版权声明: https://blog.csdn.net/qq_41880190/article/details/89404577
海量数据处理思路
1. 计算容量
在解决问题之前,要先计算一下海量数据需要占多大的容量。常见的单位换算如下:
- 1 byte = 8 bit
- 1 KB = 210 byte = 1024 byte ≈ 103 byte
- 1 MB = 220 byte ≈ 10 6 byte
- 1 GB = 230 byte ≈ 10 9 byte
- 1 亿 = 108
1 个整数占 4 byte,1 亿个整数占 4*108 byte ≈ 400 MB。
2. 拆分
可以将海量数据拆分到多台机器上和拆分到多个文件上:
- 如果数据量很大,无法放在一台机器上,就将数据拆分到多台机器上。这种方式可以让多台机器一起合作,从而使得问题的求解更加快速。但是也会导致系统更加复杂,而且需要考虑系统故障等问题;
- 如果在程序运行时无法直接加载一个大文件到内存中,就将大文件拆分成小文件,分别对每个小文件进行求解。
有以下策略进行拆分:
- 按出现的顺序拆分:当有新数据到达时,先放进当前机器,填满之后再将数据放到新增的机器上。这种方法的优点是充分利用系统的资源,因为每台机器都会尽可能被填满。缺点是需要一个查找表来保存数据到机器的映射,查找表可能会非常复杂并且非常大。
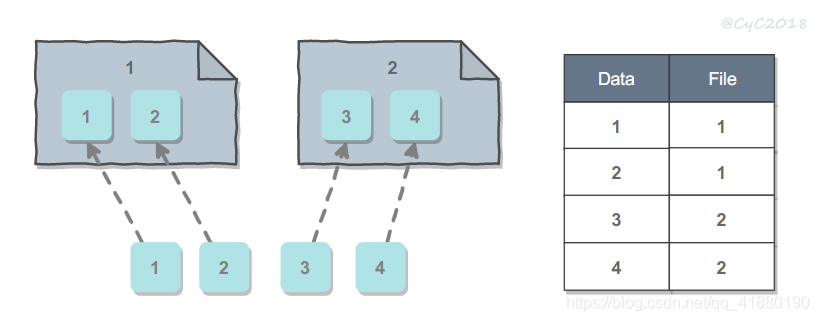
- 按散列值拆分:选取数据的主键 key,然后通过哈希取模 hash(key)%N 得到该数据应该拆分到的机器编号,其中 N 是机器的数量。优点是不需要使用查找表,缺点是可能会导致一台机器存储的数据过多,甚至超出它的最大容量。

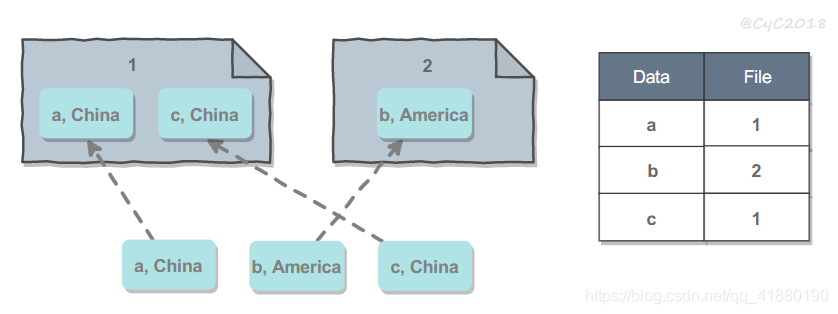
- 按数据的实际含义拆分:例如一个社交网站系统,来自同一个地区的用户更有可能成为朋友,如果让同一个地区的用户尽可能存储在同一个机器上,那么在查找一个用户的好友信息时,就可以避免到多台机器上查找,从而降低延迟。缺点同样是需要使用查找表。
3. 整合
拆分之后的结果还只是局部结果,需要将局部结果汇总为整体的结果。