TF-IDF原理
TF-IDF是Term Frequency - Inverse Document Frequency的缩写,即“词频-逆文本频率”。词频比较容易理解,这里说一下IDF(逆文本频率)的含义。一般认为,一个词语在不同类型的文档中出现频率越高,它所包含的文档特征的要素越少,例如“中国”这一词语的IDF值就会比较低。TF显示词语在文本中的重要性,IDE显示词语在所有文本中的特殊性,二者结合即为TF-IDF。
以TF-IDF特征值为权重文本矩阵化(使用词袋模型)
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
import jieba
with open(r'..\cnews\cnews.train_part1.txt', 'r', encoding = 'utf-8') as content:
seg_list = jieba.cut(content)
vectorizer=CountVectorizer()
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(vectorizer.fit_transform(seg_list))
print(tfidf)
再说点看起来没用但实际上非常令人困扰的事情。本文中提到的最后一个任务是“利用互信息进行特征筛选”,然而特征值、互信息、特征筛选,三者之间到底有什么关系。换言之,我们得知道第一个部分到底输入了什么、输出了什么。
TF-IDF衡量的是词语对文章的“特征性”,这里的特征性包括两个层面的含义,一是重要性,即词语组成文章的效用;二是特殊性,即词语对于文章的不可替代作用。
互信息,点互信息
先认识点互信息PMI(Pointwise Mutual Information),再认识互信息MT。
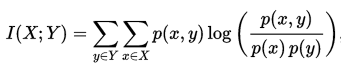
这个是互信息的公式,把前面的累加去掉就是点互信息。
当xy事件独立时,p(x,y)=p(x)p(y),也就是说PMI等于0;当xy事件彼此关联时,其概率比值会上升,继而引发PMI上升。因此可以得出结论,PMI越高,xy的关联性越强。
将xy放在语义环境中理解,可以认为是两个语义空间彼此的关联性。如果说TF-IDF得出的是“文本的特征”,那么MI得到的就是信息与信息的关联性。
使用第二步生成的特征矩阵,利用互信息进行特征筛选
这里本人还不熟悉代码实现,暂时先介绍特征筛选的方式。
过滤法 Fitter
过滤法的实现方式是将低于某一特定阈值的特征直接筛掉,留下在阈值以上的特征。
包裹法 Wrapper
包裹法采用的是特征搜索的办法。它的基本思路是,从初始特征集合中不断的选择子集合,根据学习器的性能来对子集进行评价,直到选择出最佳的子集。在搜索过程中,我们会对每个子集做建模和训练。这里的学习器一般都是机器学习的学习器,因此包裹法更多地偏重于计算机领域,而不是纯粹依靠数学手段进行过滤。
嵌入法 Embedding
与过滤法和包裹法将过滤器与学习器分别固定的方法不同,嵌入法结合了二者的流程,使模型在学习的过程中主动调整各个特征的参数权重,将不太重要的特征权重降低,以实现类似于筛选的目的。嵌入法的核心在于其优化方式。
参考
- 文本挖掘预处理之TF-IDF:文本挖掘预处理之TF-IDF https://www.cnblogs.com/pinard/p/6693230.html
- 使用不同的方法计算TF-IDF值:使用不同的方法计算TF-IDF值 https://www.jianshu.com/p/f3b92124cd2b
- sklearn-点互信息和互信息:sklearn:点互信息和互信息 https://blog.csdn.net/u013710265/article/details/72848755