Scrapy目录结构介绍与配置文件详解
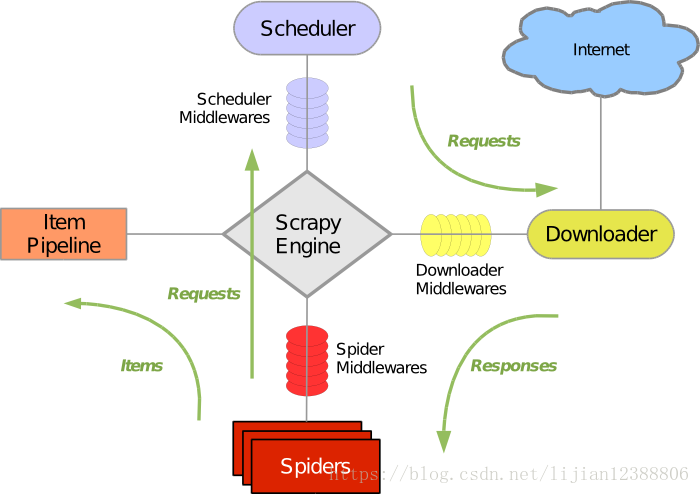
先上架构图,网上找的,不管懂不懂,先有个印象,结合文件目录和解释去看,结合以后的实践,原理一目了然。
- 创建出scrapy项目目录如下
├── mySpider │ ├── __init__.py │ ├── items.py │ ├── middlewares.py │ ├── pipelines.py │ ├── __pycache__ │ ├── settings.py │ └── spiders │ ├── __init__.py │ └── __pycache__ └── scrapy.cfg
- scrapy.cfg文件
# Automatically created by: scrapy startproject
#
# For more information about the [deploy] section see:
# https://scrapyd.readthedocs.io/en/latest/deploy.html
[settings]
default = mySpider.settings
[deploy]
#url = http://localhost:6800/
project = mySpider项目基础设置文件,设置爬虫启用的功能,如并发,管道文件等,需要在基础设置文件设置
- init.py 文件为python初始化文件
为python模块初始化文件,可用__all__函数配置导出参数,也可什么都不写,但是必须要有,否则报错
- items.py 文件
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class MyspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass此文件俗称模型文件,就是存放字段的文件,上面为简单实例,定义字段名称,以自己的任意形式存取数据
- pipelines.py 管道文件
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
class MyspiderPipeline(object):
def process_item(self, item, spider):
return itemdef process_item为固定写法,当数据交给管道文件处理时,在此文件下
- settings.py核心文件,配置如下
# -*- coding: utf-8 -*-
# Scrapy settings for mySpider project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#项目名称
BOT_NAME = 'mySpider'
#项目位置
SPIDER_MODULES = ['mySpider.spiders']
#新爬虫启动位置
NEWSPIDER_MODULE = 'mySpider.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'mySpider (+http://www.yourdomain.com)'
# Obey robots.txt rules
#表示爬虫是否遵循robot协议,默认为遵循
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#爬虫并发量,默认为16个
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#下载延时为3秒,下载太快压力会大,自行设置
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#是否启动cookies,双刃剑,在爬取需要登录的网站时,需要,但是如果不需要登录则不需要,更好的隐藏身份
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#请求报头设置,这里设置就不用程序设置了,如:User-Agent设置
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
# 爬虫中间件
#SPIDER_MIDDLEWARES = {
# 'mySpider.middlewares.MyspiderSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# 下载中间件,数字代表优先级
#DOWNLOADER_MIDDLEWARES = {
# 'mySpider.middlewares.MyspiderDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
# ** 比较重要,管道文件,表示下载好的数据如何处理
#ITEM_PIPELINES = {
# 'mySpider.pipelines.MyspiderPipeline': 300,
#}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'- spiders文件—爬虫文件
cd spiders
#命令创建一个爬虫文件,最后的是资源uri
scrapy genspider myspider alinetgo.com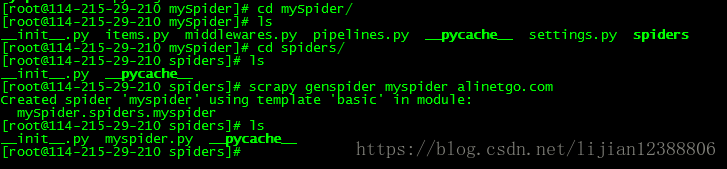
创建完毕 模板内容
# -*- coding: utf-8 -*-
import scrapy
class MyspiderSpider(scrapy.Spider):
name = 'myspider'
allowed_domains = ['alinetgo.com']
start_urls = ['http://alinetgo.com/']
def parse(self, response):
pass有些不懂的不需要着急,以后慢慢详细介绍 未完待续。。。。