前言
听说《武炼巅峰》小说不错,打算看看。于是到处找小说app来看,免费的看小说的app上的广告防不胜防,要么就一直出现,要么就突然出现,一不小心就点到广告中了。正版小说app看小说体验很好,没有广告,app 的功能也多种多样,奈何正版的小说app需要人民币才能看,于是想下载txt到本地后用正版小说app看,既没有广告又不用花钱,一举两得。但是我有个小说洁癖,就是没有完结的小说不想下载txt来看,而《武炼巅峰》恰好是连载中的,并未完结,所以并不想直接就下载全部txt,于是我打算自己使用爬虫技术,分卷下载《武炼巅峰》,保存成txt,看多少就下多少,这本小说有四千多章,够我看很久的了。
使用技术
爬虫库选择python大佬kenneth-reitz在去年刚推出的requests-html库。
剩下的就是python基础和函数式编程了。
正文
代码
引入库
from requests_html import HTMLSession
写python程序,第一步先把main函数写上,老师说这么写更规范。
def main():
"""爬取《武炼巅峰》小说"""
crawl()
if __name__ == '__main__':
main()
由此可见,我们的主要业务代码都在crawl函数中了。
def crawl():
"""爬取"""
session = HTMLSession()
url = 'https://www.biquge.info/1_1760/'
r = session.get(url)
content = r.html.find('#list a') # 返回目录列表,类型是Element类型
chapter_list = [] # 将要被爬取的目录
volumes = [2] # 爬取的卷,[1, 2]就是爬1、2卷,我现在只爬取第二卷,因为第一卷看完了
crawl_by_volume(chapter_list, content, url, volumes) # 按卷爬取
喜欢python就是因为python简单易用,而是用requests-html更是因为它比request、BeautifulSoup都更简单。
第7行的r.html.find(’#list a’)便是使用了css选择器的方法找到了想要爬取的区域,requests-html是真的强大!
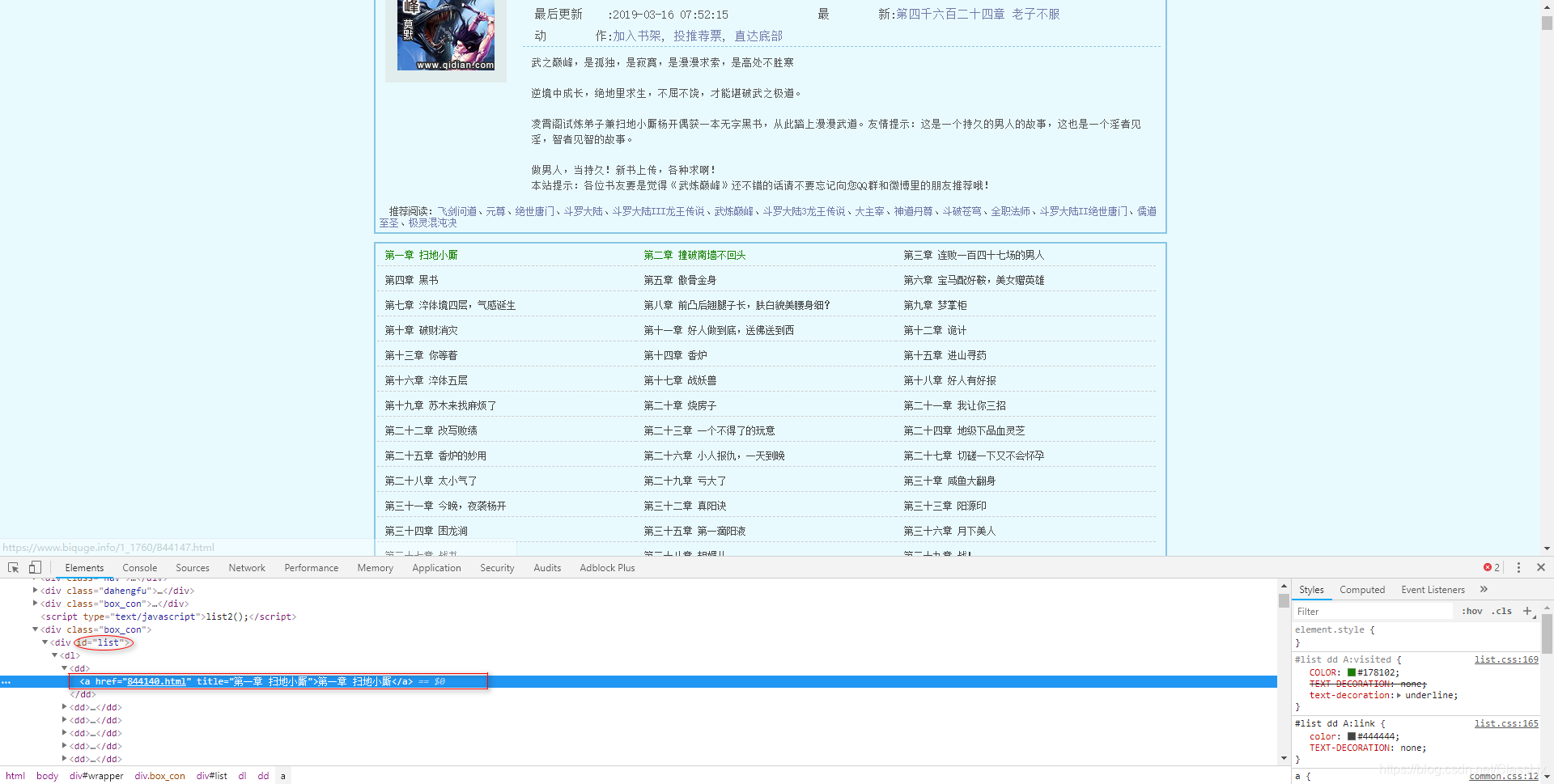
图片中红色标记就是选择器的内容。
知道了目录,确定了要爬取的卷,下一步就是爬取了!
def crawl_by_volume(chapter_list, content, url, volumes):
"""分卷爬取"""
index = [0] # content的索引
for i in range(len(volumes)):
if volumes[i] == 1:
crawl_one_volume(content, chapter_list, index)
if volumes[i] == 2:
crawl_two_volume(content, chapter_list, index)
if volumes[i] == 3:
crawl_three_volume(content, chapter_list, index)
if volumes[i] == 4:
crawl_four_volume(content, chapter_list, index)
if volumes[i] == 5:
crawl_five_volume(content, chapter_list, index)
if volumes[i] == 6:
crawl_six_volume(content, chapter_list, index)
if volumes[i] == 7:
crawl_seven_volume(content, chapter_list, index)
if volumes[i] == 8:
crawl_eight_volume(content, chapter_list, index)
# pprint.pprint(chapter_list)
# print(len(chapter_list))
# 爬取小说并写入文件
crawl_chapter_and_write(chapter_list, url)
在这一步中,根据参数volumes来判断要爬取哪一卷,本书一共有八卷(目前还只是八卷,以后可能会更多)。
index = [0],这一步是我觉得写得好的地方,接下来我来解释一番:
首先先看看爬取第一卷的方法:
def crawl_one_volume(content, chapter_list, index):
"""爬取第一卷"""
for c in content:
if '第一百一十六章' in c.text:
index[0] = content.index(c)
break
chapters_of_volume = content[:index[0] + 1] # 第一章到第一百一十六章
change_chapter_list(chapter_list, chapters_of_volume)
在爬取第一卷的方法中,形参content是目录的列表,长度有四千多(因为总共四千多章),要确定每一卷的章节范围需要遍历此列表。第一次遍历列表从头遍历,直到遇到“第一百一十六章”的字符串时停止。第二卷遍历从第一卷停止的位置开始遍历,这样可以减少遍历次数,避免重复遍历,index的作用在这了。为什么这里index用的是列表类型,不是整型呢?因为整型的index是值传递,每次遍历依然是从头开始,所以使用列表类型的index,把值传递改成引用传递,就可以达到减少遍历次数的目的了。
接下来看看change_chapter_list函数:
def change_chapter_list(chapter_list, chapters_of_volume):
"""改变需要爬取的章节列表"""
for a in chapters_of_volume:
var = ['0', '1']
var[0] = a.attrs['href'] # 链接
var[1] = a.text # 标题
chapter_list.append(var)
在这个函数中,被传递了三次的chapter_list参数终于用上了!
a.attrs[‘href’]、和a.text是requests-html中的用法,一个是获取超链接的href属性值,一个是获取超链接中的文本。
我定义了变量名为var的列表,用来存超链接和章节标题,为什么取名为var呢?因为Java的spring源码中有的异常变量名就取的是var,有的异常变量名叫var8,有的变量名var14,我是看得一脸懵逼,连人家都能取名如此随意,我也就借来用用了,毕竟取名字真的好难!
现在大部分函数都解释了,只剩下一个crawl_chapter_and_write函数了。
def crawl_chapter_and_write(chapter_list, url):
"""爬取文字"""
session = HTMLSession()
for chapter in chapter_list:
title = chapter[1] # 获取章节标题
link = url + chapter[0] # 拼接章节链接
r = session.get(link)
content = r.html.find('#content', first=True) # 根据选择器得到章节内容
print(title + '---------------开始写入。。。')
distilled_content = distill_content(content) # 章节内容精校
# pprint.pprint(distilled_content)
export_txt(title, distilled_content) # 写入txt
print(title + '---------------写入完成')
这个函数才是真正爬取内容的函数,前面的函数都只是准备工作。感觉马上就可以收工了。
再附上最后两个函数的内容:
def distill_content(content):
"""去除糟粕,精校文字"""
content_text = content.text
content_text = content_text.replace(chr(0xa0), '') # 去除网页中的\xa0空白符
content_text = content_text.replace('龗', '') # 去除无用字符
return content_text
def export_txt(title, content):
"""输出到txt文件"""
with open('武炼巅峰.txt', 'a') as file:
file.write('\n') # 标题前空一行
file.write(title)
file.write('\n') # 标题后空一行,只有这样才能让小说app识别章节标题,生成目录
file.write(content)
参考文章
https://blog.csdn.net/wangbowj123/article/details/78061618
本文源码
https://github.com/XueJingLiiu/wuliandianfeng
结语
第一次感觉写了好多好多函数,函数嵌套得有点多了,也不知道这样好不好。
虽然这个程序的功能简单,但还是用了我不少心思的。
通过这个程序,我又学到了python3中的一些基本语法,比如遍历列表、列表切片、字符串查找与替换、chr()函数还有文件读写,当然,还有我最喜欢的requests-html库。
生命苦短,我用python,虽然出身Java,但我依然喜欢python。