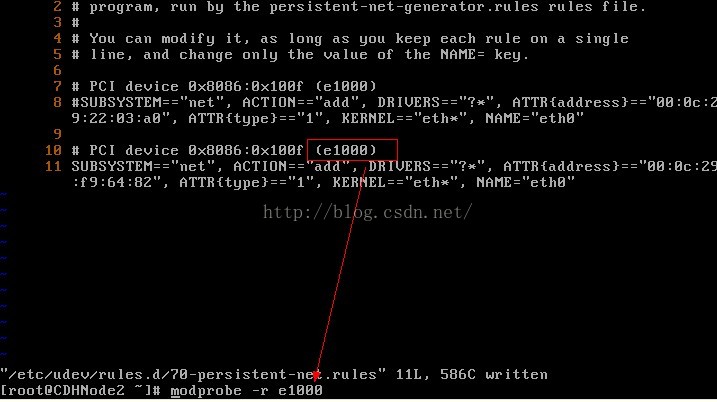
13、重新安装网卡e000

14、修改网卡配置信息

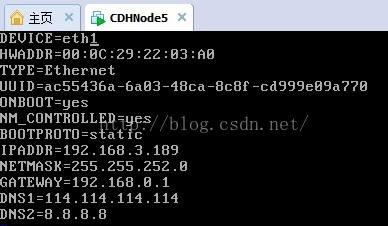
15、把设备号修改为DEVICE=eth0,先注释掉mac地址(硬件地址),在修改ip地址。

16、重启网络服务

注意:如果不正确,ip已经被使用,可以重新设置成其他的ip地址,按照以上方式配置。
17、接下来是修改主机名,把CDHNode2改成CDHNode5


18、重启主机后,就可以看到主机名的变成CDHNode5。


19、由于我们注释了mac地址,所以我们开改成新的mac地址,首先使用ifconfig查看新的mac地址,记住下面地址,

20、进入ifcfg-eth0文件,修改HWaddr,改为刚才查看的mac地址

再使用service network restart命令重启网络服务。至此配置完毕,最后按Esc,然后:wq保存退出。
接下来在其他节点上进行相应的配置。
配置host文件
在5个节点上分别配置hosts文件,注意使用root用户配置


最后按Esc,然后:wq保存退出。
关闭防火墙
在所有节点上使用root用户,关闭防火墙。由于要使用ssh协议来进行主机间的无密码访问,所以需要关闭防火墙。
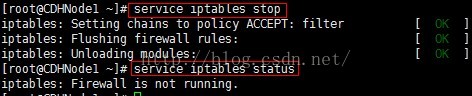
1、首先查看防火墙的状态,显示防火墙正在运行

2、然后永久关闭防火墙,使用chkconfig iptables off命令,此时当前虚拟机的防火墙还没有关闭。只有在关机重启后才能生效。
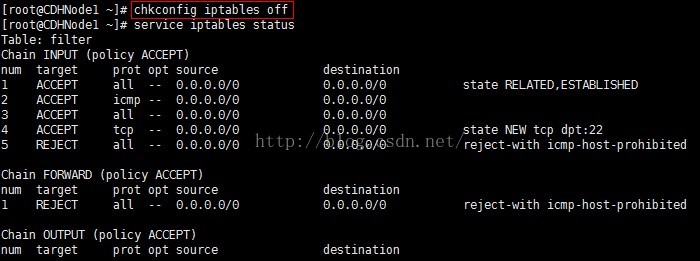
3、关闭ipv6的防火墙

4、也可以使用service iptables stop命令,暂时关闭当前主机的防火墙。
5、关闭selinux


将其SELINUX=enforcing设置为SELINUX=disabled

最后按Esc,然后:wq保存退出。
时间同步
当我们每一次启动集群时,时间基本上是不同步的,所以需要时间同步。要求所以节点保持一致的时间。
注意:使用root用户修改,5个节点同时修改
1、我们先使用date命令查看当前系统时间

如果系统时间与当前时间不一致,可以按照如下方式修改
2、查看时区设置是否正确。我们设置的统一时区为Asia/Shanghai,如果时区设置不正确,可以按照如下步骤把当前时区修改为上海。

3、下面我们使用ntp(网络时间协议)同步时间。如果ntp命令不存在,则需要在线安装ntp

4、安装ntp后,我们可以使用ntpdate命令进行联网时间同步。

5、最后我们在使用date命令查看,时间是否同步成功。
注意:在桥接模式下,上述同步时钟的方法行不通。换一下方法,我们使用手动配置时间,在xshell中,全部xshell会话的方式的方式同时更改所有节点。
a、使用date查看时间
b、设置日期,比如设置成2016年5月20日

c、设置时间,比如设置成下午1点48分45秒

d、最后将当前时间和日期写入BIOS,避免重启后失效

使用Xshell远程连接centos系统
由于在centos中复制修改等操作方便,我们使用windows上的一款远程连接工具Xshell,下面简单讲一下连接步骤。你需要先从网上下载安装Xshell和Xftp(可以用来可视化的文件传输)这两款工具。
连接步骤如下,以连接CDHNode1为例。
1、首先点击新建按钮,如下;在新建会话属性对话框中输入名称和需要连接的主机ip地址。

2、接下来点击左侧的用户身份验证,输入要登录主机的用户名和密码,点击确定,此时创建成功。

3、在打开会话对话框中选中刚创建的CDHNode1,然后点击连接

4、此时连接成功,即可进行远程操作

5、为了以后方便打开远程主机,我们可以把当前连接的主机添加到链接栏中,只需点击添加到链接栏按钮即可添加
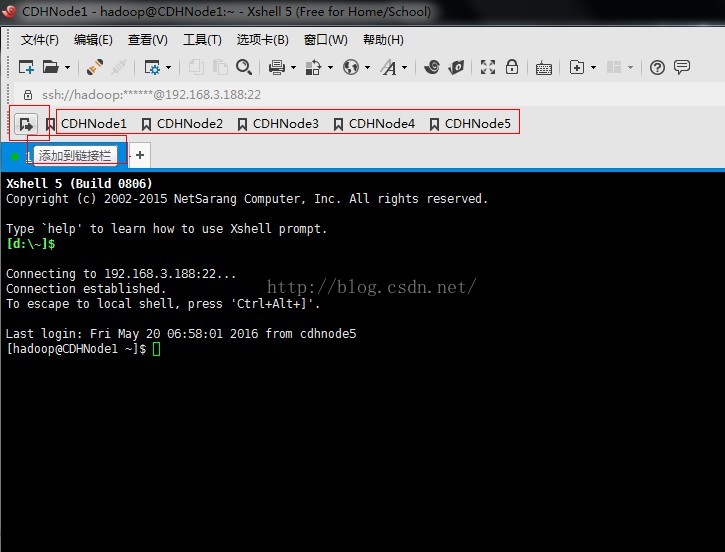
6、为了防止一个命令在多个主机中输入,我们也可以使用撰写栏,快速的把一个命令传送到所以打开的会话框。提示:撰写栏可以在查看菜单栏中打开。

配置免密码登录ssh
接上面的配置,我们已经使用Xshell远程登录上五个节点。下面我们就配置免密码登录hadoop用户,如果你使用root用户登录的,需要先切换到hadoop用户,使用 su hadoop命令切换。步骤如下:
1、首先切换到hadoop的家目录下,使用cd /home/hadoop命令来切换。然后在hadoop家目录下创建 .ssh目录。

2、然后生成hadoop用户的rsa(非对称加密算法),运行如下命令后,一直回车,即可生成hadoop的公钥和私钥

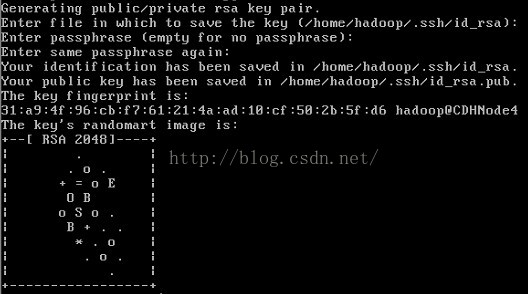
3、切换到 .ssh目录下,即可看到已经生成的公钥和私钥。

4、按照上面的步骤,在所有节点上生成公钥和私钥,接下来需要把所有节点的公钥发到CDHNode1节点的授权文件。如下图,我们使用Xshell最下方的撰写栏向所有节点发送ssh-copy-id CDHNode1命令。
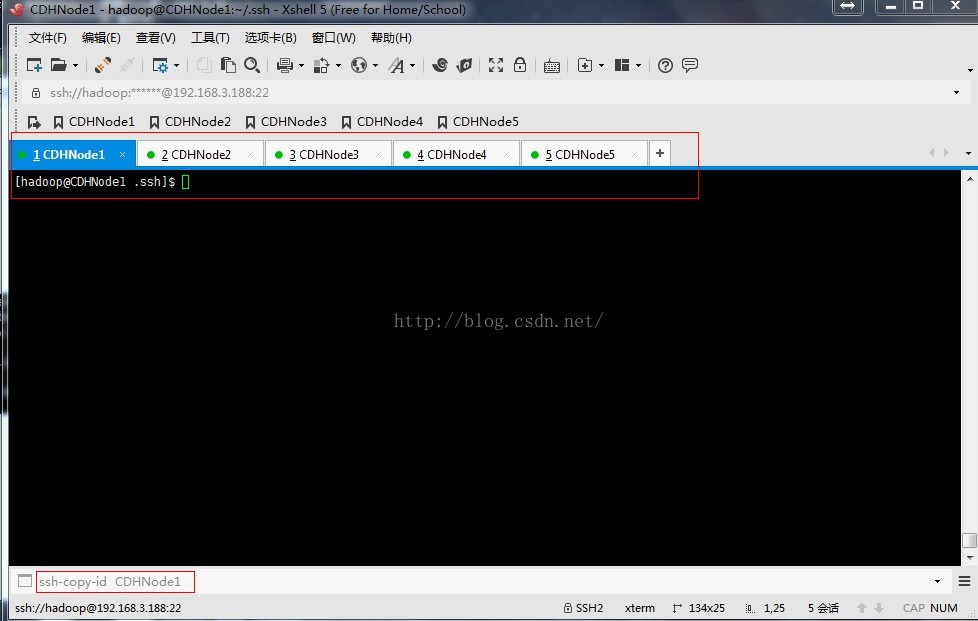
5、执行结果如下,每个节点包括CDHNode1节点,都把自己刚才生成的公钥 id_rsa.pub文件发送到CDHNode1节点的授权文件authorized_keys中。

注意:也可以在所有节点使用
cat ~/.ssh/id_rsa.pub | ssh hadoop@CDHNode1 'cat >> ~/.ssh/authorized_keys' 命令把自己的公钥追加到CDHNode1节点的授权文件authorized_keys中。
6、可以查看CDHNode1节点的授权文件authorized_keys中是否把所有节点的公钥都添加到此文件中,若有节点没有加入,则可以使用上一步命令重新添加。

7、然后我们就把这个文件拷贝到其他节点的.ssh目录下。


CDHNode4、CDHNode5按照上述命令自己执行。注意,这个命令是在CDHNode1节点上执行的。
8、根据下图,可以看到CDHNode5下已经复制了一份authorized_keys文件。下面以CDHNode5为例,修改.ssh目录以及.ssh目录下的文件的权限。其他节点按照如下步骤 一 一 修改。

9、修改好权限后,至此ssh配置成功,可以使用ssh测试是否配置成功,第一次使用ssh连接其他节点时需要输入yes,退出使用exit命令,在第二次登陆时,就不需要在输入,如下图直接登陆并显示最后登录时间。

提示:rsa非对称加密算法是把公钥发送个对方,对方使用公钥对数据进行加密后,自己在使用私钥对数据进行解密。
免密码登录的原理:
- 需要依靠密钥,也就是自己创建的一对密钥,并把公钥放到需要访问的服务器上。
- 如果你需要连接SSH服务器,客户端软件就会向服务器发出请求,请求用你的密钥进行安全验证。
- 服务器收到请求后,现在该服务器上的主目录下寻找你的公钥,然后把它和你发送过来的公钥进行比较。如果两个密钥一致,服务端就用公钥加密“质询”(challenge),并把它发送给客户端软件。
- 客户端收到“质询”后,就用你的私钥进行解密。再把它发送个服务器。
- 服务器比较发送来的“质询”和原先的是否一致,如果一致则进行授权,完成建立会话的操作。
脚本工具的使用
此处使用脚本文件的目的是为了简化安装步骤,毕竟有五个节点,如果全部使用命令一个一个操作,太费时费力了。为了简化操作,我们使用脚本文件来帮助我们执行多个重复的命令。就就相当于windows的批处理,把所有的命令集中起来,一个命令完成多个操作。
下面我们在CDHNode1节点上新建三个文件,deploy.conf(配置文件),deploy.sh(实现文件复制的shell脚本文件),runRemoteCdm.sh(在远程节点上执行命令的shell脚本文件)。
1、我们把三个文件放到/home/hadoop/tools目录下,先创建此目录
- [hadoop@CDHNode1 ~]$ mkdir /home/hadoop/tools
2、然后切换到tools目录下
[hadoop@CDHNode1 ~]$cd tools
3、首先创建deploy.conf文件
- [hadoop@CDHNode1 tools]$ vi deploy.conf
- CDHNode1,all,zookeeper,journalnode,namenode,resourcemanager,
- CDHNode2,all,slave,zookeeper,journalnode,namenode,datanode,resourcemanager,
- CDHNode3,all,slave,zookeeper,journalnode,datanode,nodemanager,
- CDHNode4,all,slave,journalnode,datanode,nodemanager,
- CDHNode5,all,slave,journalnode,datanode,nodemanager,
先解释一下这个文件,这个文件就是配置在每个几点上的功能,就是上面所讲的
主机规划
。比如zookeeper安装在CDHnode1、CDHnode2、CDHnode3这三个主机上。其他的自己对比查看。
4、创建deploy.sh文件
- [hadoop@CDHNode1 tools]$ vi deploy.sh
- #!/bin/bash
- #set -x
-
- #判断参数是否小于3个,因为运行deploy.sh需要有源文件(或源目录)和目标文件(或目标目录),
- #以及在MachineTag(哪些主机)上执行,这个标记就是上面deploy.conf中的标记 ,如 zookeeper、all等
- #使用实例如:我们把app目录下的所有文件复制到远程标记为zookeeper的主机上的/home/hadoop/app目录下
- # ./deploy.sh /home/hadoop/app /home/hadoop/app zookeeper
- #执行完上述命令后,shell脚本文件就自动把CDHNode1下的app目录中的文件复制到三个zookeeper节点的app目录下
- if [ $# -lt 3 ]
- then
- echo "Usage: ./deply.sh srcFile(or Dir) descFile(or Dir) MachineTag"
- echo "Usage: ./deply.sh srcFile(or Dir) descFile(or Dir) MachineTag confFile"
- exit
- fi
- #源文件或源目录
- src=$1
- #目标文件或目标目录
- dest=$2cat
- #标记
- tag=$3
-
- #判断是否使用deploy.conf配置文件,或者自己指定配置文件
-
- if [ 'a'$4'a' == 'aa' ]
- then
- confFile=/home/hadoop/tools/deploy.conf
- else
- confFile=$4
- fi
-
- #判断配置文件是否是普通文本文件
- if [ -f $confFile ]
- then
- #判断原件是普通文件还是目录
- if [ -f $src ]
- then
- #如果是普通文件就把解析出标记对应的主机名的ip
- for server in `cat $confFile|grep -v '^#'|grep ','$tag','|awk -F',' '{print $1}'`
- do
- scp $src $server":"${dest} #使用循环把文件复制到目标ip上的相应目录下
- done
- elif [ -d $src ]
- then
- for server in `cat $confFile|grep -v '^#'|grep ','$tag','|awk -F',' '{print $1}'`
- do
- scp -r $src $server":"${dest}
- done
- else
- echo "Error: No source file exist"
- fi
-
- else
- echo "Error: Please assign config file or run deploy.sh command with deploy.conf in same directory"
- fi
5、创建 runRemoteCmd.sh 脚本文件
- [hadoop@CDHNode1 tools]$ vi runRemoteCmd.sh
- #!/bin/bash
- #set -x
- #判断参数个数
- #实例如:显示所有节点的java进程,中间用引号的就是命令,这个命令将在所以节点上执行
- #./runRemoteCmd.sh "jps" all
- if [ $# -lt 2 ]
- then
- echo "Usage: ./runRemoteCmd.sh Command MachineTag"
- echo "Usage: ./runRemoteCmd.sh Command MachineTag confFile"
- exit
- fi
-
- cmd=$1
- tag=$2
- if [ 'a'$3'a' == 'aa' ]
- then
-
- confFile=/home/hadoop/tools/deploy.conf
- else
- confFile=$3
- fi
-
- if [ -f $confFile ]
- then
- for server in `cat $confFile|grep -v '^#'|grep ','$tag','|awk -F',' '{print $1}'`
- do
- echo "*******************$server***************************"
- ssh $server "source /etc/profile; $cmd"
- # 注意在使用的时候要根据自己设置的环境变量的配置位置,给定相应的source源 ,
- # 如 我把环境变量设/home/hadoop/.bash_profile文件下,就需要上面这条命令改为
- # ssh $server "source /home/hadoop/.bash_profile;$cmd"
- #上面的例子:这条命令就是在远程标记为tag的主机下执行这个命令jps。
- done
- else
- echo "Error: Please assign config file or run deploy.sh command with deploy.conf in same directory"
- fi
6、给脚本文件添加执行权限。
- [hadoop@CDHNode1 tools]$chmod u+x deploy.sh
- [hadoop@CDHNode1 tools]$chmod u+x runRemoteCmd.sh
7、把tools目录添加到环境变量PATH中。
- [hadoop@CDHNode1 tools]$vi /home/hadoop/.bash_profile
添加下面内容
- #tools
- export PATH=$PATH:/home/hadoop/tools
8、是环境变量及时生效
- [hadoop@CDHNode1 tools]$source /home/hadoop/.bash_profile
9、在CDHNode1节点上,通过runRemoteCmd.sh脚本,一键创建所有节点的软件安装目录/home/hadoop/app。
- [hadoop@CDHNode1 tools]$ runRemoteCmd.sh "mkdir /home/hadoop/app" all
我们可以在所有节点查看到/home/hadoop/app目录已经创建成功。
我们先来说一下软件的安装步骤:
对于解压安装的软件,安装步骤为:
- 使用rz命令上传要安装的文件,此命令只能在远程连接工具xshell上执行,不能再centos虚拟机上执行
- 使用tar -zxvf softwarename.tar.gz
- 修改配置文件(根据需要而定,有时可省略)
- 在环境变量文件中配置环境变量
- 使用source 是环境变量文件即时生效。
安装JDK
首先在CDHNode1上安装jdk,然后复制到其他节点。
1、上传使用rz后,找到下载的jdk文件(jdk-7u79-linux-x64.tar.gz )即可,选择后就可以上传,上传需要时间。
- [hadoop@CDHNode1 ~]$cd /home/hadoop/app
-
- [hadoop@CDHNode1 app]$ rz //选择本地的下载好的jdk-7u79-linux-x64.tar.gz
2、解压jdk-7u79-linux-x64.tar.gz
- [hadoop@CDHNode1 app]$ tar zxvf jdk-7u79-linux-x64.tar.gz //解压
3、修改jdk的名字,删除上传的压缩文件jdk-7u79-linux-x64.tar.gz
- [hadoop@CDHNode1 app]$ mv jdk1.7.0_79 jdk
- [hadoop@CDHNode1 app]$ rm -rf jdk-7u79-linux-x64.tar.gz //删除安装包
4、配置环境变量
- [hadoop@CDHNode1 app]$vi /home/hadoop/.bash_profile
添加
- #java
- export JAVA_HOME=/home/hadoop/app/jdk
- export CLASSPATH=.:$JAVA_HOME/lib:$CLASSPATH
- export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
5、使环境变量文件即时生效
- [hadoop@CDHNode1 app]$source /home/hadoop/.bash_profile
6、查看是否安装成功,查看Java版本
- [hadoop@CDHNode1 app]# java -version
- java version "1.7.0_79"
- Java(TM) SE Runtime Environment (build 1.7.0_79-b15)
- Java HotSpot(TM) 64-Bit Server VM (build 24.79-b02, mixed mode)
出现以上结果就说明CDHNode1节点上的jdk安装成功。
然后将CDHNode1下的jdk安装包复制到其他节点上。
- [hadoop@CDHNode1 app]$ deploy.sh jdk /home/hadoop/app/ slave
CDHNode2、CDHNode3、CDHNode4、CDHNode5加点重复CDHNode1上的jdk配置即可。就是在其他节点上从第4步开始配置。
安装Zookeeper
首先在CDHNode1上安装Zookeeper,然后复制到其他节点。
1、将本地下载好的zookeeper-3.4.6.tar.gz安装包,上传至CDHNode1节点下的/home/hadoop/app目录下。
- [hadoop@CDHNode1 app]$ rz //选择本地下载好的zookeeper-3.4.6.tar.gz
2、解压zookeeper-3.4.6.tar.gz
- [hadoop@CDHNode1 app]$ tar zxvf zookeeper-3.4.6.tar.gz //解压
3、修改zookeeper的名字,删除上传的压缩文件zookeeper-3.4.6.tar.gz
- [hadoop@CDHNode1 app]$ rm -rf zookeeper-3.4.6.tar.gz //删除zookeeper-3.4.6.tar.gz安装包
- [hadoop@CDHNode1 app]$ mv zookeeper-3.4.6 zookeeper //重命名
4、修改Zookeeper中的配置文件。
[hadoop@CDHNode1 app]$ cd /home/hadoop/app/zookeeper/conf/
- [hadoop@CDHNode1 conf]$ cp zoo_sample.cfg zoo.cfg //复制一个zoo.cfg文件
- [hadoop@CDHNode1 conf]$ vi zoo.cfg
- #添加下面的
- # The number of milliseconds of each tick
- tickTime=2000
- # The number of ticks that the initial
- # synchronization phase can take
- initLimit=10
- # The number of ticks that can pass between
- # sending a request and getting an acknowledgement
- syncLimit=5
- # the directory where the snapshot is stored.
- # do not use /tmp for storage, /tmp here is just
- # example sakes.
- #数据文件目录与日志目录
- dataDir=/home/hadoop/data/zookeeper/zkdata
- dataLogDir=/home/hadoop/data/zookeeper/zkdatalog
- # the port at which the clients will connect
- clientPort=2181
- #server.服务编号=主机名称:Zookeeper不同节点之间同步和通信的端口:选举端口(选举leader)
- server.1=CDHNode1:2888:3888
- server.2=CDHNode2:2888:3888
- server.3=CDHNode3:2888:3888
-
- # administrator guide before turning on autopurge.
- #
- # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
- #
- # The number of snapshots to retain in dataDir
- #autopurge.snapRetainCount=3
- # Purge task interval in hours
- # Set to "0" to disable auto purge feature
- #autopurge.purgeInterval=1
- ~
- ~
- ~
5、配置环境变量
- [hadoop@CDHNode1 app]$vi /home/hadoop/.bash_profile
添加
- export ZOOKEEPER_HOME=/home/hadoop/app/zookeeper
- export PATH=$PATH:$ZOOKEEPER_HOME/bin
6、使环境变量文件即时生效
- [hadoop@CDHNode1 app]$source /home/hadoop/.bash_profile
7、通过远程命令deploy.sh将Zookeeper安装目录拷贝到其他节点(CDHNode2、CDHNode3)上面
- [hadoop@CDHNode1 app]$deploy.sh zookeeper /home/hadoop/app/ zookeeper
8、通过远程命令runRemoteCmd.sh在所有的zookeeper节点(CDHNode1、CDHNode2、CDHNode3)上面创建目录:
- [hadoop@CDHNode1 app]$ runRemoteCmd.sh "mkdir -p /home/hadoop/data/zookeeper/zkdata" zookeeper //创建数据目录
- [hadoop@CDHNode1 app]$ runRemoteCmd.sh "mkdir -p /home/hadoop/data/zookeeper/zkdatalog" zookeeper //创建日志目录
9、
然后分别在CDHNode1、CDHNode2、CDHNode3上面,进入zkdata目录下,创建文件myid,里面的内容分别填充为:1、2、3, 这里我们以CDHNode1为例。
- [hadoop@CDHNode1 app]$ cd /home/hadoop/data/zookeeper/zkdata
- [hadoop@CDHNode1 zkdata]$ vi myid
//输入数字1
CDHNode2输入数字2、CDHNode3输入数字3。
10、在CDHNode2、CDHNode3上面配置Zookeeper环境变量。按照第5、6步配置。
11、使用runRemoteCmd.sh 脚本,启动所有节点(CDHNode1、CDHNode2、CDHNode3)上面的Zookeeper。
- [hadoop@CDHNode1 zkdata]$ runRemoteCmd.sh "/home/hadoop/app/zookeeper/bin/zkServer.sh start" zookeeper
12、
查看所有节点上面的QuorumPeerMain进程是否启动。
- [hadoop@CDHNode1 zkdata]$ runRemoteCmd.sh "jps" zookeeper
13、
查看所有Zookeeper节点状态。
- [hadoop@CDHNode1 zkdata]$ runRemoteCmd.sh "/home/hadoop/app/zookeeper/bin/zkServer.sh status" zookeeper
如果一个节点为leader,另2个节点为follower,则说明Zookeeper安装成功。
注意:QuorumPeerMain可能不显示在jps进程中,可以使用bin/zkServer.sh status 查看状态,无法启动的原因可以查看zookeeper.out文件,查看错误原因
- <span style="color:#000000;">[hadoop@CDHNode2 ~]$ cd app/zookeeper/
- [hadoop@CDHNode2 zookeeper]$ ls
- bin cloudera-pom.xml ivysettings.xml NOTICE.txt share zookeeper.out
- build.properties conf ivy.xml README_packaging.txt src
- build.xml contrib lib README.txt zookeeper-3.4.5-cdh5.4.5.jar
- CHANGES.txt dist-maven libexec recipes zookeeper-3.4.5-cdh5.4.5.jar.md5
- cloudera docs LICENSE.txt sbin zookeeper-3.4.5-cdh5.4.5.jar.sha1
- [hadoop@CDHNode2 zookeeper]$ vi zookeeper.out
-
- 2016-05-20 16:00:30,095 [myid:] - INFO [main:QuorumPeerConfig@101] - Reading configuration from: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
- 2016-05-20 16:00:30,099 [myid:] - INFO [main:QuorumPeerConfig@334] - Defaulting to majority quorums
- 2016-05-20 16:00:30,100 [myid:] - ERROR [main:QuorumPeerMain@86] - Invalid config, exiting abnormally
- org.apache.zookeeper.server.quorum.QuorumPeerConfig$ConfigException: Error processing /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
- at org.apache.zookeeper.server.quorum.QuorumPeerConfig.parse(QuorumPeerConfig.java:121)
- at org.apache.zookeeper.server.quorum.QuorumPeerMain.initializeAndRun(QuorumPeerMain.java:106)
- at org.apache.zookeeper.server.quorum.QuorumPeerMain.main(QuorumPeerMain.java:79)
- Caused by: java.lang.IllegalArgumentException: /home/hadoop/data/zookeeper/zkdata/myid file is missing
- at org.apache.zookeeper.server.quorum.QuorumPeerConfig.parseProperties(QuorumPeerConfig.java:344)
- at org.apache.zookeeper.server.quorum.QuorumPeerConfig.parse(QuorumPeerConfig.java:117)
- ... 2 more
- Invalid config, exiting abnormally
- </span>
安装hadoop
首先在CDHNode1上安装hadoop,然后复制到其他节点。
1、将本地下载好的hadoop-2.6.0-cdh5.4.5.tar.gz安装包,上传至CDHNode1节点下的/home/hadoop/app目录下。
- [hadoop@CDHNode1 app]$ rz //选择本地下载好的hadoop-2.6.0-cdh5.4.5.tar.gz
2、解压hadoop-2.6.0-cdh5.4.5.tar.gz
- [hadoop@CDHNode1 app]$ tar zxvf hadoop-2.6.0-cdh5.4.5.tar.gz //解压
3、修改hadoop的名字,删除上传的压缩文件hadoop-2.6.0-cdh5.4.5.tar.gz
- [hadoop@CDHNode1 app]$ rm -rf hadoop-2.6.0-cdh5.4.5.tar.gz //删除hadoop-2.6.0-cdh5.4.5.tar.gz 安装包
- [hadoop@CDHNode1 app]$ mv hadoop-2.6.0 hadoop //重命名
4、配置环境变量
- [hadoop@CDHNode1 app]$vi /home/hadoop/.bash_profile
添加
- # hadoop_home 2.6.0 path
- HADOOP_HOME=/home/hadoop/app/hadoop
- PATH=$HADOOP_HOME/bin:$PATH
- export HADOOP_HOME PATH
5、使环境变量文件即时生效
- [hadoop@CDHNode1 app]$source /home/hadoop/.bash_profile
6、切换到/home/hadoop/app/hadoop/etc/hadoop/目录下,修改配置文件。
- [hadoop@CDHNode1 app]$ cd /home/hadoop/app/hadoop/etc/hadoop/
配置HDFS
配置hadoop-env.sh
[hadoop@CDHNode1 hadoop]$ vi hadoop-env.sh
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
配置core-site.xml
- [hadoop@CDHNode1 hadoop]$ vi core-site.xml
- <configuration>
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://cluster1</value>
- </property>
- <-- 这里的值指的是默认的HDFS路径 ,取名为cluster1 -->
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/home/hadoop/data/tmp</value>
- </property>
- <-- hadoop的临时目录,如果需要配置多个目录,需要逗号隔开,data目录需要我们自己创建 -->
- <property>
- <name>ha.zookeeper.quorum</name>
- <value>CDHNode1:2181,CDHNode2:2181,CDHNode3:2181,CDHNode4:2181,CDHNode5:2181</value>
- </property>
- <-- 配置Zookeeper 管理HDFS -->
- </configuration>
配置hdfs-site.xml
- [hadoop@CDHNode1 hadoop]$ vi hdfs-site.xml
- <configuration>
- <property>
- <name>dfs.replication</name>
- <value>3</value>
- </property>
- <-- 数据块副本数为3 -->
- <property>
- <name>dfs.permissions</name>
- <value>false</value>
- </property>
- <property>
- <name>dfs.permissions.enabled</name>
- <value>false</value>
- </property>
- <-- 权限默认配置为false -->
- <property>
- <name>dfs.nameservices</name>
- <value>cluster1</value>
- </property>
- <-- 命名空间,它的值与fs.defaultFS的值要对应,namenode高可用之后有两个namenode,cluster1是对外提供的统一入口 -->
- <property>
- <name>dfs.ha.namenodes.cluster1</name>
- <value>CDHNode1,CDHNode2</value>
- </property>
- <-- 指定 nameService 是 cluster1 时的nameNode有哪些,这里的值也是逻辑名称,名字随便起,相互不重复即可 -->
- <property>
- <name>dfs.namenode.rpc-address.cluster1.CDHNode1</name>
- <value>CDHNode1:9000</value>
- </property>
- <-- CDHNode1 rpc地址 -->
- <property>
- <name>dfs.namenode.http-address.cluster1.CDHNode1</name>
- <value>CDHNode1:50070</value>
- </property>
- <-- CDHNode1 http地址 -->
- <property>
- <name>dfs.namenode.rpc-address.cluster1.CDHNode2</name>
- <value>CDHNode2:9000</value>
- </property>
- <-- CDHNode2 rpc地址 -->
- <property>
- <name>dfs.namenode.http-address.cluster1.CDHNode2</name>
- <value>CDHNode2:50070</value>
- </property>
- <-- CDHNode2 http地址 -->
- <property>
- <name>dfs.ha.automatic-failover.enabled</name>
- <value>true</value>
- </property>
- <-- 启动故障自动恢复 -->
- <property>
- <name>dfs.namenode.shared.edits.dir</name>
- <value>qjournal://CDHNode1:8485;CDHNode2:8485;CDHNode3:8485;CDHNode4:8485;CDHNode5:8485/cluster1</value>
- </property>
- <-- 指定journal -->
- <property>
- <name>dfs.client.failover.proxy.provider.cluster1</name>
- <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
- </property>
- <-- 指定 cluster1 出故障时,哪个实现类负责执行故障切换 -->
- <property>
- <name>dfs.journalnode.edits.dir</name>
- <value>/home/hadoop/data/journaldata/jn</value>
- </property>
- <-- 指定JournalNode集群在对nameNode的目录进行共享时,自己存储数据的磁盘路径 -->
- <property>
- <name>dfs.ha.fencing.methods</name>
- <value>shell(/bin/true)</value>
- </property>
- <property>
- <name>dfs.ha.fencing.ssh.private-key-files</name>
- <value>/home/hadoop/.ssh/id_rsa</value>
- </property>
- <property>
- <name>dfs.ha.fencing.ssh.connect-timeout</name>
- <value>10000</value>
- </property>
- <-- 脑裂默认配置 -->
- <property>
- <name>dfs.namenode.handler.count</name>
- <value>100</value>
- </property>
- </configuration>
配置 slave
- [hadoop@CDHNode1 hadoop]$ vi slaves
- CDHNode3
-
- CDHNode4
-
- CDHNode5
YARN安装配置
配置mapred-site.xml
- [hadoop@CDHNode1 hadoop]$ vi mapred-site.xml
- <configuration>
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- <-- 指定运行mapreduce的环境是Yarn,与hadoop1不同的地方 -->
- </configuration>
-
配置yarn-site.xml
- [hadoop@CDHNode1 hadoop]$ vi yarn-site.xml
- <configuration>
- <property>
- <name>yarn.resourcemanager.connect.retry-interval.ms</name>
- <value>2000</value>
- </property>
- <-- 超时的周期 -->
- <property>
- <name>yarn.resourcemanager.ha.enabled</name>
- <value>true</value>
- </property>
- <-- 打开高可用 -->
- <property>
- <name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
- <value>true</value>
- </property>
- <-- 启动故障自动恢复 -->
- <property>
- <name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
- <value>true</value>
- </property>
- <property>
- <name>yarn.resourcemanager.cluster-id</name>
- <value>yarn-rm-cluster</value>
- </property>
- <-- 给yarn cluster 取个名字yarn-rm-cluster -->
- <property>
- <name>yarn.resourcemanager.ha.rm-ids</name>
- <value>rm1,rm2</value>
- </property>
- <-- 给ResourceManager 取个名字 rm1,rm2 -->
- <property>
- <name>yarn.resourcemanager.hostname.rm1</name>
- <value>CDHNode1</value>
- </property>
- <-- 配置ResourceManager rm1 hostname -->
- <property>
- <name>yarn.resourcemanager.hostname.rm2</name>
- <value>CDHNode2</value>
- </property>
- <-- 配置ResourceManager rm2 hostname -->
- <property>
- <name>yarn.resourcemanager.recovery.enabled</name>
- <value>true</value>
- </property>
- <-- 启用resourcemanager 自动恢复 -->
- <property>
- <name>yarn.resourcemanager.zk.state-store.address</name>
- <value>CDHNode1:2181,CDHNode2:2181,CDHNode3:2181,CDHNode4:2181,CDHNode5:2181</value>
- </property>
- <-- 配置Zookeeper地址 -->
- <property>
- <name>yarn.resourcemanager.zk-address</name>
- <value>CDHNode1:2181,CDHNode2:2181,CDHNode3:2181,CDHNode4:2181,CDHNode5:2181</value>
- </property>
- <-- 配置Zookeeper地址 -->
- <property>
- <name>yarn.resourcemanager.address.rm1</name>
- <value>CDHNode1:8032</value>
- </property>
- <-- rm1端口号 -->
- <property>
- <name>yarn.resourcemanager.scheduler.address.rm1</name>
- <value>CDHNode1:8034</value>
- </property>
- <-- rm1调度器的端口号 -->
- <property>
- <name>yarn.resourcemanager.webapp.address.rm1</name>
- <value>CDHNode1:8088</value>
- </property>
- <-- rm1 webapp端口号 -->
- <property>
- <name>yarn.resourcemanager.address.rm2</name>
- <value>CDHNode2:8032</value>
- </property>
- <-- rm2端口号 -->
- <property>
- <name>yarn.resourcemanager.scheduler.address.rm2</name>
- <value>CDHNode2:8034</value>
- </property>
- <-- rm2调度器的端口号 -->
- <property>
- <name>yarn.resourcemanager.webapp.address.rm2</name>
- <value>CDHNode2:8088</value>
- </property>
- <-- rm2 webapp端口号 -->
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- <property>
- <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
- <value>org.apache.hadoop.mapred.ShuffleHandler</value>
- </property>
- <-- 执行MapReduce需要配置的shuffle过程 -->
- </configuration>
向所有节点分发hadoop安装包。
[hadoop@CDHNode1 app]$ deploy.sh hadoop /home/hadoop/app/ slave
按照目录的规划建立好目录(用于存放数据的目录):
- runRemoteCmd.sh "mkdir -p /home/hadoop/data/name" all
-
- runRemoteCmd.sh "mkdir -p /home/hadoop/data/hdfs/edits" all
-
- runRemoteCmd.sh "mkdir -p /home/hadoop/data/datanode" all
-
- runRemoteCmd.sh "mkdir -p /home/hadoop/data/journaldata/jn" all
-
- runRemoteCmd.sh "mkdir -p /home/hadoop/data/tmp" all
-
- runRemoteCmd.sh "touch /home/hadoop/app/hadoop/etc/hadoop/excludes" all
-
- runRemoteCmd.sh "mkdir -p /home/hadoop/data/pid" all
当你的在初始化工程中出错,要把相关目录的文件删除,然后再重新初始化
- rm -rf /home/hadoop/data/name/*
-
- rm -rf /home/hadoop/data/hdfs/edits/*
-
- rm -rf /home/hadoop/data/datanode/*
-
- rm -rf /home/hadoop/data/journaldata/jn/*
-
- rm -rf /home/hadoop/data/tmp/*
集群初始化
1、启动所有节点上面的Zookeeper进程
[hadoop@CDHNode1 hadoop]$ runRemoteCmd.sh "/home/hadoop/app/zookeeper/bin/zkServer.sh start" zookeeper
2、启动所有节点上面的journalnode进程
[hadoop@CDHNode1 hadoop]$ runRemoteCmd.sh "/home/hadoop/app/hadoop/sbin/hadoop-daemon.sh start journalnode" all
3、首先在主节点上(比如,CDHNode1)执行格式化
- [hadoop@CDHNode1 hadoop]$ bin/hdfs namenode -format / /namenode 格式化
- [hadoop@CDHNode1 hadoop]$ bin/hdfs zkfc -formatZK //格式化高可用
- [hadoop@CDHNode1 hadoop]$bin/hdfs namenode //启动namenode
注意:执行完上述命令后,程序就会在等待状态,只有执行完下一步时,利用按下ctrl+c来结束namenode进程。
4、与此同时,需要在备节点(比如 CDHNode2)上执行数据同步
注意:同时是在执行完上一步后,上一步程序停止的情况下执行此步骤的
[hadoop@CDHNode2 hadoop]$ bin/hdfs namenode -bootstrapStandby //同步主节点和备节点之间的元数据
5、CDHNode2同步完数据后,紧接着在CDHNode1节点上,按下ctrl+c来结束namenode进程。 然后关闭所有节点上面的journalnode进程
[hadoop@CDHNode1 hadoop]$ runRemoteCmd.sh "/home/hadoop/app/hadoop/sbin/hadoop-daemon.sh stop journalnode" all //然后停掉各节点的journalnode
6、如果上面操作没有问题,我们可以一键启动hdfs所有相关进程
- [hadoop@CDHNode1 hadoop]$ sbin/start-dfs.sh
启动成功之后,查看关闭其中一个namenode ,然后在启动namenode 观察切换的状况
7、验证是否启动成功
通过web界面查看namenode启动情况。
http://CDHNode1:50070
注意:在浏览器输入以上网址时,需要先在本机的hosts目录下添加如下映射:
192.168.3.188 CDHNode1
192.168.3.189 CDHNode2
192.168.3.190 CDHNode3
192.168.3.191 CDHNode4
192.168.3.192 CDHNode5
启动成功之后,查看关闭其中一个namenode ,然后在启动namenode 观察切换的状况
使用命令 kill
上传文件至hdfs
[hadoop@CDHNode1 hadoop]$ vi a.txt //本地创建一个a.txt文件
hadoop CDH
hello world
CDH hadoop
[hadoop@CDHNode1 hadoop]$ hdfs dfs -mkdir /test //在hdfs上创建一个文件目录
[hadoop@CDHNode1 hadoop]$ hdfs dfs -put djt.txt /test //向hdfs上传一个文件
[hadoop@CDHNode1 hadoop]$ hdfs dfs -ls /test //查看a.txt是否上传成功
如果上面操作没有问题说明hdfs配置成功。
启动YARN
1、在CDHNode1节点上执行。
[hadoop@CDHNode1 hadoop]$ sbin/start-yarn.sh
2、在CDHNode2节点上面执行。
[hadoop@CDHNode2 hadoop]$ sbin/yarn-daemon.sh start resourcemanager
同时打开一下web界面。
http://CDHNode1:8088
http://CDHNode2:8088
关闭其中一个resourcemanager,然后再启动,看看这个过程的web界面变化。
3、检查一下ResourceManager状态
[hadoop@CDHNode1 hadoop]$ bin/yarn rmadmin -getServiceState rm1
[hadoop@CDHNode1 hadoop]$ bin/yarn rmadmin -getServiceState rm2
4、Wordcount示例测试
[hadoop@djt11 hadoop]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount /test/a.txt /test/out/
如果上面执行没有异常,说明YARN安装成功。
集群关启顺序
关闭YARN
a、在CDHNode2节点上面执行
- [hadoop@CDHNode2 hadoop]$ sbin/yarn-daemon.sh stop resourcemanager
b、在CDHNode1节点上执行
- [hadoop@CDHNode1 hadoop]$ sbin/stop-yarn.sh
c、关闭HDFS
- [hadoop@CDHNode1 hadoop]$ sbin/stop-dfs.sh
d、关闭zookeeper
- [hadoop@CDHNode1 hadoop]$ runRemoteCmd.sh "/home/hadoop/app/zookeeper/bin/zkServer.sh stop" zookeeper
再次启动集群
a、启动zookeeper
- [hadoop@CDHNode1 hadoop]$ runRemoteCmd.sh "/home/hadoop/app/zookeeper/bin/zkServer.sh start" zookeeper
b、启动HDFS
- [hadoop@CDHNode1 hadoop]$ sbin/start-dfs.sh
c、在CDHNode1节点上执行
- [hadoop@CDHNode1 hadoop]$ sbin/start-yarn.sh
d、在CDHNode2节点上面执行
- [hadoop@CDHNode2 hadoop]$ sbin/yarn-daemon.sh start resourcemanager
至此,hadoop 分布式集群搭建完毕。