这篇文章主要想回答两个“为什么”的问题:1、为啥我就对SVD感兴趣了?;2、为啥我说SVD是一个聚类过程?回答的内容纯粹个人思辨结果,暂无参考文献。
为什么要研究SVD? #
从2015年接触深度学习到现在,已经研究了快两年的深度学习了,现在深度学习、数据科学等概念也遍地开花。为什么在深度学习火起来的时候,我反而要回去研究“古老”的SVD分解呢?我觉得,SVD作为一个矩阵分解算法,它的价值不仅仅体现在它广泛的应用,它背后还有更加深刻的内涵,即它的可解释性。在深度学习流行的今天,不少人还是觉得深度学习(神经网络)就是一个有效的“黑箱”模型。但是,仅用“黑箱”二字来解释深度学习的有效性显然不能让人满意。前面已经说过,SVD分解本质上与不带激活函数的三层自编码机等价,理解SVD分解,能够为神经网络模型寻求一个合理的概率解释。
近来,我尝试做一些较为复杂的模型,比如问答系统、聊天机器人,我越来越感觉到,刚开始上手的时候,最近大放异彩的seq2seq之类的深度学习模型基本没法用。我基本上是从最基本的概率模型P(A|Q)出发,逐步简化,最后得到一个复杂度可以接受的模型。这样得到的模型意义清晰、可控性强。但是其中的一部分是基于统计来做的,纯粹的统计没法得到真正“智能”的结果,而前面说过,SVD分解可以在统计结果的基础上带来初步的智能。这给我强烈的感觉,一个是模型的可解释性尤其是概率解释是很重要的,另外一个是更好理解了SVD之后,对神经网络模型的意义和应用都更有感觉了。
SVD分解是怎么聚类的? #
为什么SVD分解是聚类?其实这里边是一个很简单的概率模型。
给定矩阵Mm×n,不失一般性,假设它每个元素都是非负数,这样我们就可以对每一行做归一行,这样,得到的矩阵可以表示一个转移概率
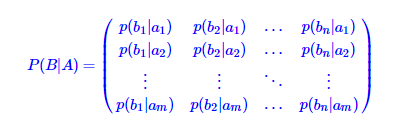
归一化条件是
∑j=1np(bj|ai)=1,i=1,2,…,m
所谓p(bj|ai),即ai后接bj的概率,这种概率模型是很常见的,比如二元语言模型。
现在我们假设各个ai可以聚为l个类,分别为c1,c2,…,cl;而各bi可以聚为k个类,分别为d1,d2,…,dk;我们要研究ai后接bj的规律,事实上可以简化为类别之间的规律(一个典型的小案例就是:我们将词语分为动词、名词、形容词等,然后发现动词后面可以接名词构成短语,“动词+名词”就是我们大脑发现的聚类规律了)。这就是SVD分解的唯一假设了。更清晰地,假设包括:
1、ai和bi都可以聚为若干个类;
2、ai和bi之间的连接规律可以简化为两者所属的类的连接规律。
这时候根据概率公式,就得到
p(bj|ai)=∑k,lp(bj|dk)p(dk|cl)p(cl|ai)
每一项都有非常清晰的概率意义:
p(cl|ai)是ai表现为类别cl的概率;
p(dk|cl)是类别cl后接类别dk概率;
p(bj|dk)是已知类别dk时,元素为bj的概率。
这样自然有p(bj|ai)=∑k,lp(bj|dk)p(dk|cl)p(cl|ai),也就是说,只要假设成立,那么这个公式是精确成立的。而这个运算,正好是三个矩阵的乘法:
P(B|A)=P(B|D)×P(D|C)×P(C|A)
也就是说,一个矩阵分解为三个维度更低的矩阵相乘,这不就是SVD分解吗?当然,细致上的区别是,如果是概率分解,则需要有归一化要求,这部分内容属于主题模型中pLSA模型的内容,而SVD分解本身不需要归一化约束,但这不影响本质思想,即矩阵分解蕴含了聚类的意义在里边。
这样,我们就通过矩阵分解,来对行与列进行了聚类。我们不需要告诉计算机聚成哪些类(比如,不需要告诉计算机要将词语分为名词、动词、形容词等),而是直接矩阵分解来完成(试想一下,只要用“大声公”喊一声“集合啦,要聚类啦”,大家自动分好类,不用我们告诉它怎么做。)。或者反过来说,我们通过概率模型,为SVD分解赋予了聚类意义。
新年快乐 #
额…本来感觉一两句话可以讲清楚的事情,又扯了那么多文字,希望读者不要觉得我哆嗦_
再次祝大家新年快乐啦,年年都是那句:希望大家多多捧场!
转载到请包括本文地址:https://spaces.ac.cn/archives/4216