首先是包含全连接的一幅图片:
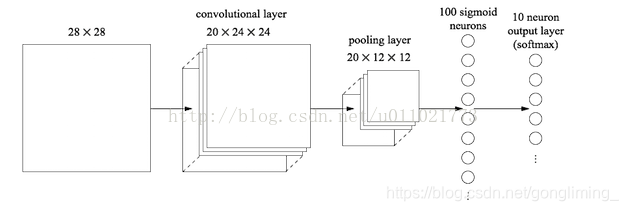
全连接把卷积输出的二维特征图(feature map)转化成一个一维向量,也就是说:最后的两列小圆球就是两个全连接层,在最后一层卷积结束后,又进行了一次池化操作,输出了20个12x12的图像(20指最后一层的厚度),然后通过了一个全连接层变成了1x100的向量(第一个全连接层神经元的个数是100)
怎么做到的?
该操作其实就是用100个20x12x12的卷积核卷积出来的,对于输入的每一张特征图,都使用一个和图像大小一样的核卷积进行卷积运算,这样整幅图就变成了一个数了,如果厚度是20就是那20个核卷积完了之后相加求和。这样就能把一张图高度浓缩成一个数了。
但是全连接的参数实在是太多了,你想这张图里就有20个12x12x100个参数,前面随便一层卷积,假设卷积核是7*7的,厚度是64,那也才7x7x64,所以现在的趋势是尽量避免全连接,目前主流的一个方法是全局平均池化(GlobalAveragePooling)。也就是最后那一层的feature map(最后一层卷积的输出结果),直接求平均值。有多少种分类就训练多少层,这十个数字就是对应的概率。
全连接的理解
猜你喜欢
转载自blog.csdn.net/gongliming_/article/details/89634243
今日推荐
周排行