- 学号:2017035107252
- 姓名:宋佳琦
- 本次作业码云地址:https://gitee.com/pettynaoo/PettyNaoo_word_frequency/tree/master
代码分析:
def process_file(dst): # 读文件到缓冲区
try: # 打开文件 f = open(dst,'r') except IOError as s: print (s) return None try: # 读文件到缓冲区 bvffer = f.read() except: print ("Read File Error!") return None f.close() return bvffer
通过dst传入参数,将文件读取到缓冲区
def process_buffer(bvffer):
if bvffer:
word_freq = {}
# 下面添加处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq bvffer = bvffer.lower()#将字母改为小写 words = bvffer.strip().split()#以空格分割 for word in words: word_freq[word] = word_freq.get(word,0)+1#存放在字典里 return word_freq
处理缓冲区:
bvffer = bvffer.lower() 将字母改为小写
words = bvffer.strip().split()#以空格分割
for word in words:
word_freq[word] = word_freq.get(word,0)+1 将重复词汇统计存放在字典里
def output_result(word_freq):
if word_freq:
sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) for item in sorted_word_freq[:10]: # 输出 Top 10 的单词 print(item) if __name__ == "__main__": import argparse parser = argparse.ArgumentParser() parser.add_argument('dst') args = parser.parse_args() dst = args.dst bvffer = process_file(dst) word_freq = process_buffer(bvffer) output_result(word_freq)
输出重复率最高的十个单词
运行结果:
Gone_with_the_wind:
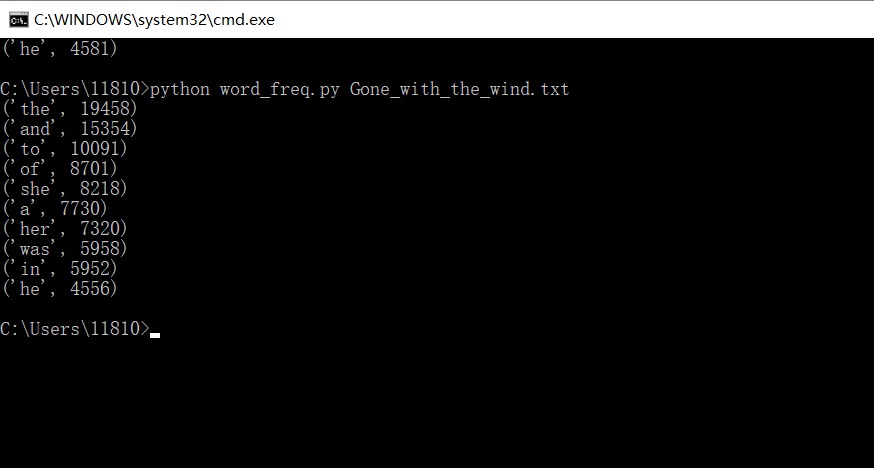
A_tile_of_two_cities:
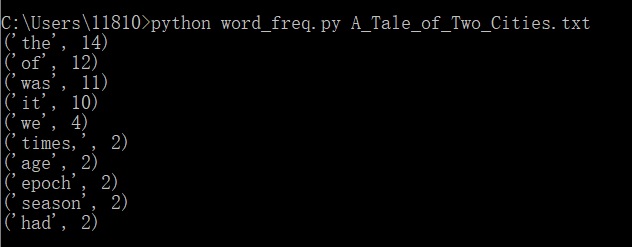
性能分析:

共执行457296次,耗时0.247秒

执行次数最多
总结:
- 前后共耗时八小时才完成这次作业,过程对于我来说真的蛮艰难了。时间大多耗费在之前的基础不足,所以通过百度补充了大量的基础知识以及基础的cmd运行程序。
- 但是每一步成功运行都会增添一份成就感,并且很多自己认为很难的问题其实很容易解决。
- 通过这次作业学习到了词频查重代码具体步骤的分析,也掌握了效能分析的方法及意义。