模型评估
评价指标Evaluation metrics
分类评价指标
1 准确率
2 平均准确率
3 对数损失Log-loss
4 基于混淆矩阵的评估度量
41 混淆矩阵
42 精确率Precision
43 召回率Recall
44 F1-score
5 AUCArea under the CurveReceiver Operating Characteristic ROC
TPRTrue Positive Rate
FPRFalse Positive Rate
ROC曲线
AUC
回归评价指标
1 RMSE
2 均方差mean squared error
3 平均绝对误差mean_absolute_error
4 中值绝对误差Median absolute error
5 R2 决定系数r2_score
问题
sklearn 评价指标
模型评估
有三种不同的方法来评估一个模型的预测质量:
estimator的score方法:sklearn中的estimator都具有一个score方法,它提供了一个缺省的评估法则来解决问题。
Scoring参数:使用cross-validation的模型评估工具,依赖于内部的scoring策略。见下。
通过测试集上评估预测误差:sklearn Metric函数用来评估预测误差。
评价指标(Evaluation metrics)
评价指标针对不同的机器学习任务有不同的指标,同一任务也有不同侧重点的评价指标。
主要有分类(classification)、回归(regression)、排序(ranking)、聚类(clustering)、热门主题模型(topic modeling)、推荐(recommendation)等。
一、分类评价指标(Evaluation metrics)、
分类有二分类和多分类,二分类主要“是”和“不是”的问题,可以扩展到多分类,如逻辑回归->SoftMax。
1.1 准确率
分类中,使用模型对测试集进行分类,分类正确的样本个数占总样本的比例:
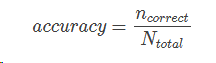
问题:
不同类别样本无区分:各个类平等对待,而实际中会针对不同类有所区分,例如医疗上侧重正例的召回(假阴性:不要漏诊疾病),垃圾邮件侧重垃圾邮件的精度(假阳性:正常邮件不被误分)。
数据不平衡:对于数据分布不平衡情况下,个别类别样本过多,其他类别样本少,大类别主导了准确率的计算。(平均准确率解决此问题)
SKlearn API
from sklearn.metrics import accuracy_score
# y_pred是预测标签
y_pred, y_true=[1,2,3,4], [2,2,3,4]
accuracy_score(y_true=y_true, y_pred=y_pred)1.2 平均准确率
针对不平衡数据,对n个类,计算每个类别i的准确率,然后求平均:
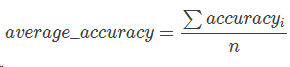
缺点:某些类别样本数很少,测试集中该类别的准确率方差会很大(统计变量偏离程度:高)。
from sklearn.metrics import average_precision_score
# y_pred是预测标签
y_pred, y_true =[1,0,1,0], [0,0,1,0]
average_precision_score(y_true=y_true, y_score=y_pred)1.3 对数损失(Log-loss)
针对分类输出不是类别,而是类别的概率,使用对数损失函数进行评价。这也是逻辑回归的分类函数,下面是二分类的损失函数。
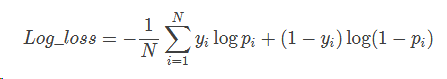
yi表示第i个样本类别0或1。pi表示其输入类别1的概率。其实就是真实值域预测值得交叉熵,包含了真实分布的熵加上假设与真实分布不同的分布的不确定性,最小化交叉熵,便是最大化分类器的准确率。
from sklearn.metrics import log_loss
y_true, y_pred = [0,0,1,1], [[0.9,0.1],[0.8,0.2],[0.3,0.7],[0.01,0.99]]
print(log_loss(y_true,y_pred))1.4 基于混淆矩阵的评估度量
1.4.1 混淆矩阵
混淆矩阵通过计算各种分类度量,指导模型的评估。

from sklearn.metrics import confusion_matrix
# y_pred是预测标签
y_pred, y_true =[1,0,1,0], [0,0,1,0]
confusion_matrix(y_true=y_true, y_pred=y_pred)1.4.2 精确率(Precision)
所有分正确的正样本/所有预测为正类的样本数。
![]()
1.4.3 召回率(Recall)
所有分正确的正样本/所有的正样本数:
![]()
1.4.4 F1-score
精确率和召回率两者一般同时使用,F1-score中和了二者的评估:

sklearn中classification_report可以直接输出各个类的precision recall f1-score support
from sklearn.metrics import classification_report
# y_pred是预测标签
y_pred, y_true =[1,0,1,0], [0,0,1,0]
print(classification_report(y_true=y_true, y_pred=y_pred))1.5 AUC(Area under the Curve(Receiver Operating Characteristic, ROC))
Auc是ROC(Receiver Operating Characteristic)曲线下的面积。在此再次召唤出混淆矩阵:


import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc
# y_test:实际的标签, dataset_pred:预测的概率值。
fpr, tpr, thresholds = roc_curve(y_test, dataset_pred)
roc_auc = auc(fpr, tpr)
#画图,只需要plt.plot(fpr,tpr),变量roc_auc只是记录auc的值,通过auc()函数能计算出来
plt.plot(fpr, tpr, lw=1, label='ROC(area = %0.2f)' % (roc_auc))
plt.xlabel("FPR (False Positive Rate)")
plt.ylabel("TPR (True Positive Rate)")
plt.title("Receiver Operating Characteristic, ROC(AUC = %0.2f)"% (roc_auc))
plt.show()
from sklearn.metrics import roc_auc_score
# y_test:实际的标签, dataset_pred:预测的概率值。
roc_auc_score(y_test, dataset_pred)2. 回归评价指标
回归是对连续的实数值进行预测,而分类中是离散值。
2.1 RMSE
RMSE(root mean square error,平方根误差),定义为:
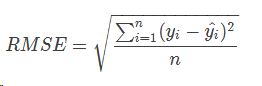
其中,yi是真实值,yi^是预测值,n是样本数量,使用了欧式距离。
缺点:平均值是非鲁棒的,对于异常点敏感,如果某个异常点误差大,整个RMSE就会比较大。
2.2 均方差(mean squared error)
from sklearn.metrics import mean_squared_error
y_true, y_pred = [3, -0.5, 2, 7], [2.5, 0.0, 2, 8]
mean_squared_error(y_true, y_pred)2.3 平均绝对误差(mean_absolute_error)
from sklearn.metrics import mean_squared_error
y_true, y_pred = [3, -0.5, 2, 7], [2.5, 0.0, 2, 8]
mean_squared_error(y_true, y_pred)2.4 中值绝对误差(Median absolute error)
![]()
from sklearn.metrics import median_absolute_error
y_true, y_pred = [3, -0.5, 2, 7], [2.5, 0.0, 2, 8]
median_absolute_error(y_true, y_pred)2.5 R2 决定系数(r2_score)
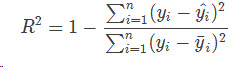
from sklearn.metrics import r2_score
y_true, y_pred = [3, -0.5, 2, 7], [2.5, 0.0, 2, 8]
r2_score(y_true, y_pred)问题
- 目标是什么?
- 使用什么评价指标?
- 提升多少才算真正的提升?
- 指标采用平均值,基于评价指标满足高斯分布的假设,那么评价指标是否满足高斯分布
sklearn 评价指标
 后记:
后记:
在做关于机器学习的项目时,首先要正确分析和预处理数据;然后理清楚问题,选择合适的模型进行求解;最后选择合适的评估指标进行模型、算法、结果的评估。