在centos6.5上hadoop python实例统计英文单词
linux上的单词删选实例
安装的是centos6.5系统,搭建hadoop集群
统计一篇文章中英文单词的数量
统计1.txt中单词的数量,新建一个mds目录,把文件移到此目录下

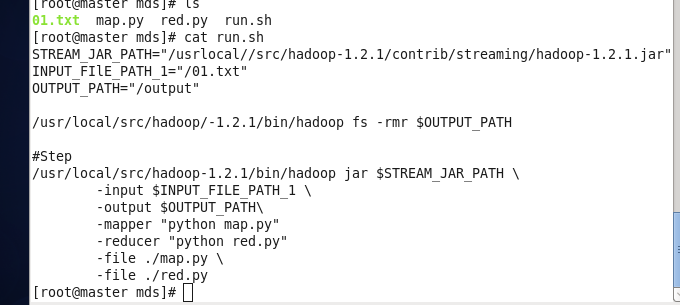
a.写一个shell脚本
新建一个run.sh文件并编辑HADOOP_CMD=”/usr/local/src/hadoop-1.2.1/bin/hadoop”
STREAM_JAR_PATH=”/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar”
INPUT_FILE_PATH_1=”/The_Man_of_Property.txt” //这是配置mapreduce的输入
OUTPUT_PATH=”/output” //指定一个输出路径OUTPUT_PAHT
Step .
STREAM_JAR_PATH\ //输入
-input OUTPUT_PATH \
-mapper “python map.py” \
-reduce “python red.py” \
-file ./map.py \
-fiel ./red.py
脚本如圖所示:
执行 ./bin.hadoop fs -ls 查看hdfs的文件
把需要操作的文件01.txt放到文件系统中
上传:
hadoop fs -put 01.txt / 上传文件
hadoop环境变量需要配置 ,并在权限下操作root
hadoop fs -ls / 查看文件列表 可以查看到01.txt则上传成功

不多说,直接运行脚本
bash run.sh
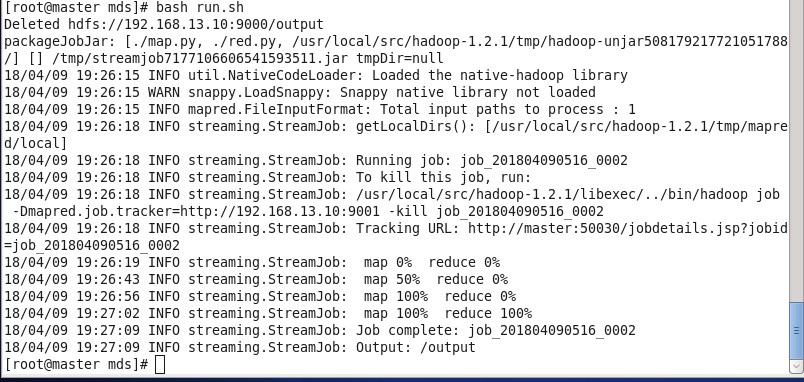
打开浏览器查看hdfs (浏览器是linux自带,window浏览器需要在在电脑配置)
浏览器 master:50030

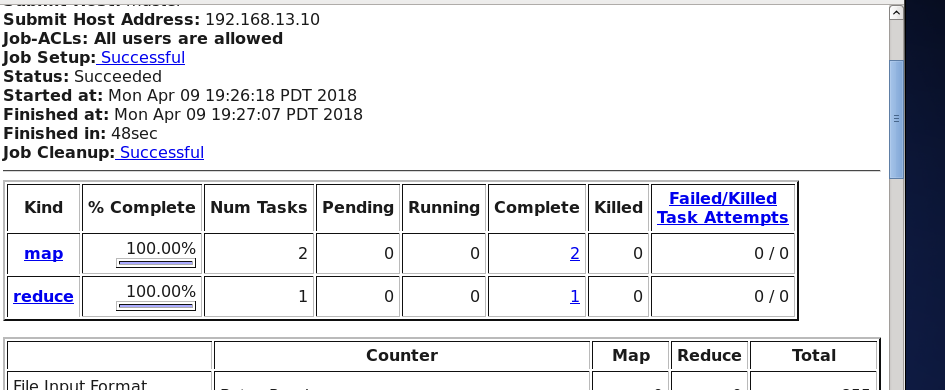
点击查看运行成功
我们可以把输出的结果当到本地
查看hdfs输出目录
hadoop fs -ls




查看输出结果 成功