【声明】1.本博文转载自作者:山上有只羊M
附上原文链接:https://blog.csdn.net/shanshangyouzhiyangM/article/details/84943011
2.感谢博主总结的宝贵知识
3.仅为个人学习使用,无其他用途
几个概念
1)正确率(accuracy)
正确率是我们最常见的评价指标,accuracy = (TP+TN)/(P+N),这个很容易理解,就是被分对的样本数除以所有的样本数,通常来说,正确率越高,分类器越好;
2)错误率(error rate)
错误率则与正确率相反,描述被分类器错分的比例,error rate = (FP+FN)/(P+N),对某一个实例来说,分对与分错是互斥事件,所以accuracy =1 - error rate;
3)灵敏度(sensitive)
sensitive = TP/P,表示的是所有正例中被分对的比例,衡量了分类器对正例的识别能力;
4)特效度(specificity)
specificity = TN/N,表示的是所有负例中被分对的比例,衡量了分类器对负例的识别能力;
5)精度(precision)
精度是精确性的度量,表示被分为正例的示例中实际为正例的比例,precision=TP/(TP+FP);
6)召回率(recall)
召回率是覆盖面的度量,度量有多个正例被分为正例,recall=TP/(TP+FN)=TP/P=sensitive,可以看到召回率与灵敏度是一样的。
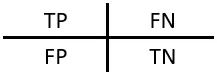
TP(True Positive): 真实为0,预测也为0
FN(False Negative): 真实为0,预测为1
FP(False Positive): 真实为1,预测为0
TN(True Negative): 真实为1,预测也为1
FN:False Negative,被判定为负样本,但事实上是正样本。
FP:False Positive,被判定为正样本,但事实上是负样本。
TN:True Negative,被判定为负样本,事实上也是负样本。
TP:True Positive,被判定为正样本,事实上也是正样本。
accuracy(总体准确率)
:分类模型总体判断的准确率(包括了所有class的总体准确率)
precision(单一类准确率) : 预测为0的准确率
回归率 : 真实为0的准确率
真实为1的准确率:
预测为1的准确率:
对于某个分类,综合了Precision和Recall的一个判断指标,F1-Score的值是从0到1的,1是最好,0是最差:
另外一个综合Precision和Recall的标准,F1-Score的变形:
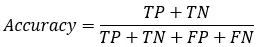
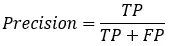
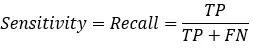
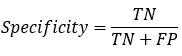
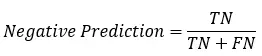

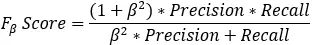
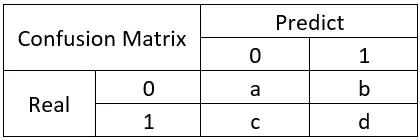
混淆矩阵
在机器学习中尤其是统计分类中,混淆矩阵(confusion matrix),也被称为错误矩阵(error matrix)。
矩阵的每一列表达了分类器对于样本的类别预测,二矩阵的每一行则表达了版本所属的真实类别
之所以叫做’混淆矩阵‘,是因为能够很容易的看到机器学习有没有将样本的类别给混淆了。
接着二分类的举例子:
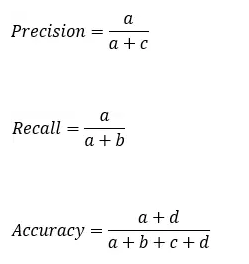
举一个三分类的例子:
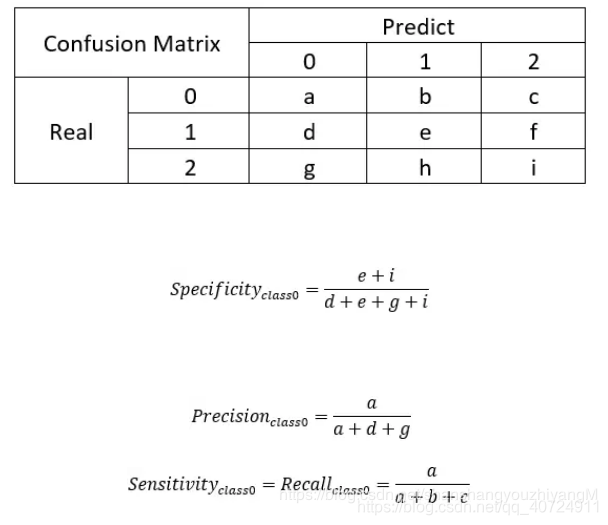
举例子:

top1 和top5的计算
top1----- 就是你预测的label取最后概率向量里面最大的那一个作为预测结果,如过你的预测结果中概率最大的那个分类正确,则预测正确。否则预测错误
top5----- 就是最后概率向量最大的前五名中,只要出现了正确概率即为预测正确。否则预测错误。
1 在每次迭代中计算top1和top5,然后求平均
计算代码:
输入是模型输出(batch_size×num_of_class),目标label(num_of_class向量),元组(分别向求top几)
def accuracy(output, target, topk=(1,)):
"""Computes the precision@k for the specified values of k"""
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True) # 返回最大的k个结果(按最大到小排序)
pred = pred.t() # 转置
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].view(-1).float().sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
return res
**计算代码的使用:**该代码中计算了top1和top5
def validate(val_loader, model, criterion):
batch_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
top5 = AverageMeter()
# switch to evaluate mode
model.eval()
for i, (input, target) in enumerate(val_loader):
target = target.cuda(async=True)
input_var = torch.autograd.Variable(input, volatile=True)
target_var = torch.autograd.Variable(target, volatile=True)
# compute output
output = model(input_var)
loss = criterion(output, target_var)
# measure accuracy and record loss
prec1, prec5 = accuracy(output.data, target, topk=(1, 5))
losses.update(loss.data[0], input.size(0))
top1.update(prec1[0], input.size(0))
top5.update(prec5[0], input.size(0))
return top1.mean()
2 在每次迭代中计算混淆矩阵,然后求top1(即为准确率)
!!!需要注意,我们平时说的top1就是准确率
def val(model, dataloader):
'''
计算模型在验证集上的准确率等信息,用以辅助训练
'''
opt = DefaultConfig()
# 把模型设为验证模式
model.eval()
confusion_matrix = meter.ConfusionMeter(opt.num_of_class)
for ii, data in enumerate(dataloader):
input, label = data
val_input = Variable(input, volatile=True)
val_label = Variable(label.long(), volatile=True)
if opt.use_gpu:
val_input = val_input.cuda()
val_label = val_label.cuda()
score = model(val_input)
confusion_matrix.add(score.data.squeeze(), label.long())
# 把模型恢复为训练模式
model.train()
cm_value = confusion_matrix.value()
accuracy = 0
for i in range(opt.num_of_class):
accuracy += 100. * cm_value[i][i] / (cm_value.sum())
return confusion_matrix, accuracy
3 每一类的准确率
计算每一类的分类精度,进而求总体的平均精度是分类问题很常用的评价指标,当我们计算出混淆矩阵之后,需要对混淆矩阵进行量化分析,最明显的指标就是计算分类精度,下面提供一种计算方面,使用sk-learn的api
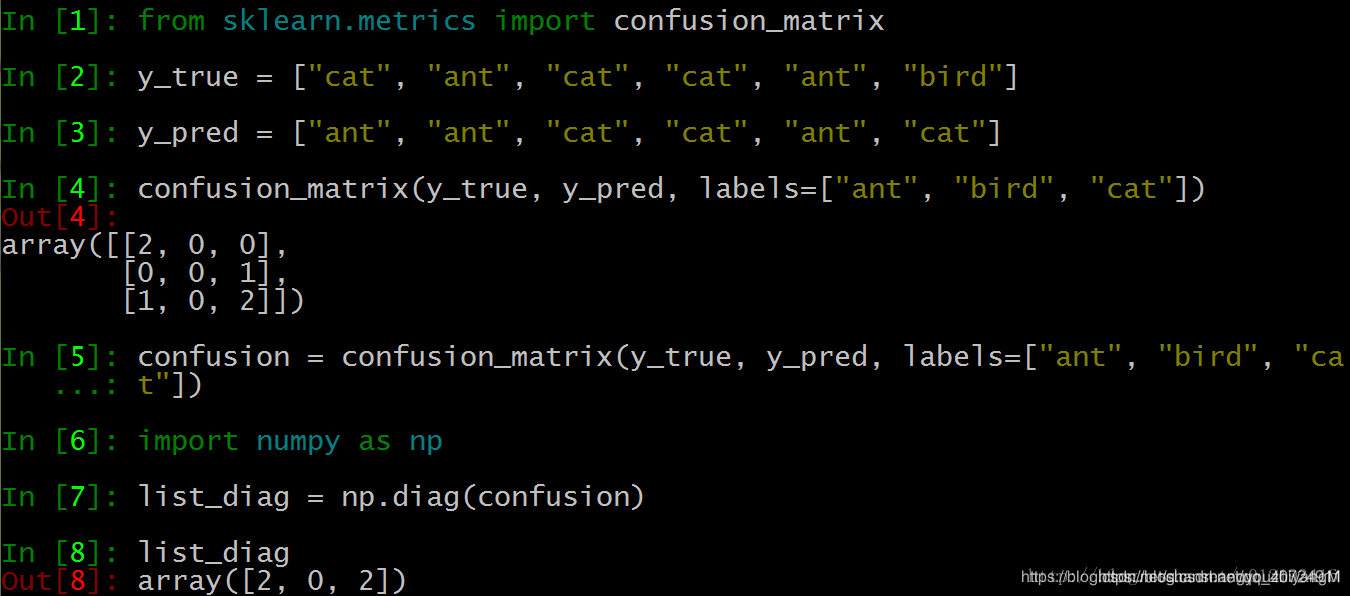

np.diag是将对角线的值取出来,也就是正确分类的样本数的分布,axis=1,是行维度,实际就是预测样本数分布,np.sum就是将预测的每类样本数进行求和。
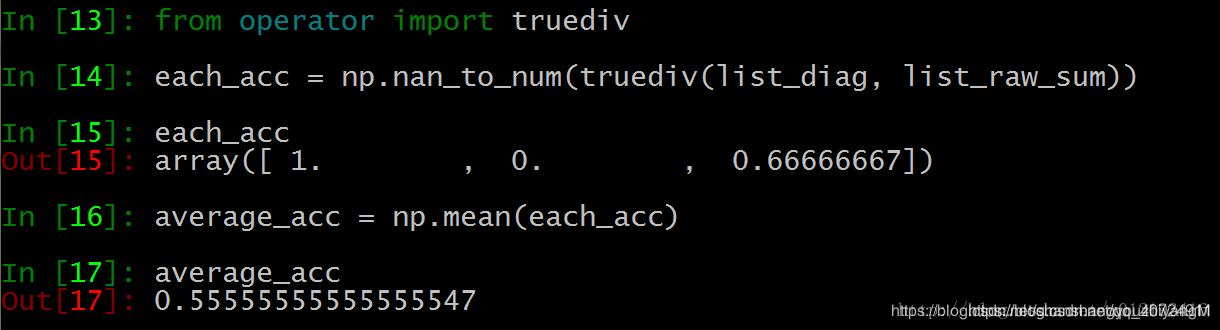
nan_to_num是将部分真除之后会出现nan的数转成0值,从each_acc可以看出每类的分类精度,第一类是1,第二个bird没有正确分类的个数,第三个是2/3,得出每类精度之后再求平均精度。
总结
Specificity,Recall,Precision等只是计算某一分类的特性,而Accuracy和F1-Score这些是判断分类模型总体的标准。我们可以根据实际需要,得出不同的效果。