Blending
在训练样本中学习得到若干个gt
G= 1/T ∑ t gt
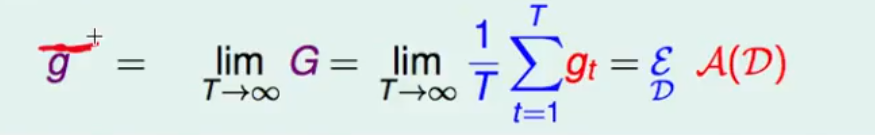
则:

此时是对于一个样本x 如果是对于所有的样本那么就变成了
avg(Eout(gt))= avg(ε(gt-G)2)+Eout(G)
此时可以看做
Eout(G) 代表多个g和真正分布之间的差距 叫做bias
而 gt 和G之间的差距称作 variance
对于回归问题而言 blending for regression 需要优化的目标函数为
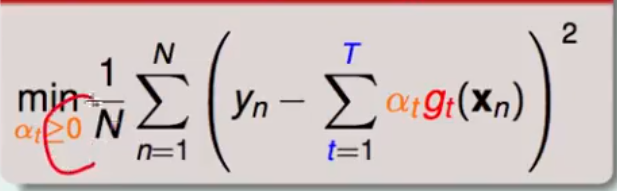
仔细观察 其实可以将其理解为特征空间转化之后的线性回归问题 即
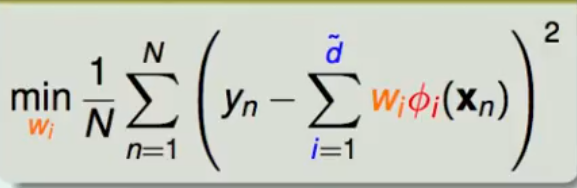
这里的i代表的是特征转换之后的特征维度的大小
这里做的特征转化 Φ(xn)=(g1(xn),g2(xn),g3(xn)…gn(xn))
那么在实际的使用过程中 首先使用训练样本Dtrain训练得到若干个 g1-,g2-,…gn-,然后将验证集中的数据Dval 通过上述所得的g-进行转化 由(xn,yn) 转化为 (zn,yn) 其中zn=(g1-(xn),g2-(xn),g3-(xn)…)

注意回传的时候传回的是正常的g而非 g-
同时不一定非要使用线性的Blending,如果使用非线性的模型做blending 则称为stacking

而对于blending 无论是给每一个hypothesis 一个固定的权重(voting,average)的uniform blending 还是使用线性模型组合的linear blending 或者使用非线性模型进行的stacking ,其前提条件都是我们已经有了一系列的hypothesis 我们使用g表示,那么能不能通过一遍学习得到g一边将g就行组合呢?
下面是可能得到不同的g

那我们接下来想要得到的是对于我们手上固定的训练样本 如何通过这些训练样本得到若干个不同的g
这时需要引入bootstrap的概念
bootstrap 要做的是在训练样本D中每次有放回的区N笔资料 这里选取N笔资料所有可能性为NN种
使用bootstrap得到的不同样本 训练不同的hypothesis 可得不同hypothesis

Bagging
使用bagging的时候需要通过bootstrap的方式对数据集进行有放回的抽样 从而得到不同的训练样本 进而得到不同的hypothesis
例如:
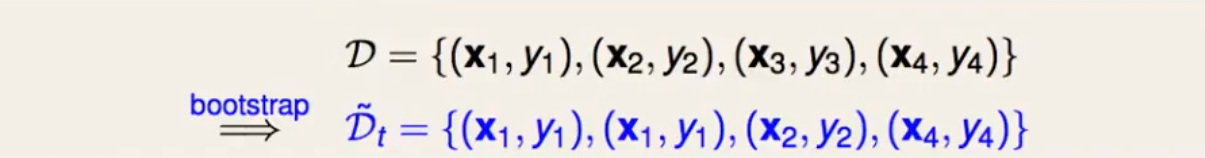
我们在boostrap之后得是数据集Dt
通过该数据集 可以计算此时的Ein=1/N ∑ t [[ f(xt)!=yt]]
因为在bootstrap之后的数据中(x1,y1)出现了两次 所以我们不妨将上述式子改写成带权重的形式

对于第t轮 若犯错误的比例为ε (因为对于随机选择二分类错误率为1/2 所以这里我们假定 犯错比例低于1/2) 那么正确的比例为(1-ε), 将犯错的样本对应的权重乘上(1-ε) 正确样本对应权重乘上ε
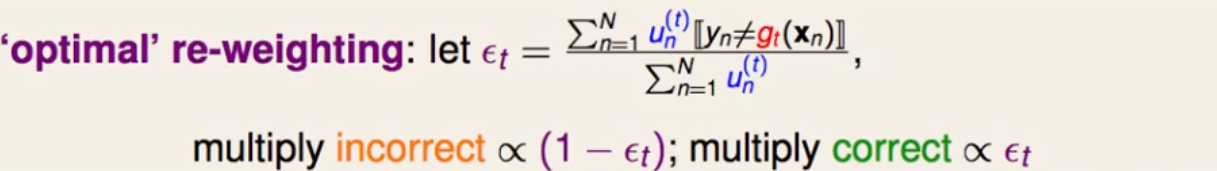
进一步我们定义一个放缩的变量
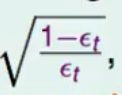
对于错误的样本权重乘上这个放缩变量,对于正确的样本权重除以这个放缩变量
Adaptive Boosting Algorithm

- 初始化 ui=1/N 其中N为样本的数量 得到第一个g1
- 通过当前的D以及ut 训练得到当前的gt
- 更新ut
最终通过不同的权重将不同的g进行连接 可想而知 对于效果好的g当然要给定一个较大的权重 但是如何区分该g的好坏呢
一个很简单的方法就是通过对应g的错误 即εt ,如果εt很小 ,方块t就会很大,说明g效果好 所以可以给α赋值一个 ε的单调函数 这里使用的是ln 函数
 、
、
整体的Adaboost流程如下

由此可见对于Adaboost算法框架 只需要给它提供一个弱演算法(比随机猜强一点的演算法 为了保证最开始的错误率小于1/2)就可以通过Adaboost得到一个较为不错的结果。