@多台服务器共享 session 方案
用户量很大,单台 Redis 根本就放不下怎么办?
服务器端分布式存储了(Redis 集群、 Memcached 集群),既然是分布式,那么就必须保证用户每次请求都得到达指定的服务器,
因为他的 Session 在那台指定分片上,标记的方式可以是在存在用户的 Cookie 里面,用户请求时,服务器根据 Cookie 里面的内容将请求 Route 到指定的分片上。如果某个分片挂了怎么办,那这所有用户的 Session 就丢了。
这是就高可用了,对每个分片建多个复制集(从节点),主分片挂了,从节点就继续提供访问
@保证session一致性的架构设计常见方法
1、session同步法:多台web-server相互同步数据
2、客户端存储法:一个用户只存储自己的数据
3、反向代理hash一致性:四层hash和七层hash都可以做,保证一个用户的请求落在一台web-server上
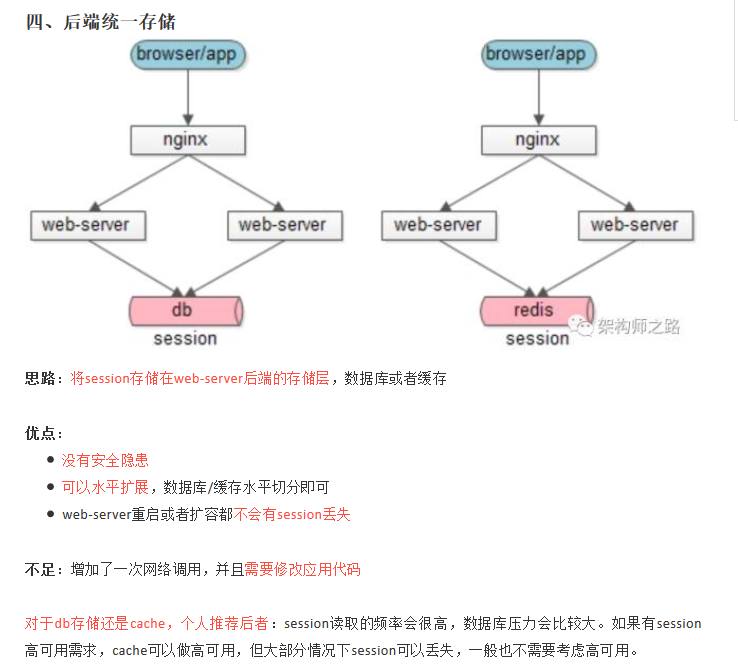
4、后端统一存储:web-server重启和扩容,session也不会丢失
@CSRF(Cross-site request forgery),跨站伪造请求
CSRF攻击是源于WEB的隐式身份验证机制!WEB的身份验证机制虽然可以保证一个请求是来自于某个用户的浏览器,但却无法保证该请求是用户批准发送的!
1、验证码
2、one token 表单随机token session

@XSS(Cross Site Script):指的是恶意攻击者往 Web页面 里插入恶意html代码,脚本注入
$data = trim ( $data ); #字符两边的处理
$data = strip_tags ( $data ); #从字符串中去除 HTML 和 PHP 标记
$data = htmlspecialchars ( $data ); #特殊字符转换为 HTML 实体
@session跨域
1.URL传参:测试模块访问的时候,地址www.xyz.com后把主域名的session通过参数的形式传递过去,如:www.xyz.com?sessionid=7D4DED1F2DB5BC53961EFED18BCE7E30
2.利用jsonp的跨域特性,通过ajax进行session传递
3.单点登录(后端 基于token的分布式缓存系统 用来替代session机制)
@memcache、redis、mongodb比较
mongodb
一款介于内存数据库和关系数据库的数据库,是高性能、无模式的文档型数据库,支持复杂的数据结构,能存储海量的数据,能提供类似关系数据库般强大的查询。
redis
是一个开源的key-value存储系统,所有数据都是放在内存中的,持久化是使用RDB方式或者aof方式。仅支持key、string、hash、list、set几种结构,优点:读写速度非常快(单线程)。缺点:受内存限制无法存储过多的数据,也无法提供强大的查询,只使用单核。
memcache
是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。memcache仅支持简单的key-value结构,但使用多核。
Memcached单个key-value大小有限,一个value最大只支持1MB,而Redis最大支持512MB。Redis可以视为Memcached的扩展
@提高系统并发能力(高并发)?
互联网分布式架构设计,提高系统并发能力的方式,方法论上主要有两种:垂直扩展与水平扩展
垂直扩展:提升单机处理能力。
(1)增强单机硬件性能,例如:增加CPU核数如32核,升级更好的网卡如万兆,升级更好的硬盘如SSD,扩充硬盘容量如2T,扩充系统内存如128G;
(2)提升单机架构性能,例如:使用Cache来减少IO次数,使用异步来增加单服务吞吐量,使用无锁数据结构来减少响应时间;
水平扩展:增加服务器数量,线性扩充系统性能,互联网分层架构中,各层次水平扩展的实践又有所不同:
(1)反向代理层可以通过“DNS轮询”的方式来进行水平扩展;
(2)站点层可以通过nginx来进行水平扩展;
(3)服务层可以通过服务连接池来进行水平扩展;
(4)数据库可以按照数据范围,或者数据哈希的方式来进行水平扩展; 各层实施水平扩展后,能够通过增加服务器数量的方式来提升系统的性能,做到理论上的性能无限。
@提高系统高可用(高可用)?
高可用是通过冗余+自动故障转移来实现的。高可用保证的原则是“集群化”,或者叫“冗余”。只有一个单点,挂了服务会受影响;如果有冗余备份,挂了还有其他backup能够顶上。
【客户端层】到【反向代理层】的高可用,是通过反向代理层的冗余实现的,常见实践是keepalived + virtual IP自动故障转移
【反向代理层】到【站点层】的高可用,是通过站点层的冗余实现的,常见实践是nginx与web-server之间的存活性探测与自动故障转移
【站点层】到【服务层】的高可用,是通过服务层的冗余实现的,常见实践是通过service-connection-pool来保证自动故障转移
【服务层】到【缓存层】的高可用,是通过缓存数据的冗余实现的,常见实践是缓存客户端双读双写,或者利用缓存集群的主从数据同步与sentinel保活与自动故障转移;更多的业务场景,对缓存没有高可用要求,可以使用缓存服务化来对调用方屏蔽底层复杂性
【服务层】到【数据库“读”】的高可用,是通过读库的冗余实现的,常见实践是通过db-connection-pool来保证自动故障转移
【服务层】到【数据库“写”】的高可用,是通过写库的冗余实现的,常见实践是keepalived + virtual IP自动故障转移
@系统 秒杀 的一个思路逻辑
第一层,客户端怎么优化(浏览器层,APP层)
(a)产品层面,用户点击“查询”或者“购票”后,按钮置灰,禁止用户重复提交请求;
(b)JS层面,限制用户在x秒之内只能提交一次请求; 这种办法只能拦住普通用户(但99%的用户是普通用户)对于群内的高端程序员是拦不住的。firebug一抓包,http长啥样都知道,js是万万拦不住程序员写for循环,调用http接口的,这部分请求怎么处理?
第二层,站点层面的请求拦截(限制用户请求频率)
怎么防止程序员写for循环调用,有去重依据么?ip?cookie-id?…想复杂了,这类业务都需要登录,用uid即可。 对一个uid,5秒只准透过1个请求,这样又能拦住99%的for循环请求。其余的请求页面缓存。
这个方式拦住了写for循环发http请求的程序员,有些高端程序员(黑客)控制了10w个肉鸡,手里有10w个uid,同时发请求(先不考虑实名制的问题,小米抢手机不需要实名制),这下怎么办,站点层按照uid限流拦不住了。
第三层 服务层来拦截(请求队列)
对于写请求,做请求队列,每次只透有限的写请求去数据层(下订单,支付这样的写业务) 1w部手机,只透1w个下单请求去db,3k张火车票,只透3k个下单请求去db 如果均成功再放下一批,如果库存不够则队列里的写请求全部返回“已售完”。 最后数据库层,浏览器拦截了80%,站点层拦截了99.9%并做了页面缓存,服务层又做了写请求队列与数据缓存,每次透到数据库层的请求都是可控的。
@快速恢复删库的数据
【1小时延时从】 如图所示,增加一个从库,这个从库不是实时与主库保持同步的,而是每隔1个小时同步一次主库,同步完之后立马断开1小时,这个从库会与主库保持1个小时的数据差距。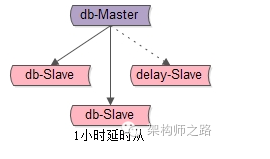
当“删全库”事故发生时,只需要:
(1)应用1小时延时从
(2)将1小时延时从最近一次同步时间到,将执行“删全库”之前的binlog找到,重放快速恢复完毕。
方案优点:能够快速找回数据
潜在不足:万一,万一,万一,1小时延时从正在连上主库进行同步的一小段时间内,发生了“删全库”事故,那怎么办咧? 【双份1小时延时从】 如图所示,两个1小时延时从,他们连主库同步数据的时间“岔开半小时”。
这样,即使一个延时从连上主库进行同步的一小段时间内,发生了“删全库”事故,依然有另一个延时从保有半小时之前的数据,可以实施快速恢复。
方案优点:没有万一,都能快速恢复数据
潜在不足:资源利用率有点低,为了保证数据的安全性,多了2台延时从,降低了从库利用率 【提高从库效率】 1小时延时从也不是完全没有用,对于一些“允许延时”的业务,可以使用1小时延时从,
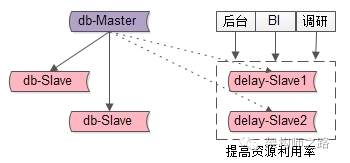
例如:
(1)运营后台,产品后台
(2)BI进行数据同步
(3)研发进行数据抽样,调研
@分布式事务锁(分布式环境下的互斥)
分布式环境下,多台机器上多个进程对一个数据进行操作的互斥,例如同一个uid=123要避免同时进行扣款

步骤:
(1)多台机器上多个进程对这个锁进行争抢,例如在缓存上同时进行set key=123操作
(2)只有一个进程会抢到这个锁,即只有一个进程对缓存set key=123能够成功,不成功的进程下次再来抢
(3)抢到锁的进程对余额进行扣减
(4)扣减完成之后释放锁,即对缓存delete key=123
@数据库主从复制数据不一致的问题
有4中方案,这里介绍第四种
1)半同步复制
2)强制读主
3)数据库中间件
4)缓存记录写key
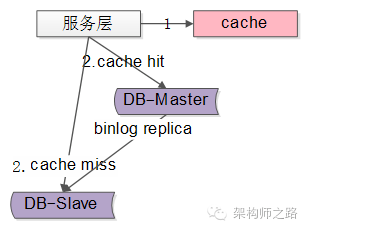
使用缓存
(1)将某个库上的某个 key 要发生写操作,记录在cache里,并设置“经验主从同步时间”的cache超时时间,例如500ms
(2)修改数据库

而读请求发生的时候
(1)先到cache里查看,对应库的对应key有没有相关数据
(2)如果cache hit,有相关数据,说明这个key上刚发生过写操作,此时需要将请求路由到主库读最新的数据
(3)如果cache miss,说明这个key上近期没有发生过写操作,此时将请求路由到从库,继续读写分离