1. 简要讲述hadoop和spark的shuffle相同和差异?
1)从高层次的的角度来看,两者并没有大的差别。
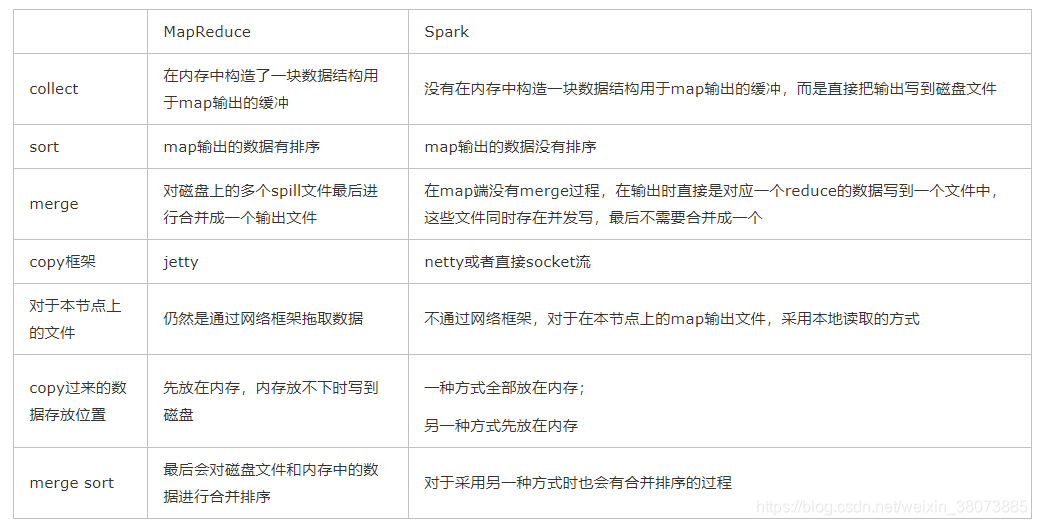
它都是将 mapper(Spark 里是 ShuffleMapTask)的输出进行 partition,不同的 partition 送到不同的 reducer(Spark 里 reducer 可能是下一个 stage 里的 ShuffleMapTask,也可能是 ResultTask)。Reducer 以内存作缓冲区,边 shuffle 边 aggregate 数据,等到数据 aggregate 好以后进行 reduce() (Spark 里可能是后续的一系列操作)。
2)从低层次的角度来看,两者差别不小。
Hadoop MapReduce 是 sort-based,进入 combine() 和 reduce() 的 records 必须先 sort。这样的好处在于 combine/reduce() 可以处理大规模的数据,因为其输入数据可以通过外排得到(mapper 对每段数据先做排序,reducer 的 shuffle 对排好序的每段数据做归并)。
目前的 Spark 默认选择的是 hash-based,通常使用 HashMap 来对 shuffle 来的数据进行 aggregate,不会对数据进行提前排序。如果用户需要经过排序的数据,那么需要自己调用类似 sortByKey() 的操作;如果你是Spark 1.1的用户,可以将spark.shuffle.manager设置为sort,则会对数据进行排序。在Spark 1.2中,sort将作为默认的Shuffle实现。
3)从实现角度来看,两者也有不少差别。
Hadoop MapReduce 将处理流程划分出明显的几个阶段:map(), spill, merge, shuffle, sort, reduce() 等。每个阶段各司其职,可以按照过程式的编程思想来逐一实现每个阶段的功能。在 Spark 中,没有这样功能明确的阶段,只有不同的 stage 和一系列的 transformation(),所以 spill, merge, aggregate 等操作需要蕴含在 transformation() 中。
如果我们将 map 端划分数据、持久化数据的过程称为 shuffle write,而将 reducer 读入数据、aggregate 数据的过程称为 shuffle read。那么在 Spark 中,问题就变为怎么在 job 的逻辑或者物理执行图中加入 shuffle write 和 shuffle read 的处理逻辑?以及两个处理逻辑应该怎么高效实现?
Shuffle write由于不要求数据有序,shuffle write 的任务很简单:将数据 partition 好,并持久化。之所以要持久化,一方面是要减少内存存储空间压力,另一方面也是为了 fault-tolerance。
2. Spark的工作机制?
这个知识点 南国在之前的博客中有详细讲述过,这里简要提一下。
用户在client端提交作业后,会由Driver运行main方法并创建spark context上下文。
执行rdd算子,形成dag图输入dagscheduler,按照rdd之间的依赖关系划分stage输入task scheduler。 task scheduler会将stage划分为task set分发到各个节点的executor中执行。
3. cache和pesist的区别
1)cache和persist都是用于将一个RDD进行缓存的,这样在之后使用的过程中就不需要重新计算了,可以大大节省程序运行时间;
2) cache只有一个默认的缓存级别MEMORY_ONLY ,cache调用了persist,而persist可以根据情况设置其它的缓存级别;
3)executor执行的时候,默认60%做cache,40%做task操作,persist最根本的函数,最底层的函数。
4. 理解Spark的shuffle过程(重要!!!)
简单来说,Spark的shuffle过程主要是以下几个阶段:
1.Shuffle Writer:
Spark丰富了任务类型,有些任务之间数据流转不需要通过Shuffle,但是有些任务之间还是需要通过Shuffle来传递数据,比如wide dependency的groupByKey。
Spark中需要Shuffle输出的Map任务会为每个Reduce创建对应的bucket,Map产生的结果会根据设置的partitioner得到对应的bucketId,然后填充到相应的bucket中去。每个Map的输出结果可能包含所有的Reduce所需要的数据,所以每个Map会创建R个bucket(R是reduce的个数),M个Map总共会创建M*R个bucket。
Map创建的bucket其实对应磁盘上的一个文件,Map的结果写到每个bucket中其实就是写到那个磁盘文件中,这个文件也被称为blockFile,是Disk Block Manager管理器通过文件名的Hash值对应到本地目录的子目录中创建的。每个Map要在节点上创建R个磁盘文件用于结果输出,Map的结果是直接输出到磁盘文件上的,100KB的内存缓冲是用来创建Fast Buffered OutputStream输出流。这种方式一个问题就是Shuffle文件过多。
针对上述Shuffle过程产生的文件过多问题,Spark有另外一种改进的Shuffle过程:consolidation Shuffle,以期显著减少Shuffle文件的数量。在consolidation Shuffle中每个bucket并非对应一个文件,而是对应文件中的一个segment部分。Job的map在某个节点上第一次执行,为每个reduce创建bucket对应的输出文件,把这些文件组织成ShuffleFileGroup,当这次map执行完之后,这个ShuffleFileGroup可以释放为下次循环利用;当又有map在这个节点上执行时,不需要创建新的bucket文件,而是在上次的ShuffleFileGroup中取得已经创建的文件继续追加写一个segment;当前次map还没执行完,ShuffleFileGroup还没有释放,这时如果有新的map在这个节点上执行,无法循环利用这个ShuffleFileGroup,而是只能创建新的bucket文件组成新的ShuffleFileGroup来写输出。
2.Shuffle Fetcher
Reduce去拖Map的输出数据,Spark提供了两套不同的网络拉取数据框架:通过socket连接去取数据;使用netty框架去取数据。
每个节点的Executor会创建一个BlockManager,其中会创建一个BlockManagerWorker用于响应请求。当Reduce的GET_BLOCK的请求过来时,读取本地文件将这个blockId的数据返回给Reduce。如果使用的是Netty框架,BlockManager会创建ShuffleSender用于发送Shuffle数据。
并不是所有的数据都是通过网络读取,对于在本节点的Map数据,Reduce直接去磁盘上读取而不再通过网络框架。
Reduce拖过来数据之后以什么方式存储呢?Spark Map输出的数据没有经过排序,Spark Shuffle过来的数据也不会进行排序,Spark认为Shuffle过程中的排序不是必须的,并不是所有类型的Reduce需要的数据都需要排序,强制地进行排序只会增加Shuffle的负担。Reduce拖过来的数据会放在一个HashMap中,HashMap中存储的也是<key, value>对,key是Map输出的key,Map输出对应这个key的所有value组成HashMap的value。Spark将Shuffle取过来的每一个<key, value>对插入或者更新到HashMap中,来一个处理一个。HashMap全部放在内存中。
Shuffle取过来的数据全部存放在内存中,对于数据量比较小或者已经在Map端做过合并处理的Shuffle数据,占用内存空间不会太大,但是对于比如group by key这样的操作,Reduce需要得到key对应的所有value,并将这些value组一个数组放在内存中,这样当数据量较大时,就需要较多内存。
当内存不够时,要不就失败,要不就用老办法把内存中的数据移到磁盘上放着。Spark意识到在处理数据规模远远大于内存空间时所带来的不足,引入了一个具有外部排序的方案。Shuffle过来的数据先放在内存中,当内存中存储的<key, value>对超过1000并且内存使用超过70%时,判断节点上可用内存如果还足够,则把内存缓冲区大小翻倍,如果可用内存不再够了,则把内存中的<key, value>对排序然后写到磁盘文件中。最后把内存缓冲区中的数据排序之后和那些磁盘文件组成一个最小堆,每次从最小堆中读取最小的数据,这个和MapReduce中的merge过程类似。
这部分内容参考博客:Spark的Shuffle过程介绍
5. 数据本地性
在Spark中,数据本地性是指具体的task运行在哪台机器上,DAG划分stage的时候确定的。
6. Spark master使用zookeeper进行HA的,有哪些元素保存在Zookeeper ?
答:Spark通过这个参数spark.deploy.zookeeper.dir指定master元数据在zookeeper中保存的位置,包括Worker,Driver和Application以及Executors。standby节点要从zk中,获得元数据信息,恢复集群运行状态,才能对外继续提供服务,作业提交资源申请等,在恢复前是不能接受请求的。另外,Master切换需要注意2点
1)在Master切换的过程中,所有的已经在运行的程序皆正常运行!因为Spark Application在运行前就已经通过Cluster Manager获得了计算资源,所以在运行时Job本身的调度和处理和Master是没有任何关系的!
2) 在Master的切换过程中唯一的影响是不能提交新的Job:一方面不能够提交新的应用程序给集群,因为只有Active Master才能接受新的程序的提交请求;另外一方面,已经运行的程序中也不能够因为Action操作触发新的Job的提交请求;
注意:Spark Master HA主从切换的过程不会影响集群中已有作业的运行,因为在程序运行之前,已经申请过资源了,driver和Executor通讯,不需要和master进行通讯的。
7. 介绍一下join操作优化经验
join其实常见的就分为两类: map-side join 和 reduce-side join。
当大表和小表join时,用map-side join能显著提高效率。将多份数据进行关联是数据处理过程中非常普遍的用法,不过在分布式计算系统中,这个问题往往会变的非常麻烦,因为框架提供的 join 操作一般会将所有数据根据 key 发送到所有的 reduce 分区中去,也就是 shuffle 的过程。造成大量的网络以及磁盘IO消耗,运行效率极其低下,这个过程一般被称为 reduce-side-join。如果其中有张表较小的话,我们则可以自己实现在 map 端实现数据关联,跳过大量数据进行 shuffle 的过程,运行时间得到大量缩短,根据不同数据可能会有几倍到数十倍的性能提升。
备注:这个题目面试中非常非常大概率见到,务必搜索相关资料掌握,这里抛砖引玉。
8. 不启动Spark集群Master和worker服务,可不可以运行Spark程序?
可以,只要资源管理器第三方管理就可以,如由yarn管理,spark集群不启动也可以使用spark;
Spark集群启动的是work和master,这个其实就是资源管理框架,yarn中的resourceManager相当于master,NodeManager相当于worker,做计算是Executor,和spark集群的work和manager可以没关系,归根接底还是JVM的运行,只要所在的JVM上安装了spark就可以。
9. Spark on Yarn模式有几种类型以及Yarn集群的优点
Yarn集群有两种模式:
- Yarn-Client模式:driver运行在本地客户端,负责调度Application,会与Yarn集群长生大量的网络通信,从而导致网卡流量激增。它的好处是执行时可在本地看到所有log,便于调试。因而它一般用于测试环境。
- Yarn-Cluster模式:driver语行在NodeManager,每次运行都是随机分配到NodeManager机器上去,不会有网卡流量激增的问题。但他的缺点是:本地提交时看不到log,只能通过Yarn Application-log application id命令来查看。
Yarn集群的优点:
1)与其他计算框架共享集群资源(eg.Spark框架与MapReduce框架同时运行,如果不用Yarn进行资源分配,MapReduce分到的内存资源会很少,效率低下);资源按需分配,进而提高集群资源利用等。
2)相较于Spark自带的Standalone模式,Yarn的资源分配更加细致
3)Application部署简化,例如Spark,Storm等多种框架的应用由客户端提交后,由Yarn负责资源的管理和调度,利用Container作为资源隔离的单位,以它为单位去使用内存,cpu等。
4)Yarn通过队列的方式,管理同时运行在Yarn集群中的多个服务,可根据不同类型的应用程序负载情况,调整对应的资源使用量,实现资源弹性管理。
10. 谈谈你对Yarn中container的理解
1)Container作为资源分配和调度的基本单位,其中封装了的资源如内存,CPU,磁盘,网络带宽等。 目前yarn仅仅封装内存和CPU
2)Container由ApplicationMaster向ResourceManager申请的,由ResouceManager中的资源调度器异步分配给ApplicationMaster
3)Container的运行是由ApplicationMaster向资源所在的NodeManager发起的,Container运行时需提供内部执行的任务命令。
运行在yarn中Application有以下两种类型:
1)运行ApplicationMaster的Container:这是由ResourceManager(向内部的资源调度器)申请和启动的,用户提交应用程序时,可指定唯一的ApplicationMaster所需的资源;
2)运行各类任务的Container:这是由ApplicationMaster向ResourceManager申请的,并由ApplicationMaster与NodeManager通信以启动之。
11. Spark中的分区
Spark默认有两种分区:hashPartitioner和rangePartitioner
(1) hashPartitioner分区:
对于指定的key,计算其hashCode,并除以分区的个数取余,如果欲数小于0,则用余数+分区的个数,最后返回的值就是这个key所属的分区ID;
它的不足:原始数据不均匀时容易产生数据倾斜,极端情况下 某几个分区的会拥有rdd的所有数据。
(2) rangePartition分区:
范围分区的原理是尽量保证每个分区中数据量的均匀,而且分区与分区之间是有序的。但是分区内的元素是不能保证顺序的。简单而言,将一定范围内的数据映射到某一个分区内。
(3)除上述两个,在Spark中,我们还可以实现自定义分区。自定义分区器的时候继承org.apache.spark.Partitioner类,实现类中的三个方法:
def numPartitions: Int:这个方法需要返回你想要创建分区的个数;
def getPartition(key: Any): Int:这个函数需要对输入的key做计算,然后返回该key的分区ID,范围一定是0到numPartitions-1;
equals():这个是Java标准的判断相等的函数,之所以要求用户实现这个函数是因为Spark内部会比较两个RDD的分区是否一样。
更多详情可看:https://www.iteblog.com/archives/1368.html
12. 谈谈对于Spark中的partition和HDFS中的block二者的理解
1)hdfs中的block是分布式存储的最小单元,等分,可设置冗余,这样设计有一部分磁盘空间的浪费,但是整齐的block大小,便于快速找到、读取对应的内容;
2)Spark中的partition是弹性分布式数据集RDD的最小单元,RDD是由分布在各个节点上的partition组成的。partition是指的spark在计算过程中,生成的数据在计算空间内最小单元,同一份数据(RDD)的partition大小不一,数量不定,是根据application里的算子和最初读入的数据分块数量决定;
3)block位于存储空间,partition位于计算空间,block的大小是固定的、partion大小是不固定的,是从2个不同的角度去看数据。
13. Spark中task有几种类型
Spark中的task有2种类型:
(1) shuffleMapTask类型:它是大多数task(除了Application种最后一个task之外)所属的类型
(2) result task类型:最后一个task所属的类型。
14. consolidate是如何优化Hash shuffle时在map端产生的小文件?
1)consolidate为了解决Hash Shuffle同时打开过多文件导致Writer handler内存使用过大以及产生过多文件导致大量的随机读写带来的低效磁盘IO;
2)consolidate根据CPU的个数来决定每个task shuffle map端产生多少个文件,假设原来有10个task,100个reduce,每个CPU有10个CPU,那么使用hash shuffle会产生10100=1000个文件,conslidate产生1010=100个文件;
备注:consolidate部分减少了文件和文件句柄,但在并行度很高的情况下(task很多时)还是会很多文件。
15. 简要描述Spark写数据的流程
1)RDD调用compute方法,进行指定分区的写入
2)CacheManager中调用BlockManager判断数据是否已经写入,如果未写,则写入
3)BlockManager中数据与其他节点同步
4)BlockManager根据存储级别写入指定的存储层
5)BlockManager向主节点汇报存储状态中
16. RDD的数据结构
一个RDD对象,包含下面5个核心属性:
(1)一个分区列表,每个分区里是RDD的部分数据(或称数据块)
(2)一个依赖列表,存储依赖的其他RDD
(3)一个名为compute的计算函数,用于计算RDD各分区的值
(4)分区器(可选),用于键/值类型的RDD,比如某个RDD是按照散列来分区
(5)计算各分区时优先的位置列表(可选),比如从HDFS上的文件生成RDD时,RDD分区的位置优先选择数据所在的节点,这样可以避免数据移动带来的开销。
以上内容是我平日里学习过程中结合自己的学习笔记以及网上的资料总结而成。如有错误,还请看到的读者指出,谢谢~