数据探索与常识科普
THUCNews中文新闻数据集;IMDB英文影评数据集
THUCNews是THU对新浪新闻RSS订阅频道2005~2011年历史数据处理后的新闻文档,地址:http://thuctc.thunlp.org/#中文文本分类数据集THUCNews
IMDB英文影评数据集是包含电影评论及感情关联的数据,地址:
http://ai.stanford.edu/~amaas/data/sentiment/
介绍之类的东西再写就是老生常谈了,个中深意还请戳进去自行了解。解压出来还挺多的。
THUCNews中包括train, test, val, vocab四个部分。train是用来训练的数据,同时包括文本与类别标签;test是用来测试的数据,只包括文本;val对应了测试的数据的结果,可以用来检验测试的准确性。
值得一提的是vocab部分,这个文件存储了字符与数字的变换关系,同时将出现频率过低的字符变为<PAD>。这个环节似乎叫做数据的预处理,总觉得能起到大作用。
有了THUNews的基础,现在来看IMDB数据集。其实结构都差不多,都是由训练数据+测试数据+测试数据真实值+字典组成。neg为消极情感,pos为积极情感。
抛出一个疑惑。有人认为语句中的停用词(例如a, the, is)没有意义,在转换的时候应该剔除。但我认为这些停用词与临近单词之间存在关联,也就是说停用词可能可以作为临近单词词性的label。这样一来,删去停用词对于一些并非特别常用的单词的语义识别是不划算的。
基本指标
Confusion Matrix, Binary classification
confusion matrix叫混淆矩阵,看起来非常高端,解释起来就呵呵。

__Binary Classification__的中文翻译是二分类。虽然也有附庸风雅的嫌疑,但这个翻译好歹还能让人顾名思义。二分类就是数据的 label 只有0和1的差别。
在Binary Classification中的confusion matrix有一些独特的指标,如图:

纵列指真实值,横行指预测值。里面的TP, FP, FN, TN就不需要解释了,看图即可。某些同志把这些名词翻译得非常反人类,非常考验人脑的语义识别能力。按理说我不应该在一篇面向广大人民群众的博客中吐槽,但还是让我吐槽一下吧。
{TP:正确的肯定数目
FN:漏报,没有找到正确匹配的数目
FP:误报,没有的匹配不正确
TN:正确拒绝的非匹配数目
}
Precision, Recall, ROC, AUC
-
精确率 Precision,召回率 Recall
Precision = TP / (TP+FP)
Recall = TP / (TP+FN)
在precision之前还有个score,总成功样例除以所有样例。但是score对极度倾斜(skewed)的数据并不能很好地反映数据特性,这与公式本身过于单调有关。为了修正这些,诸如精确率、召回率、F1 score之类的指标被提出。其实观察一下这些升级版的指标就会发现,升级版的指标缩小了单个指标关联的数据的领域,通过这种方式提高了精准性。
有关于召回率为什么叫召回率,我也是写博客的时候刚刚意识到自己不懂。但是我现在急着交博客,所以就不写了。请大家和我一起百度/google(笑)。 -
ROC , AUC
话说我一直没有见过这两个名词的翻译,估计也找不到什么特别好的翻译方法。
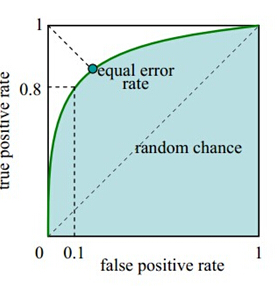
//对于0,1两类分类问题,一些分类器得到的结果往往不是0,1这样的标签,如神经网络得到诸如0.5,0.8这样的分类结果。这时,我们人为取一个阈值,比如0.4,那么小于0.4的归为0类,大于等于0.4的归为1类,可以得到一个分类结果。同样,这个阈值我们可以取0.1或0.2等等。取不同的阈值,最后得到的分类情况也就不同。//
(引用https://www.cnblogs.com/gatherstars/p/6084696.html,感谢生动形象的解释)
AUC其实就是area under the ROC curve,也就是ROC曲线下面的面积。这个是直接解释,正常人类都不可能通过这种解释明白AUC到底有什么用。下面的文章总结了一些关于AUC含义的解释,并在结尾附上了许多不同的见解,鄙人认为十分有价值,因此建议在这里深入掌握。
https://segmentfault.com/a/1190000010410634?utm_source=tag-newest