目录
一、概述
本篇文章主要分析设备无关接口,通用设备抽象和Qos层
二、数据抽象和接口
2.1 net_device
设备无关层一个重要的数据抽象是net_device{},net_device是一个承上启下的结构,对上层,对应网络层特定的数据结构,对下,对应驱动程序的私有数据,而作为一个抽象数据结构,其提供的抽象接口有效的隔离了不同网络硬件的变化。net_device是一个庞大的数据结构,它的数据成员我挑选重要的按类说明:
设备的属性(没有按顺序)
struct net_device {
char name[IFNAMSIZ]; //设备名称
unsigned long state; //设备状态
int ifindex; //ID
unsigned int flags;
unsigned int priv_flags;
unsigned int mtu;
unsigned short hard_header_len; //L2
unsigned char addr_len;
unsigned long tx_queue_len
struct netdev_rx_queue *_rx;
unsigned int num_rx_queues;
unsigned int real_num_rx_queues;
struct netdev_queue *_tx ____cacheline_aligned_in_smp;
unsigned int num_tx_queues;
unsigned int real_num_tx_queues;
struct Qdisc *qdisc;
unsigned long mem_end; //驱动相关mmio
unsigned long mem_start;
unsigned long base_addr;
int irq;
};结构管理:
struct net_device {
struct hlist_node name_hlist;
struct list_head dev_list;
struct list_head napi_list;
struct list_head unreg_list;
struct list_head close_list;
struct list_head ptype_all;
struct list_head ptype_specific;
struct list_head napi_list
};接口及其上下文
struct net_device {
const struct header_ops *header_ops;
const struct rtnl_link_ops *rtnl_link_ops;
const struct net_device_ops *netdev_ops;
const struct ethtool_ops *ethtool_ops;
struct in_device __rcu *ip_ptr;
rx_handler_func_t __rcu *rx_handler;
void __rcu *rx_handler_data;
}2.2 API及说明
2.2.1 net_device分配
- alloc_netdev_mqs
- alloc_etherdev
- alloc_etherdev_mq
- free_netdev
[net/core/dev.c]
struct net_device *alloc_netdev_mqs(int sizeof_priv, const char *name,
unsigned char name_assign_type,
void (*setup)(struct net_device *),
unsigned int txqs, unsigned int rxqs)- net_device的分配
- 初始化:dev_addr_init/dev_mc_init/dev_uc_init/dev_net_set
- 发送队列和接收队列初始化
2.2.2 net_device 注册
- register_netdev
- unregister_netdev
[net/core/dev.c]
int register_netdev(struct net_device *dev)- 检测name合法性,分配ifindex
- dev_init_scheduler 初始化qdisc
- list_netdevice 将ifindex,name,dev加入hash表
- call_netdevice_notifiers(NETDEV_REGISTER, dev) /* Notify protocols, that a new device appeared. */
2.2.3 端口状态管理
- netif_carrier_on
- netif_carrier_off
- netif_carrier_ok
端口状态:
一般的,称端口状态是UP包括如下两个方面:
- 管理状态
- 链路状态
当执行ifconfig eth_X up,端口的管理状态up,此时dev->flags 需要置 IFF_UP位,链路状态一般由驱动程序和内核共同完成,链路状态一般由网卡芯片中的某个寄存器指定,驱动程序通过处理链路发生变化时产生中断,也可以通过timer,tasklet等机制去轮询端口的状态,之后通过以下接口通知内核端口的链路状态:
[net/sched/sch_generic.c]
void netif_carrier_on(struct net_device *dev)
{
if (test_and_clear_bit(__LINK_STATE_NOCARRIER, &dev->state)) {
if (dev->reg_state == NETREG_UNINITIALIZED)
return;
atomic_inc(&dev->carrier_up_count);
linkwatch_fire_event(dev);
if (netif_running(dev))
__netdev_watchdog_up(dev);
}
}看linkwatch_fire_event,该函数将自身加入lweventlist的工作队列并调度,等待执行。
工作队列对应的执行函数是linkwatch_event,这个函数就是遍历linkwatch事件的列表lweventlist,通过linkwatch_do_dev处理取出的dev,在这个阶段,端口是link的,但需要检测管理状态是不是IFF_UP的,这样就分别对应两种操作:
- dev_activate
- dev_deactivate
dev_activate函数功能如下:
- 为tx队列分配qdisc,如果不需要队列:noqueue_qdisc_ops;只有一个队列:default_qdisc_ops;有多个队列:mq_qdisc_ops,并和发送队列绑定。
- 激活watchdog,dev_watchdog_up
IFF_UP这个状态是在__dev_open阶段设置的,同时也会dev_activate激活设备,__dev_open和netif_carrier_on区别是同步和异步的区别:netif_carrier_on通过工作队列调度异步的执行分配qdisc和激活设备(若此时IFF_UP),__dev_open则是同步的执行设置IFF_UP和激活设备
2.3 总结
2.3.1 设备状态变迁
这个图来自【1】
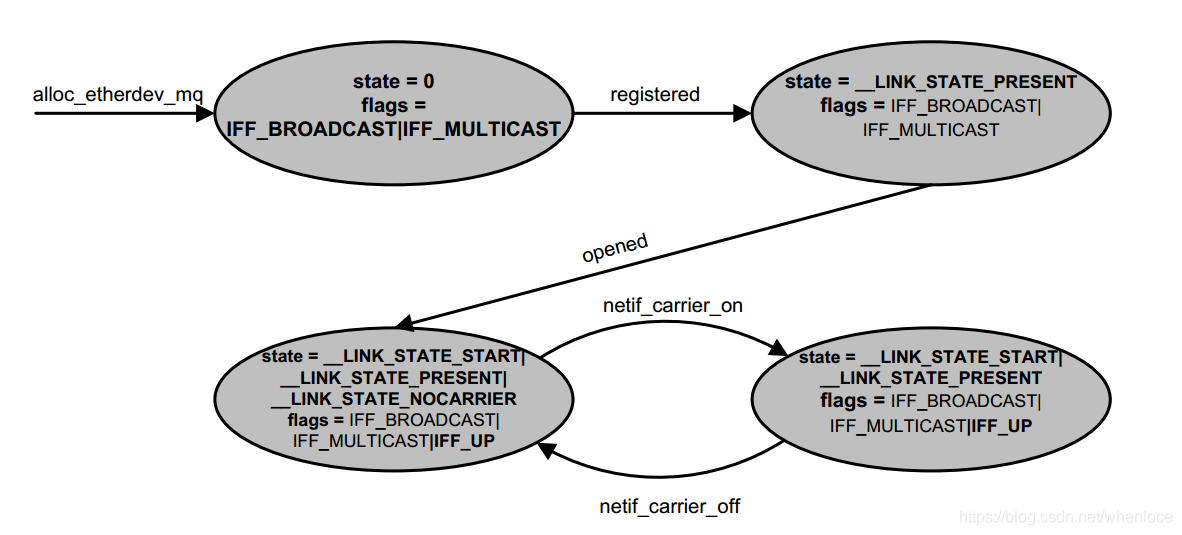
可以看出open将设备状态置为__LINK_STATE_START,flags标记为IFF_UP
而linkwatch的设备状态是__LINK_STATE_NOCARRIER
而设备状态__LINK_STATE_PRESENT是设备注册的时候产生的
2.3.2 发送和接收队列的建立
1. 分配net_device结构体时,根据队列数目分配对应的rx/tx队列对应的结构,参考下图,仍然来自【1】
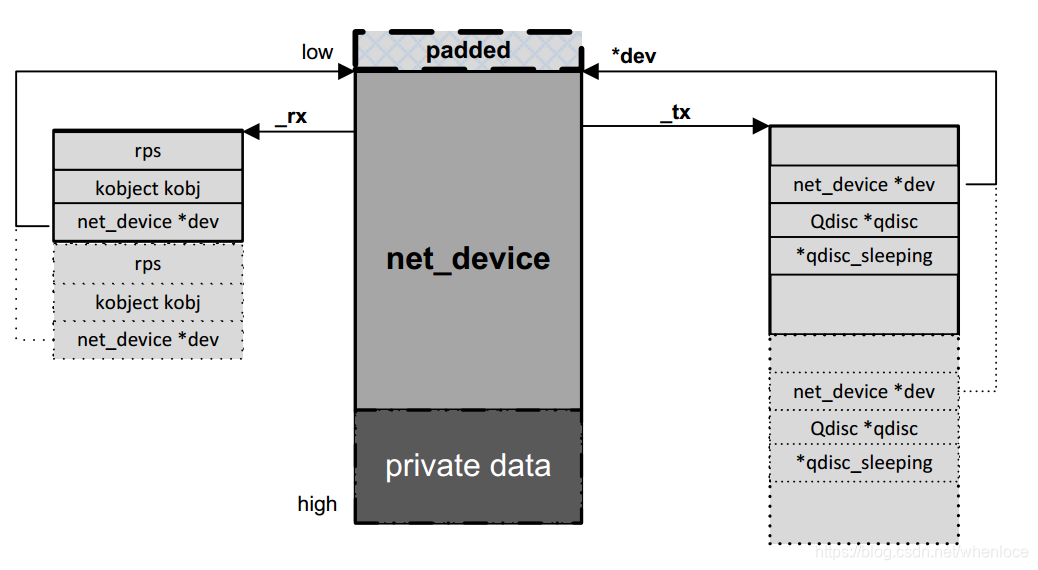
2. 注册net_device结构时,利用dev_init_scheduler函数,为发送队列指定默认的qdisc:noop_qdisc
3. 在open操作或linkwatch event(IFF_UP)时,激活设备(dev_activate),按照发送队列不同情况分配具体qdisc
2.3.3 通知链
- register call_netdevice_notifiers(NETDEV_POST_INIT, dev)
- register call_netdevice_notifiers(NETDEV_REGISTER, dev),此时网络层创建ip_ptr(in_device)
- __dev_open call_netdevice_notifiers(NETDEV_PRE_UP, dev)
- dev_open call_netdevice_notifiers(NETDEV_UP, dev);
三、从qdisc到设备发送
qdisc实际上实现了网络层到硬件设备的缓冲和控制机制,网络层调用的接口dev_queue_xmit开始
函数流程如下:
1. 通过 netdev_pick_tx选择发送队列、
2. 处理
spin_lock(root_lock);
if (unlikely(test_bit(__QDISC_STATE_DEACTIVATED, &q->state))) {
__qdisc_drop(skb, &to_free);
rc = NET_XMIT_DROP;
} else if ((q->flags & TCQ_F_CAN_BYPASS) && !qdisc_qlen(q) &&
qdisc_run_begin(q)) {
} else {
rc = q->enqueue(skb, q, &to_free) & NET_XMIT_MASK;
if (qdisc_run_begin(q)) {
if (unlikely(contended)) {
spin_unlock(&q->busylock);
contended = false;
}
__qdisc_run(q);
qdisc_run_end(q);
}
}
spin_unlock(root_lock);我们逐一分析上述情况:
- 如果qdisc状态是__QDISC_STATE_DEACTIVATED,丢包即可
- 如果qdisc 队列长度是0,且qdisc flag 是TCQ_F_CAN_BYPASS,因为没有队列,可以选择直接发送处理
- 最后一种是有队列存在的情况
对于有队列存在的情况,我们看到一开始就持有了qidsc 的lock,然后执行入队操作,接下来有三个操作:
- qdisc_run_begin
- __qdisc_run
- qdisc_run_end
static inline bool qdisc_run_begin(struct Qdisc *qdisc)
{
if (qdisc_is_running(qdisc))
return false;
/* Variant of write_seqcount_begin() telling lockdep a trylock
* was attempted.
*/
raw_write_seqcount_begin(&qdisc->running);
seqcount_acquire(&qdisc->running.dep_map, 0, 1, _RET_IP_);
return true;
}
static inline void qdisc_run_end(struct Qdisc *qdisc)
{
write_seqcount_end(&qdisc->running);
}可以看到qdisc_run_begin/qdisc_run_end就是对seqlock的一个封装,是一个不带锁的write_seqlock和write_sequnlock,由于两个的操作都是对seqcount++,所以这中间如果被打断,那么seqcount一定是奇数,在两个操作中间的操作称为run
static inline bool qdisc_is_running(const struct Qdisc *qdisc)
{
return (raw_read_seqcount(&qdisc->running) & 1) ? true : false;
}接下来分析__qdisc_run
void __qdisc_run(struct Qdisc *q)
{
int quota = dev_tx_weight;
int packets;
while (qdisc_restart(q, &packets)) {
/*
* Ordered by possible occurrence: Postpone processing if
* 1. we've exceeded packet quota
* 2. another process needs the CPU;
*/
quota -= packets;
if (quota <= 0 || need_resched()) {
__netif_schedule(q);
break;
}
}
}函数的逻辑很简单,每次处理一定数量的包,如果到达处理上限或者需要进程调度就将报文推迟到发包软中断处理
static void __netif_reschedule(struct Qdisc *q)
{
struct softnet_data *sd;
unsigned long flags;
local_irq_save(flags);
sd = this_cpu_ptr(&softnet_data);
q->next_sched = NULL;
*sd->output_queue_tailp = q;
sd->output_queue_tailp = &q->next_sched; //将qdisc挂到softnet
raise_softirq_irqoff(NET_TX_SOFTIRQ); //触发软中断
local_irq_restore(flags);
}
void __netif_schedule(struct Qdisc *q)
{
if (!test_and_set_bit(__QDISC_STATE_SCHED, &q->state))
__netif_reschedule(q);
}这里把软中断的发包流程也展开:
在net_dev_init
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
if (sd->output_queue) {
struct Qdisc *head;
local_irq_disable();
head = sd->output_queue;
sd->output_queue = NULL;
sd->output_queue_tailp = &sd->output_queue;
local_irq_enable();
while (head) {
struct Qdisc *q = head;
spinlock_t *root_lock = NULL;
head = head->next_sched;
qdisc_run(q);
if (root_lock)
spin_unlock(root_lock);
}
}在软中断中调用qdisc_run继续
static inline void qdisc_run(struct Qdisc *q)
{
if (qdisc_run_begin(q)) {
__qdisc_run(q);
qdisc_run_end(q);
}
}其中qdisc_restart如下:
static inline bool qdisc_restart(struct Qdisc *q, int *packets)
{
bool more, validate, nolock = q->flags & TCQ_F_NOLOCK;
spinlock_t *root_lock = NULL;
struct netdev_queue *txq;
struct net_device *dev;
struct sk_buff *skb;
skb = dequeue_skb(q, &validate, packets);
if (!nolock)
root_lock = qdisc_lock(q);
dev = qdisc_dev(q);
txq = skb_get_tx_queue(dev, skb);
more = sch_direct_xmit(skb, q, dev, txq, root_lock, validate);
if (nolock)
clear_bit(__QDISC_STATE_RUNNING, &q->state);
return more;
}只捡重要的贴了
bool sch_direct_xmit(struct sk_buff *skb, struct Qdisc *q,
struct net_device *dev, struct netdev_queue *txq,
spinlock_t *root_lock, bool validate)
{
int ret = NETDEV_TX_BUSY;
bool again = false;
/* And release qdisc */
if (root_lock)
spin_unlock(root_lock);
if (likely(skb)) {
HARD_TX_LOCK(dev, txq, smp_processor_id());
if (!netif_xmit_frozen_or_stopped(txq))
skb = dev_hard_start_xmit(skb, dev, txq, &ret);
HARD_TX_UNLOCK(dev, txq);
} else {
}
if (root_lock)
spin_lock(root_lock);
return true;
}这里先unlock qdisc的lock,这样在处理的同时可以通过dev_queue_xmit继续执行enqueue操作,在这种情况下进来的发送
contended = qdisc_is_running(q);
if (unlikely(contended))
spin_lock(&q->busylock);注意虽然解锁了,但是seqcount目前仍是奇数,所以qdisc_is_running是真,此时在enqueue之后进行qdisc_run_begin检测到running后就直接返回了,不继续进行出队发包处理,事实上进行了串行化的操作。
而在dev_hard_start_xmit之后,就调用到驱动的发包接口了。
四、报文的接收流程
一般的hardirq中完成报文的copy(当然性能高的基本都是轮询的了,数据面转发也没有什么hardirq和softirq什么事)。
4.1 NAPI
napi是在中断中触发软中断,由在softirq上下文对收包进行轮询
1. 初始化时利用netif_napi_add,添加自己的napi poll处理,其实就是通过一个napi_struct结构将poll和一些信息管理起来。
2. nic的中断处理流程调用napi_schedule_irqoff(注意这时候nic的hardirq是关闭的),将napi 的poll_list加入到soft_data的poll上,并触发一个软中断。
3. 我们直接看下softirq的处理过程:
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
软中断中调用从soft_net的poll list取出napi,通过napi_poll调用1中add的驱动实现的poll函数
4.驱动实现的poll函数执行硬件相关的收报函数,收报的数量控制在budget个,调用上层的结构是netif_receive_skb
5. 收包完成后调用napi_complete_done,将设备从poll list移除,打开nic中断
4.2 netif_rx
netif_rx也使用的napi机制,称为backlog,根据上节的的说明步骤来分析:
1. 在net_dev_init中,注册backlog napi,它的poll函数称为、
2. 在netif_rx中,主要调用netif_rx的一个重要操作就是enqueue_to_backlog,将skb入sd->input_pkt_queue队列,触发一个软中断
static int enqueue_to_backlog(struct sk_buff *skb, int cpu,
unsigned int *qtail)
{
struct softnet_data *sd;
unsigned long flags;
unsigned int qlen;
sd = &per_cpu(softnet_data, cpu);
local_irq_save(flags);
qlen = skb_queue_len(&sd->input_pkt_queue); //收报入队
if (qlen <= netdev_max_backlog && !skb_flow_limit(skb, qlen)) {
if (qlen) {
enqueue:
__skb_queue_tail(&sd->input_pkt_queue, skb);
input_queue_tail_incr_save(sd, qtail);
rps_unlock(sd);
local_irq_restore(flags);
return NET_RX_SUCCESS;
}
goto enqueue;
}
}
3. 在软中断流程中调用poll函数,对backlog napi来说就是著名的process_backlog
4. 没有什么特别的就是出队加上netif_receive_skb
while (again) {
struct sk_buff *skb;
while ((skb = __skb_dequeue(&sd->process_queue))) {
rcu_read_lock();
__netif_receive_skb(skb);
rcu_read_unlock();
input_queue_head_incr(sd);
if (++work >= quota)
return work;
}
local_irq_disable();
if (skb_queue_empty(&sd->input_pkt_queue)) {
napi->state = 0;
again = false;
} else {
skb_queue_splice_tail_init(&sd->input_pkt_queue,
&sd->process_queue);
}
local_irq_enable();
}五、参考
【1】深入 Linux 设备驱动程序内核机制