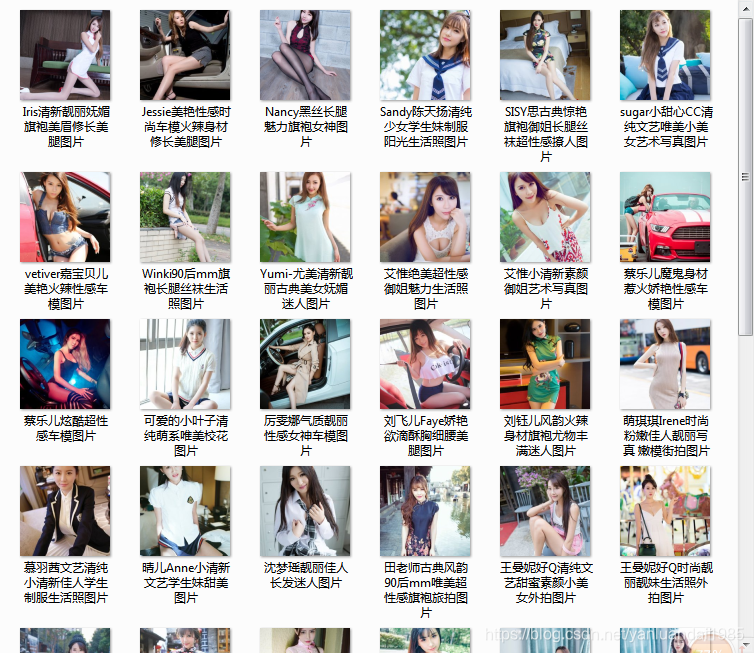
版权声明:欢迎转载大宇的博客,转载请注明出处: https://blog.csdn.net/yanluandai1985/article/details/88666960
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
from urllib.request import urlretrieve
import requests
import os
import time
if __name__ == '__main__':
list_url = []
url = 'https://www.plmm.com.cn/'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
req = requests.get(url=url, headers=headers)
req.encoding = 'utf-8'
html = req.text
bf = BeautifulSoup(html, 'html.parser')
targets_url = bf.find_all(class_='figure figure-img')
for each in targets_url:
print(each.a.img.get('alt'))
print(each.a.img['src'][2:])
list_url.append(each.a.img.get('alt') + '=' + each.a.img['src'])
print('连接采集完成')
for each_img in list_url:
img_info = each_img.split('=')
target_url = img_info[1]
filename = img_info[0]
print('下载:' + filename)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
if 'images' not in os.listdir():
os.makedirs('images')
target_url = "https:" + target_url
urlretrieve(url=target_url, filename='images/' + filename+".jpg")
time.sleep(1)
print('下载完成!')
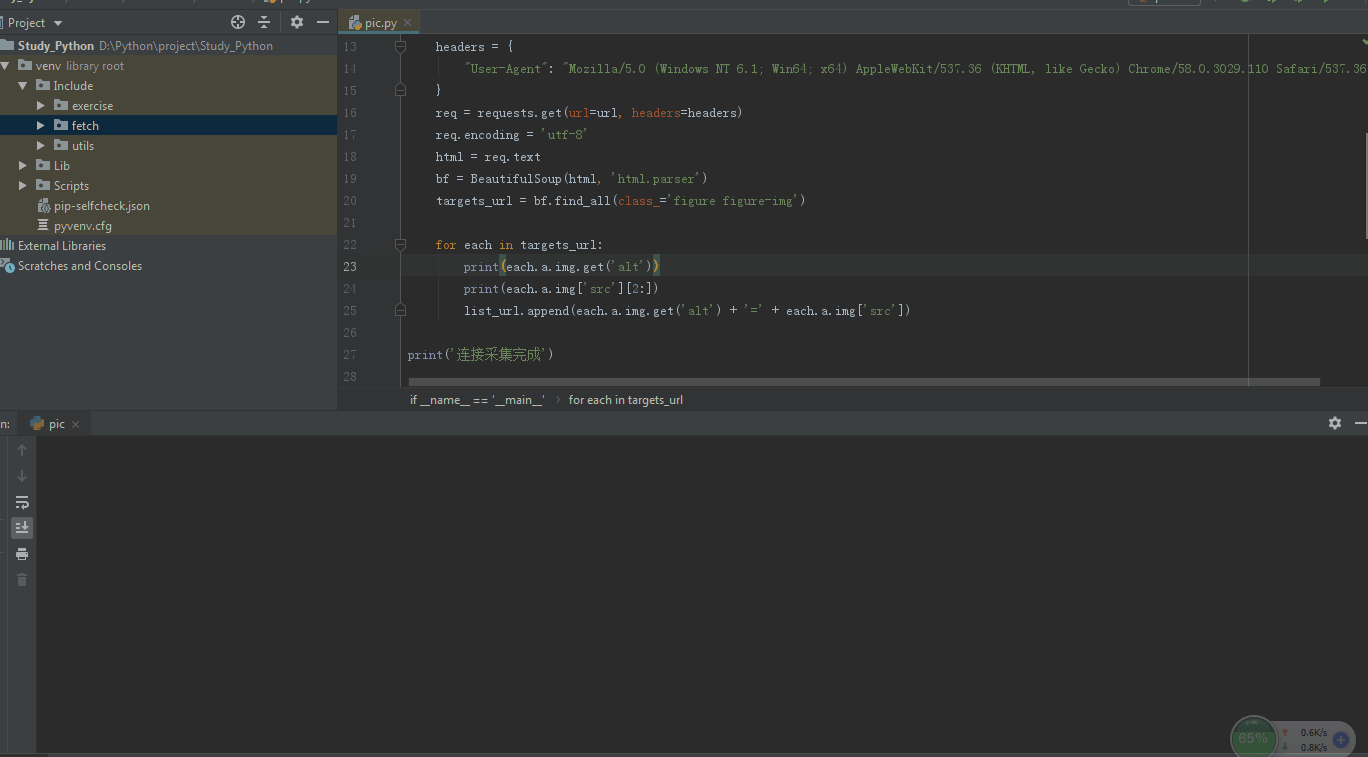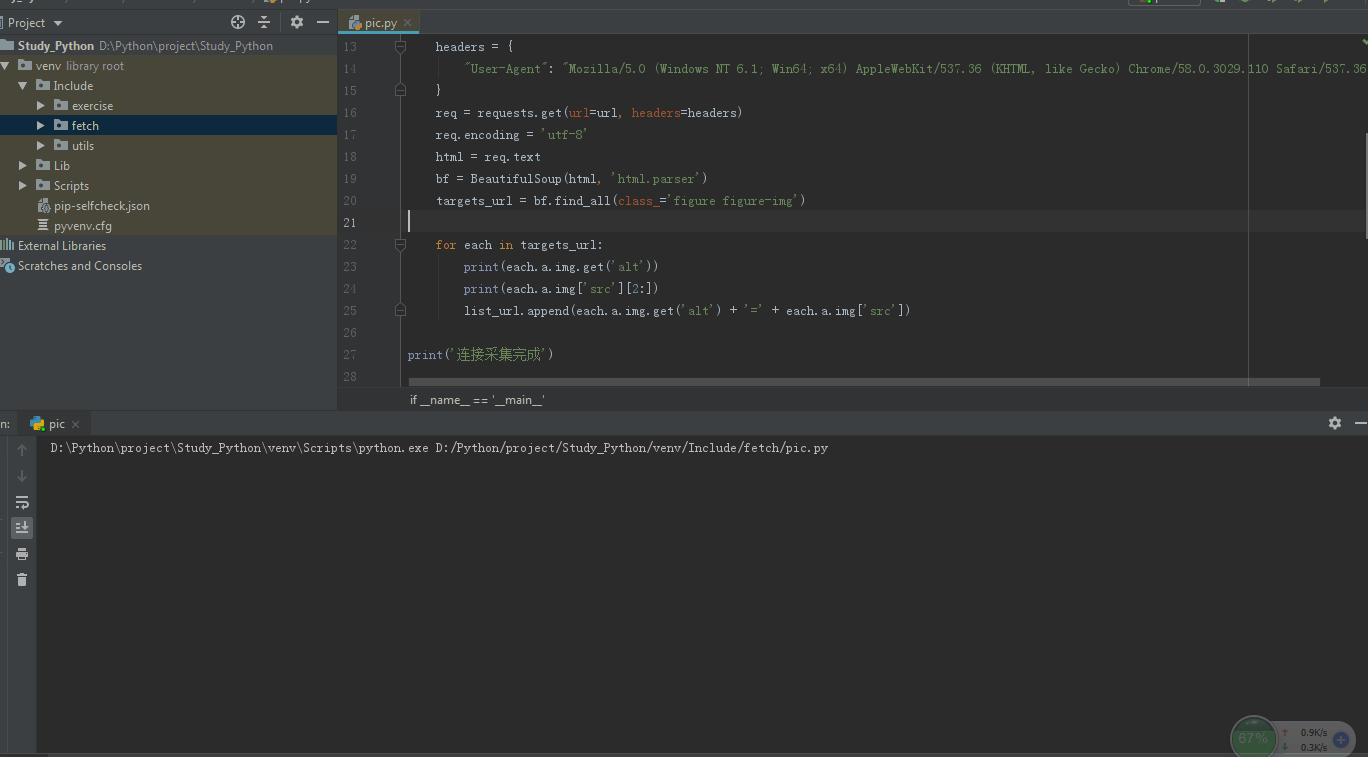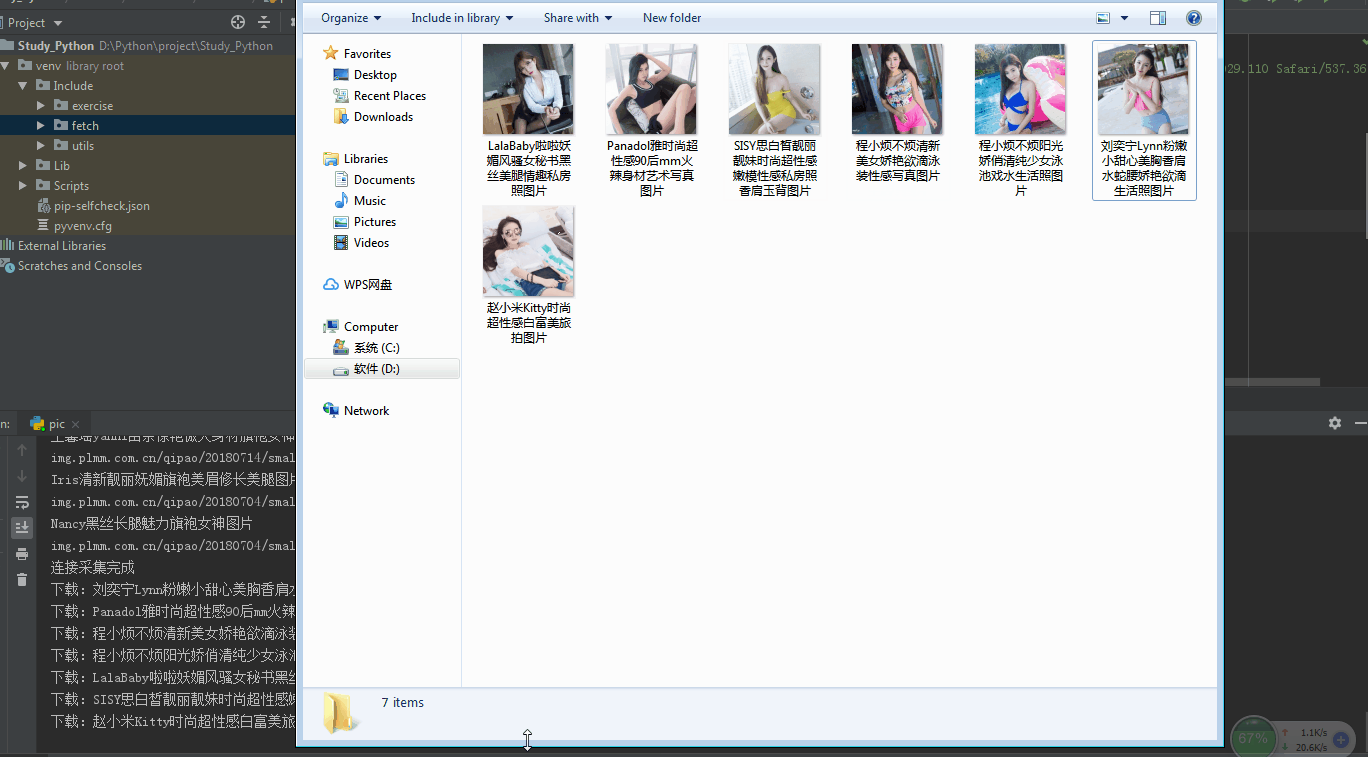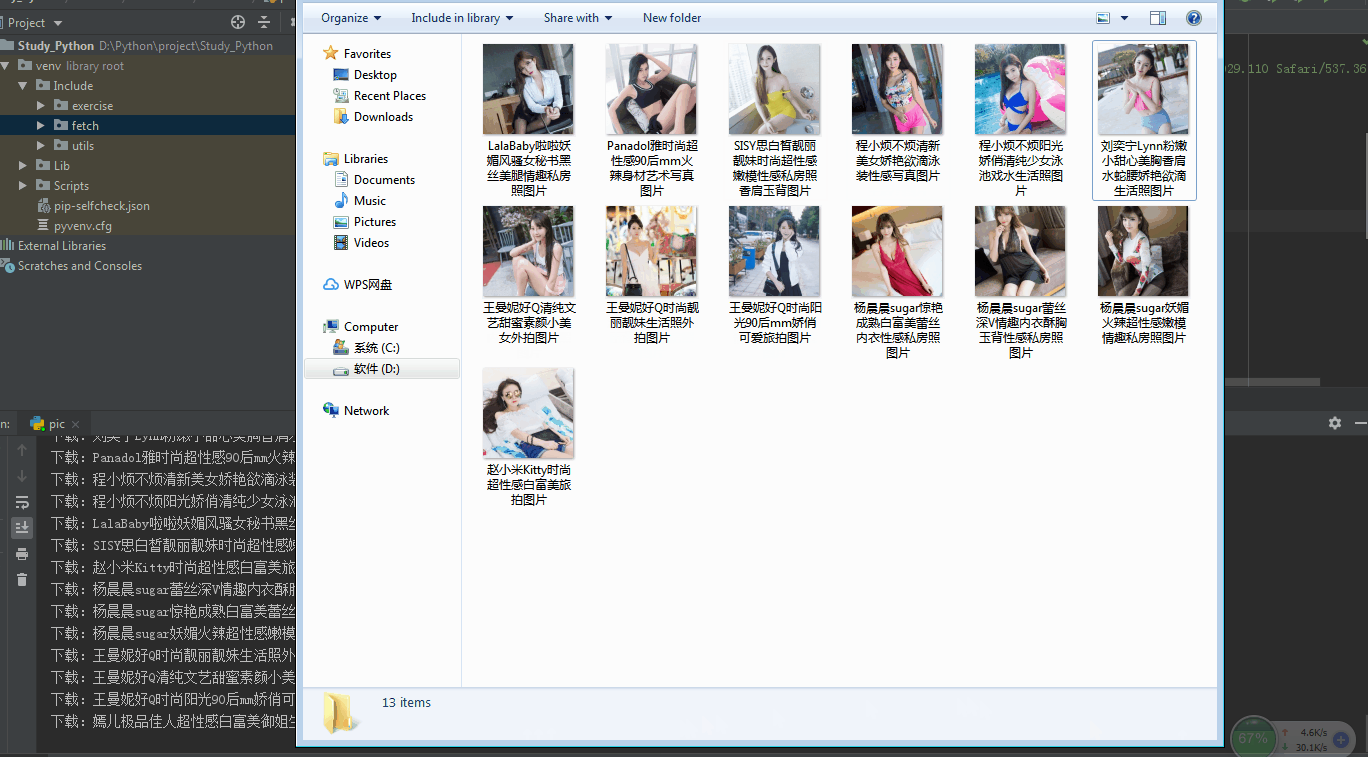
运行效: