版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/leadingsci/article/details/89294462
文章目录
6.1 列选择
6.1.1 选择某一列/某几列
df = pd.read_csv(r"C:\Users\leadi\Python\01.python\input\train-pivot.csv",encoding="gbk")
df
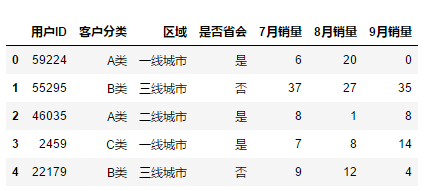
如果选择某一列,只需要传入一个列名,如果选择某几列,则传入多个列名,传到list中
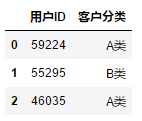
df["用户ID"]
输出:
0 59224
1 55295
2 46035
3 2459
4 22179
Name: 用户ID, dtype: int64
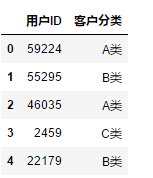
df[["用户ID","客户分类"]]
6.1.2 选择连续的某吉列
iloc
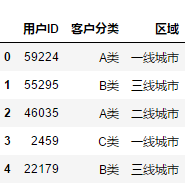
# 选择前3列
df.iloc[:,0:3]
6.2 行选择
6.2.1 选择某一行/某几行
- loc 显式索引
- iloc 隐式索引
# 选择索引0
df.iloc[0]
输出
用户ID 59224
客户分类 A类
区域 一线城市
是否省会 是
7月销量 6
8月销量 20
9月销量 0
Name: 0, dtype: object
# 也是0行
df.iloc[0:1]

# 选择连续2行
df.iloc[0:2]
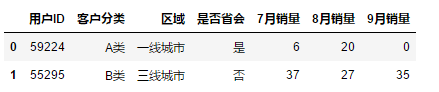
# 选择跳跃2行
df.iloc[[2,3]]
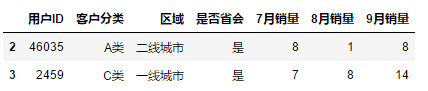
# 语法报错,连续行+ 跳跃行
df.iloc[[1:2,3]]
显式
# 根据行索引名选择
df.loc[2]
df.loc[[2,3]]
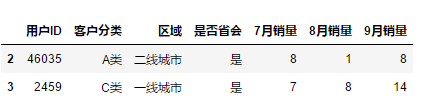
6.2.2 选择连续的某几行
# 选择连续2行
df.iloc[0:2]
6.2.3 选择满足条件的行
df[df["7月销量"]>10]

6.3 行列同时选择
6.3.1 普通索引+ 普通索引选择指定的行或列
将索引放在列表中,
如果选择仅行,则为第一个列表;1个[选择]
如果选择为仅列,则为[[列名]],第二个列表;两个[[选择]]
df.loc[[1,2],["用户ID","客户分类"]]
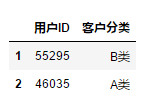
6.3.2 位置索引 + 位置索引选择指定的行或列
df.iloc[[1,2],[0,1]]
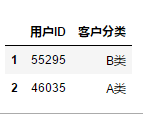
6.3.3 布尔索引+普通索引选择指定的行和列
先对表进行布尔索引选择行,然后普通索引,选择列
df[df["7月销量"]<10][["用户ID","客户分类"]]
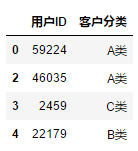
6.3.4 切片索引+ 切片索引选择指定的行和列
df.iloc[0:2,1:2]
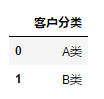
6.3.5 切片索引+ 普通索引选择指定的行和列
交叉索引
.ix is deprecated. Please use——已被弃用
.loc for label based indexing or
.iloc for positional indexing
df.ix[0:2,["用户ID","客户分类"]]