安装spark之前需要安装scala-2.12.6
spark初始目录状态

配置scala环境变量
vim ~/.bash_profile
![]()

export SCALA_HOME=/home/hadoop/spark/scala-2.12.6
${SCALA_HOME}/bin
键入source ~/.bash_profile使scala环境变量立刻生效
键入scala -version验证scala环境变量是否配置正确

配置spark环境变量
vim ~/.bash_profile

export JAVA_HOME=/home/hadoop/work/jdk1.8.0_171
export SCALA_HOME=/home/hadoop/spark/scala-2.12.6
export SPARK_HOME=/home/hadoop/spark/spark-2.1.0-bin-hadoop2.6
export SOLR_HOME=/home/hadoop/solrcloud/solr-5.2.0
export ZOOKEEPER_HOME=/home/hadoop/zookeeper/zookeeper-3.4.10
export HADOOP_HOME=/home/hadoop/hadoop/hadoop-2.6.0
export JRE_HOME=${JAVA_HOME}/jre
export CLASS_PATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH:$HOME/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${ZOOKEEPER_HOME}/bin:${SOLR_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:${SPARK_HOME}/sbin
键入source ~/.bash_profile使spark环境变量立刻生效
键入spark-shell验证spark环境变量是否配置正确

修改spark配置文件
spark配置文件初始状态

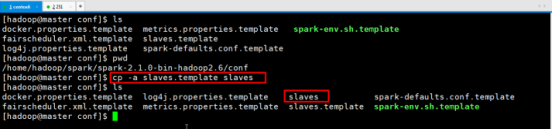
修改slaves
cp -a slaves.template slaves
vim slaves

master
slave1
slave2
hostname=master的节点既是master节点又是worker节点
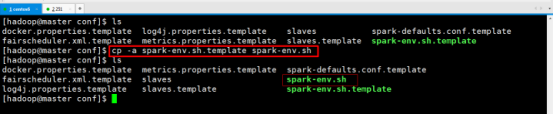
修改spark-env.sh
cp -a spark-env.sh.template spark-env.sh
vim spark-env.sh

export JAVA_HOME=/home/hadoop/work/jdk1.8.0_171
export SCALA_HOME=/home/hadoop/spark/scala-2.12.6
export SPARK_MASTER_IP=192.168.218.133
export HADOOP_CONF_DIR=/home/hadoop/hadoop/hadoop-2.6.0/etc/hadoop
export SPARK_WORKER_MOMORY=512M
解释:
SPARK_MASTER_IP指定spark集群master节点的ip地址
HADOOP_CONF_DIR指定hadoop集群配置文件目录
SPARK_WORKER_MOMORY指定worker节点能够分配给executors的最大内存大小
同步spark到集群其他节点上并配置环境变量
cd ~
scp -r spark hadoop@slave1:$PWD
scp -r spark hadoop@slave1:$PWD
启动hadoop集群
start-dfs.sh && start-yarn.sh
启动spark集群
start-master.sh && start-slaves.sh
验证spark集群是否启动成功
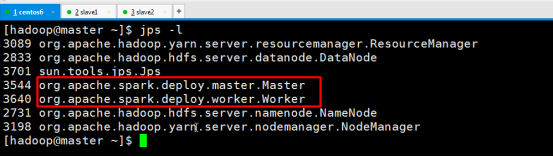
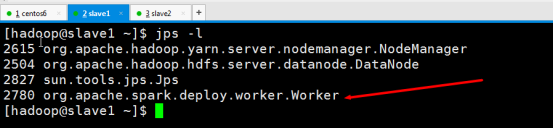

浏览器查看spark集群信息http://192.168.218.133:8080/

停止spark集群
stop-slaves.sh && stop-master.sh