一、TextCnn的结构
1. 嵌入层(embedding layer)
textcnn使用预先训练好的词向量作embedding layer。对于数据集里的所有词,因为每个词都可以表征成一个向量,因此我们可以得到一个嵌入矩阵\(M\),\(M\)中的每一行都是一个词向量
这个\(M\)可以是静态(static)的,也就是固定不变。可以是非静态(non-static)的,也就是可以根据反向传播更新
2.卷积池化层(convolution and pooling)
输入一个句子,首先对这个句子进行切词,假设有\(s\)个单词,对于每个单词,我们根据上面提到的嵌入矩阵\(M\) 可以得到词向量。假设词向量一共有\(d\)维度,那么我们可以用一个\(s\)行\(d\)列矩阵\(A\)来表示这个句子:\(A \in R^{s\times d }\)
我们可以把矩阵\(A\)看成是一幅图像(单通道:灰度图),使用卷积神经网络去提取特征。但是注意卷积核不是常用的 3 * 3或者5 * 5,而是:卷积核的宽度就是词向量的维度\(d\),高度是超参数,可以设置
3.池化(pooling)
不同尺寸的卷积核得到的特征(feature map)大小也是不一样的,因此我们对每个feature map使用池化函数,使它们的维度相同。最常用的就是1-max pooling,提取出feature map照片那个的最大值
这样每一个卷积核得到特征就是一个值,对所有卷积核使用1-max pooling,再级联起来,可以得到最终的特征向量,这个特征向量再输入softmax layer做分类。这个地方可以使用drop out防止过拟合
4.整个过程过程如下(卷积核宽度就是词向量维度,核高度可以设置):
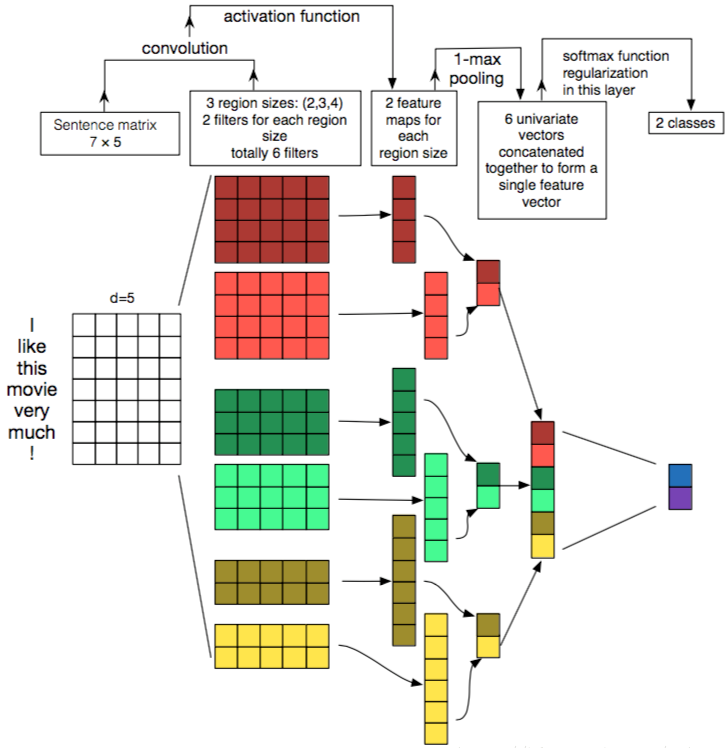
- 这里word embedding的维度是5。对于句子 i like this movie very much!可以转换成如上图所示的矩阵:\(A \in R^{7\times 5 }\)
- 有6个卷积核,尺寸为\( (2 \times 5),(3 \times 5),(4 \times 5) \),每个尺寸各2个
- 句子矩阵\(A\)分别与以上卷积核进行卷积操作,再用激活函数激活。每个卷积核都得到了特征向量(feature maps)
- 使用1-max pooling提取出每个feature map的最大值,然后在级联得到最终的特征表达
- 将特征输入至softmax layer进行分类, 在这层可以进行正则化操作( l2-regulariation)
二、参考
本文参考:https://blog.csdn.net/John_xyz/article/details/79210088
感谢分享:知识共享推动世界进步!