1. 测试准备
3张表:复合主键表(3个主键),int主键表,string主键表
4个数据库:Oracle11gr2 ,mysql 5.7 ,sqlserver2008 ,sap hana express2.0
网络环境大致相同,机器配置sap hana由于本身要求较高配置高一些。
2. 插入测试
数据库安装后默认配置测试
测试结果:
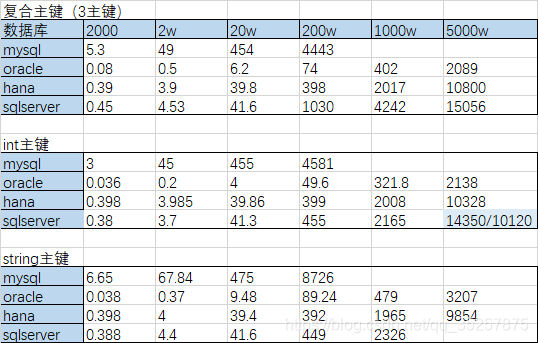
结论:
oracle>hana>sqlserver>mysql
hana数据量时长呈线性增长,插入效率最为稳定(速度基本保持不变5000条/s)
hana 较SQL server快一点,但不是很明显
复合主键表
oracle较hana效率高5倍以上 较sqlserver高5-10倍 较mysql高50倍以上
数据量大时 oracle较hana效率高5倍左右 较sqlserver高5-10倍左右
int主键表
数据量小时 oracle较hana效率高10倍左右 较sqlserver高10倍左右 较mysql高100倍
string主键表
oracle较hana效率高5倍左右 较mysql50倍
数据库基本优化后测试
hana 和 Oracle 隐式事务 不需要commit 没有设置自动提交
mysql和sqlserver 显性事务 默认自动提交(只要有sql语句就提交),提交次数增多执行时间延长,优化为一次提交。
知识点:
sql server和mysql在默认的情况下,是每个语句都自动提交的,这样100w条数据,就提交了100w次,虽然每次提交消耗的时间很少,但是乘上100w次,那就是非常大的时间了,速度自然就慢了。
而oracle和hana 是隐式事务(不用像sql server那样写 begin tran来显式的开启事务),也就是一堆的sql都在一个事务里,直到手动commit或者rollback来提交,所以,插入100w数据只提交1次。
优化:
1.关闭mysql自动提交
http://blog.itpub.net/30162081/viewspace-2127395
2.优化sqlserver插入存储过程
使循环SQL插入语句只需提交一次
alter procedure test_while_loop_index
--参数自定义默认值
@start_count int,@end_count int
as
SET NOCOUNT ON
BEGIN TRY
BEGIN TRAN
while @start_count < @end_count
BEGIN
INSERT INTO PERSON_INDEX VALUES (@start_count, 'abc','abc','abc','abc','abc',1.1,2.2,5.55,9.9999,12,34,56,78,91,123,'sss','sss','sss','sss','sss' ,'sss','sss','sss','sss','sss','sss','sss','sss','sss','sss','sss','sss','sss','sss','sss','sss','sss','sss','sss','sss','sss','sss','sss','sss','sss','sss','sss','sss',@start_count,@start_count);
set @start_count=@start_count +1
end ;
commit TRAN
END TRY
BEGIN CATCH
print'bb'
print '出现异常,错误编号:' + convert(varchar, error_number()) + ', 错误消息:' + error_message();
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRAN
END
END CATCH
go
测试结果:

结论:
sqlserver>oracle>mysql>hana
3. 查询测试
测试结果:
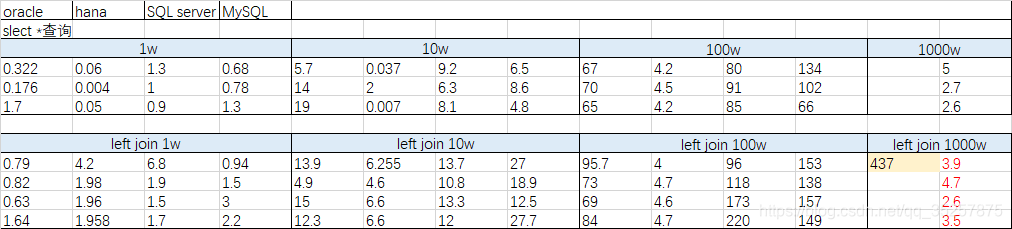
结论:
hana查询速率最快,且稳定,小数据量大数据量基本5s以内,其他随数据量增大查询时间明显增大
数据量大时一般 hana> oracle >sqlserver >mysql 数据量小时浮动较大不是很明显
1000w测试除hana外只测了一条Oracle,用的navicat软件内存容易占满强退