文章目录
前言
在免密登录都做好之后,再编写两个脚本以便提高我们管理集群的效率
分发指令
这一个脚本可以让我们在一台机器上操作的指令在集群中都生效,避免我们一台台机器去操作
需求分析
即便是配了免密登录,没有一个脚本来分发指令,我还是得一一操作每台机器,如下图

我所希望实现的效果就是通过一个脚本只输一次指令,让他在每台机器都生效
完整代码
先给出完整代码有兴趣的可以继续看看代码的详解
#!/bin/bash
# 判断参数个数
if [ $# -lt 1 ]
then
echo "There is no commond to excute!"
exit
fi
# 获得当前用户
LOGIN_USER_NAME=`whoami`
# 获得主机名
for CLU_HOSTS in node107 node108 node109
do
echo "----------------$CLU_HOSTS-------------------"
# 拼凑指令
ssh $LOGIN_USER_NAME@$CLU_HOSTS $*
done
新建脚本文件
注意在root下新建
vi /bin/xcall
第一行写解释器
#!/bin/bash
退出来一下,修改权限
chmod 777 xcall

基础版已经装好vim,用vim打开,编程起来应该更舒服
代码详解
我们要做的就是拼凑ssh 用户@主机名 指令循环执行即可,其中用户就是当前用户,主机名可以列在数组中进行循环,指令通过参数传来
获得参数
$#获得参数个数,$*获得字符串类型的参数,$@获得数组类型的参数
为了脚本更健壮,先用参数个数做一个判断
# 判断参数个数
if [ $# -lt 1 ]
then
echo "There is no commond to excute!"
exit
fi
# 获得字符串类型参数
echo $*
保存退出,测试一下


获得当前用户
接着添加
# 获得当前用户
LOGIN_USER_NAME=`whoami`
echo $LOGIN_USER_NAME
边写边测试

获得所有主机名
我在主机命名时遵循了一定规律,所以这里可以用变量自增来循环,这样在机器多起来时比较方便
# 获得主机名
for((i=107;i<110;i++))
do
echo "----------------node$i-------------------"
done
不过我采取另一种更通用方法,列出所有的主机名来循环
# 获得主机名
for CLU_HOSTS in node107 node108 node109
do
echo "----------------$CLU_HOSTS-------------------"
done
再测试一下
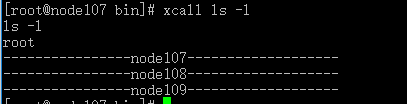
拼凑指令
在获得了所有需要的信息之后我们就可以来拼凑指令了
ssh $LOGIN_USER_NAME@$CLU_HOSTS $*
删除之前测试打印的语句

效果展示

分发文件
有时候需要让一个文件修改的内容在集群都生效,为了避免一一去修改的麻烦可以准备一个分发文件的脚本
rsync
由于scp无法传递软连接,所以需要安装一下rsync来实现软连接的拷贝(rsync与scp差距不大)
yum -y install rsync可以接在刚刚编写的脚本之后xcall yum -y install rsync让每台机器都装上
rsync -rlv 本机文件 用户@主机名:目标路径
完整代码
依旧先给出完整代码
#!/bin/bash
# 判断参数个数
if [ $# -lt 1 ]
then
echo "There is no file to send!"
exit
fi
P=$1
# 获得文件名与路径
FILE_NAME=`basename $P`
FILE_PATH=`dirname $P`
# 获得真实路径
DIR_PATH=`cd -P $FILE_PATH;pwd`
# 获得当前用户
LOGIN_USER_NAME=`whoami`
# 获得主机名
for CLU_HOSTS in node108 node109
do
echo "------------------node$CLU_HOSTS-----------------------"
# 拼凑指令
rsync -rlv $DIR_PATH/$FILE_NAME $LOGIN_USER_NAME@$CLU_HOSTS:$DIR_PATH
done
新建脚本文件
注意在root下新建
vi /bin/xsync
第一行写解释器
#!/bin/bash
退出来一下,修改权限
chmod 777 xsync

代码详解
获取参数、用户与主机名同上不再解释
获得文件名
就是用basename和dirname两个指令即可,但dirname结果不够通用
# 获得参数的文件名及路径
FILE_NAME=`basename $P`
FILE_PATH=`dirname $P`
获得真实路径
主要是针对不同的参数用通用的解决办法,才需要获得真实路径
DIR_PATH=`cd -P $FILE_PATH;pwd`
实际上是两个指令结合的结果,这样一来不论参数是绝对路径还是相对路径还是软连接都能获得真实路径
拼凑指令
rsync -rlv $DIR_PATH/$FILE_NAME $LOGIN_USER_NAME@$CLU_HOSTS:$DIR_PATH
效果展示

如果基础版没有上传jdk、Hadoop就可以用它来分发到集群中,软连接的拷贝主要也就是为了实现这种需求。
搭配使用JPS
这一步是为了xcall能使用jps
1.将jps创建软连接到用户的bin目录下

2.分发jps使得集群中每台电脑用户的bin下都有

3.查看一下

4.使用jps

现在有没有感觉这两个脚本非常好用!