1:SVD算法
1.1 算法原理
奇异值分解(SVD)是线性代数中一种重要的矩阵分解。假设M是一个m×n阶矩阵,其中的元素全部属于域K,也就是实数域或复数域。如此则存在一个分解使得
其中U是m×m阶酉矩阵;Σ是m×n阶非负实数对角矩阵;而V*,即V的共轭转置,是n×n阶酉矩阵。这样的分解就称作M的奇异值分解。Σ对角线上的元素Σi,i即为M的奇异值。常见的做法是将奇异值由大而小排列。如此Σ便能由M唯一确定了。(虽然U和V仍然不能确定。)
在矩阵M的奇异值分解中
V的列组成一套对M正交输入或分析的基向量,这些向量是MM的特征向量;
U的列组成一套对M的正交输出的基向量,这些向量是MM的特征向量;
Σ对角线上的元素是奇异值,可视为是在输入和输出间进行的标量的‘膨胀控制’,这些是MM及MM的特征值的非负平方根,并与U和V的行向量相对应
奇异值和奇异向量,以及他们与奇异值分解的关系
一个非负实数σ是M的一个奇异值仅当存在Km的单位向量u和Kn的单位向量v如下:
其中向量u和v分别为σ的左奇异向量和右奇异向量。
对于任意的奇异值分解
矩阵Σ的对角线上的元素等于M的奇异值. U和V的列分别是奇异值中的左、右奇异向量。因此,上述定理表明:
一个m×n的矩阵至多有p = min(m,n)个不同的奇异值;
总能在Km中找到由M的左奇异向量组成的一组正交基U,;
总能在Kn找到由M的右奇异向量组成的一组正交基V,。
如果对于一个奇异值,可以找到两组线性无关的左(右)奇异向量,则该奇异值称为简并的(或退化的)。
非退化的奇异值在最多相差一个相位因子
(若讨论限定在实数域内,则最多相差一个正负号)的意义下具有唯一的左、右奇异向量。因此,如果M的所有奇异值都是非退化且非零,则除去一个可以同时乘在 U , V上的任意的相位因子外, M的奇异值分解唯一。
根据定义,退化的奇异值具有不唯一的奇异向量。因为,如果u1和u2为奇异值σ的两个左奇异向量,则它们的任意归一化线性组合也是奇异值σ一个左奇异向量,右奇异向量也具有类似的性质。因此,如果M具有退化的奇异值,则它的奇异值分解是不唯一的。
1.2 编程实现
先对cifar-10数据集进行奇异值分解,然后分别选择10,50,100维特征重构数据集(本实验中是一个1000*3072的矩阵)
重构出的矩阵reconstruct为
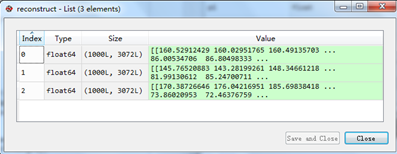 均方误差为
均方误差为
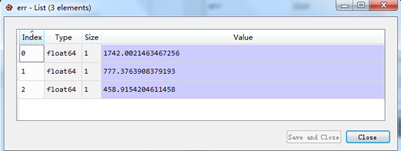 10维特征重建的均方误差为1742,50维特征重建的均方误差为777,100维特征重建的均方误差为458
10维特征重建的均方误差为1742,50维特征重建的均方误差为777,100维特征重建的均方误差为458
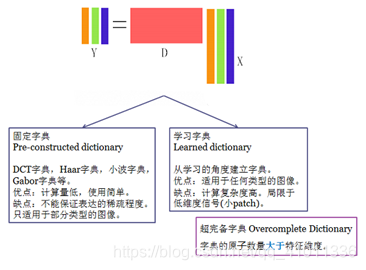
2:字典学习算法
2.1 算法原理
算法求解思路为交替迭代的进行稀疏编码和字典更新两个步骤. K-SVD在构建字典步骤中,K-SVD不仅仅将原子依次更新,对于原子对应的稀疏矩阵中行向量也依次进行了修正. 不像MOP,K-SVD不需要对矩阵求逆,而是利用SVD数学分析方法得到了一个新的原子和修正的系数向量.
固定系数矩阵X和字典矩阵D,字典的第k个原子为dk,同时dk对应的稀疏矩阵为X中的第k个行向量xkT. 假设当前更新进行到原子dk,样本矩阵和字典逼近的误差为:
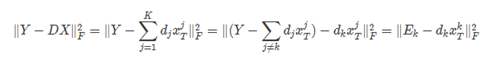 在得到当前误差矩阵
后,需要调整
和
,使其乘积与Ek的误差尽可能的小.如果直接对
和
进行更新,可能导致
不稀疏. 所以可以先把原有向量
中零元素除,保留非零项,构成向量
,然后从误差矩阵
中取出相应的列向量,构成矩阵
. 对
进行SVD分解,有
=
,由U的第一列更新dk,由V的第一列乘以Δ(1,1)所得结果更新
在得到当前误差矩阵
后,需要调整
和
,使其乘积与Ek的误差尽可能的小.如果直接对
和
进行更新,可能导致
不稀疏. 所以可以先把原有向量
中零元素除,保留非零项,构成向量
,然后从误差矩阵
中取出相应的列向量,构成矩阵
. 对
进行SVD分解,有
=
,由U的第一列更新dk,由V的第一列乘以Δ(1,1)所得结果更新
2.2 编程实现
在编程过程中,使用K-SVD算法实现字典学习,由于实验数据集太大,测试实在太费时间,故首先选择一张图片来验证代码的正确性。具体做法是将算法应用于图片上,学习得到字典D和稀疏矩阵X,而后利用D和X矩阵重建图片,与原始图片比较。
选择一张苏州水乡的图片,当选择原子数n_components为10时,重建出来的图片失去了原来的样貌,如下图所示:
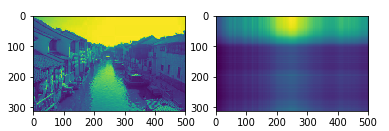
考虑增加原子数,将其增加到30时,发现重建效果较之前好得多,如下
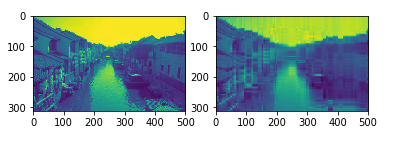
这也与我们的预期符合,用于拟合的原子数越多,失真当然越小,
以上基本验证了代码的正确性
分析:为什么需要30个原子才能较好的重构呢?
这里我在代码中设置了最大迭代次数max_iter为50,为了保证程序不会运行太长时间,这是一种折中的办法,因为考虑时间效率,另外在自己的电脑上跑,如果设置得很大,运行一次实在费劲。然而,节省时间就会导致重构准确性受到影响,50次迭代或许并未达到最优更新,但是不得不停止,倘若适当增大迭代上限,重构效果更好
再将编写好的代码用于实验数据集
做法相同,只是由于实验数据为10003072,含有1000张图片,这里直接对这个10003072矩阵进行字典学习和稀疏编码,而后重构比较计算均方误差
1) 当取原子数为50时,均方误差为907即平均每个元素偏离30左右
2) 当取原子数为100时,均方误差为562
比较SVD和字典学习方法的图像重建均方误差如下表

3:附录(代码)
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 23 22:29:17 2018
@author: wbw
"""
import numpy as np
import matplotlib.pyplot as plt
from numpy import *
import scipy.io as sio
import random
from sklearn import linear_model
import scipy.misc
from PIL import Image
class KSVD(object):
def __init__(self, n_components, max_iter=100, tol=1e-6,n_nonzero_coefs=None):
"""
稀疏模型Y = DX,Y为样本矩阵,使用KSVD动态更新字典矩阵D和稀疏矩阵X
:param n_components: 字典所含原子个数(字典的列数)
:param max_iter: 最大迭代次数
:param tol: 稀疏表示结果的容差
:param n_nonzero_coefs: 稀疏度
"""
self.dictionary = None
self.sparsecode = None
self.max_iter = max_iter
self.tol = tol
self.n_components = n_components
self.n_nonzero_coefs = n_nonzero_coefs
def _initialize(self, y):
"""
初始化字典矩阵
"""
u, s, v = np.linalg.svd(y)
self.dictionary = u[:, :self.n_components]
def _update_dict(self, y, d, x):
"""
使用KSVD更新字典的过程
"""
for i in range(self.n_components):
index = np.nonzero(x[i, :])[0]#选出Xk中非零的元素下标
if len(index) == 0:
continue
d[:, i] = 0
r = (y - np.dot(d, x))[:, index]
u, s, v = np.linalg.svd(r, full_matrices=False)
d[:, i] = u[:, 0].T
x[i, index] = s[0] * v[0, :]
return d, x
def fit(self, y):
"""
KSVD迭代过程
"""
self._initialize(y)
for i in range(self.max_iter):
x = linear_model.orthogonal_mp(self.dictionary, y, n_nonzero_coefs=self.n_nonzero_coefs)
e = np.linalg.norm(y - np.dot(self.dictionary, x))
if e < self.tol:
break
self._update_dict(y, self.dictionary, x)
self.sparsecode = linear_model.orthogonal_mp(self.dictionary, y, n_nonzero_coefs=self.n_nonzero_coefs)
return self.dictionary, self.sparsecode
def loadData(file):
#file='G:/lecture of grade one/pattern recognition/data/train_data.mat'
trainImg=sio.loadmat(file)
#print trainImg["Data"][1,:]
return trainImg
def esErrSvd(Img,reconstruct):
m,n=Img['Data'].shape
esErr=[0,0,0]
for k in range(3):
esErr[k]=0
for i in range(m):
for j in range(n):
esErr[k]+=(Img['Data'][i][j]-reconstruct[k][i][j])**2
esErr[k]/=(m*n)
return esErr
def esErrDic(data,recons):
m,n=data.shape
esErr=0
for i in range(m):
for j in range(n):
esErr+=(data[i][j]-recons[i][j])**2
return esErr/(m*n)
def svdReconstruct(u,sigma,vt):
num_of_singular = [10,50,100]
reconstruct=[]
plt.figure()
plt.title('A=U*S*Vh')
for index,i in enumerate(num_of_singular) :
reconstruct.append(np.dot(u[:,:i]*sigma[:i],vt[:i,:])) # 注意这个重构的矩阵运算
plt.subplot(1,len(num_of_singular),index+1)
plt.xticks([])
plt.yticks([])
plt.title("Num of Singular :{}".format(i))
plt.imshow(reconstruct[index],cmap=plt.cm.gray)
return reconstruct
if __name__ == '__main__':
file='G:/lecture of grade one/pattern recognition/trial_two/train_data2_807802844.mat'
Img=loadData(file)
#SVD
u,sigma,vt=linalg.svd(Img['Data'])
reconstruct=svdReconstruct(u,sigma,vt)
err=esErrSvd(Img,reconstruct)
'''
#字典学习
ksvd = KSVD(100)
dictionary, sparsecode = ksvd.fit(Img['Data'])
recons=dictionary.dot(sparsecode)
err=esErrDic(Img['Data'],recons)
'''
'''
#验证字典学习代码KSVD的正确性
image =Image.open('/home/swh/Downloads/scene.jpeg')
image = np.array(image)
image=image[:,:,0]
im_ascent = image.astype('float32')
#im_ascent = scipy.misc.ascent().astype(np.float)
ksvd = KSVD(30)
dictionary, sparsecode = ksvd.fit(im_ascent)
plt.figure()
plt.subplot(1, 2, 1)
plt.imshow(im_ascent)
plt.subplot(1, 2, 2)
recon=dictionary.dot(sparsecode)
plt.imshow(recon)
plt.show()
'''