对于各种语言的学习,环境搭建是学习的第一步,本文对Hadoop和Spark的单机及分布式集群的环境搭建步骤详述如下,供大家参考(文章较长,可以只关注自己需要的部分,常见问题及解决方法本文及另一篇博客也有介绍,博客 地址:https://blog.csdn.net/m0_37568814/article/details/80785445)。
一、平台环境:
虚拟机 VMware Workstation Pro虚拟机操作系统:Ubuntu16.04Windows Server 2008
二、 软件配套版本包:
jdk-7u80-linux-x64(java version 1.7.0_80)Hadoop 2.6.5
Hadoop-native-64-2.6.0
Scala-2.11.11
Spark-2.1.1-bin-hadoop2.7
三、Hadoop 单机环境及伪分布式安装步骤:
1.在 VMware 上新建三个虚拟机(Master,Slave1,Slave2),其中 Master,Slave用于集群环境的搭建。Slave2 用于 Hadoop 单机环境及伪分布式环境搭建。
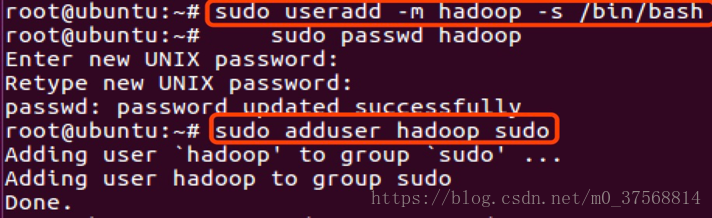
2.在三个虚拟机上分别创建 hadoop 用户
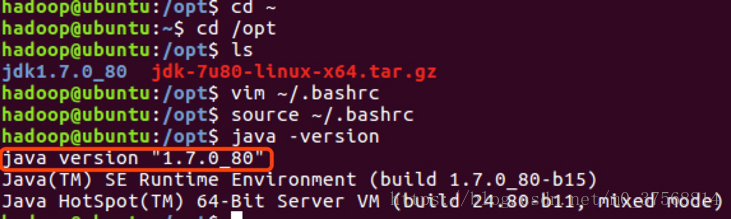
3.三个虚拟机在 hadoop 用户下分别安装 jdk
1) 下载 jdk-7u80-linux-x64.tar.gz,上传下载包到/opt 目录。
2) 使用命令tar –xf jdk-7u80-linux-x64.tar.gz解压压缩包到当前文件夹。
3) 使用命令配置vim ~/.bashrc配置文件,配置环境变量(详见下图),之后使用命令source ./.bashrc 使文件修改生效。
4) 使用命令java –version检查 jdk 是否安装成功。


4.更新 apt

5.安装 vim

6.安装 SSH,配置 SSH 无密码登陆
1) 使用命令安装 ssh server: $sudo apt-get install openssh-server

2) 启动 SSH 服务

3) 之后使用命令 ssh localhost测试是否成功,使用如下命令设置无密码登陆。
$exit # 退出刚才的 ssh localhost
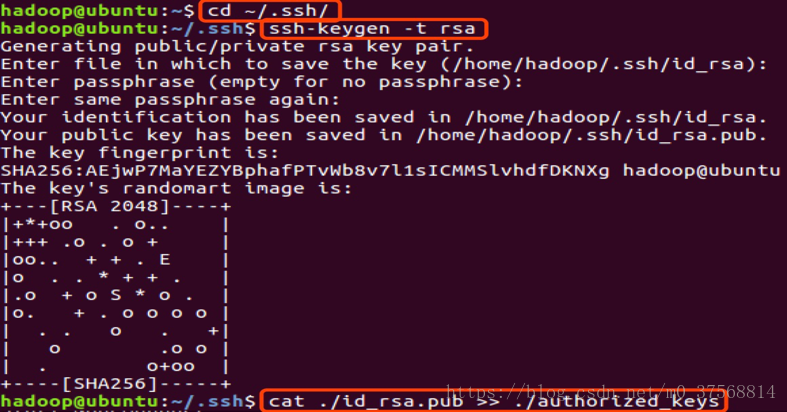
$cd ~/.ssh/ # 若没有该目录,请先执行一次 ssh localhost
$ssh-keygen -t rsa # 会有 示,都按回车就可以
$cat ./id_rsa.pub >> ./authorized_keys # 加入授权

7.安装配置 Hadoop
1) 从官网下载文件 Hadoop2.6.5,上传到 usr/local 下,配置.bashrc 文件,并使用命令 source ~/.bashrc 使修改生效。
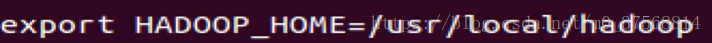
2) 使用命令 hadoop version 检查 Hadoop 是否安装成功

8. Hadoop 单机配置(非分布式),使用如下命令查看单机配置下的执行结果
$cd /usr/local/hadoop
$mkdir ./input
$cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
$./bin/hadoop
jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar
$grep ./input ./output 'dfs[a-z.]+'
$cat ./output/* # 查看运行结果

至此,Hadoop 单机配置安装测试完成。
9. 配置 Hadoop 伪分布式:
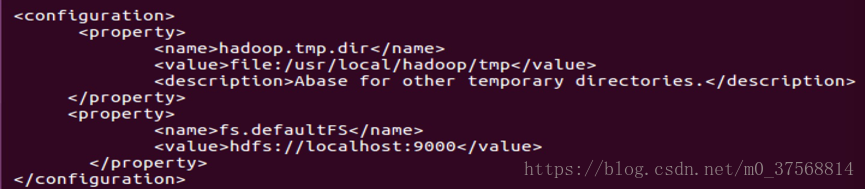
1) 按照如下方式编辑文件 vim ./etc/hadoop/core-site.xml
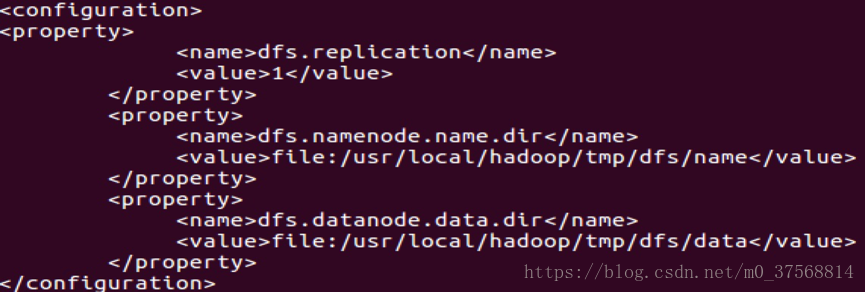
2) 编辑文件 vim ./etc/hadoop/hdfs-site.xml,修改如下
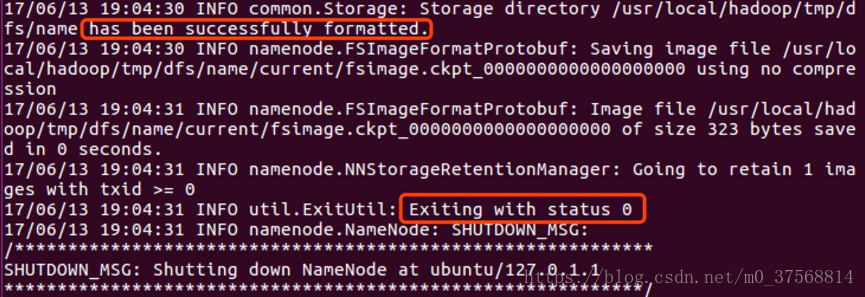
3) 配置完成后,执行 NameNode 的格式化$./bin/hdfs namenode –format,出现以下 status 0 表示格式化成功。
10. 开启 NameNode 和 DataNode 守护进程 $./sbin/start-dfs.sh

11. 进程开启后,使用 jps 命令查看节点情况
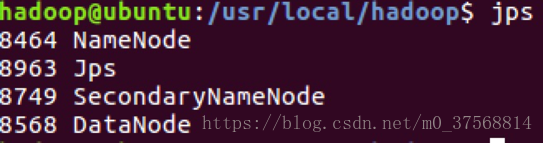
12. 登陆前台 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode信息及在线查看 HDFS 中的文件

13. 运行 Hadoop 伪分布式示例使用以下命令运行及查看示例运行结果:
$./bin/hdfs dfs -mkdir input
$./bin/hdfs dfs -put ./etc/hadoop/*.xml input
$./bin/hdfs dfs -ls input
$./bin/hadoop
jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input
output 'dfs[a-z.]+'
$./bin/hdfs dfs -cat output/*



14. 启动 YARN
1) 修改配置文件 mapred-site.xml,首先进行重命名:
$mv ./etc/hadoop/mapred-site.xml.template ./etc/hadoop/mapred-site.xml
2) 编辑./etc/hadoop/mapred-site.xml,如下所示

3) 编辑./etc/hadoop/yarn-site.xml 如下所示

4) 修改完成后,启动 YARN

5) 启动 YARN 成功后,使用命令 jps 检查节点信息如下,相比只启动 hadoop时多了 ResourceManager 和 NodeManager 进程。

15.通过 Web 界面查看任务运行情况:http://localhost:8088/cluster,如下图所示。

Hadoop 伪分布式环境搭建完成。
四. Hadoop 集群安装配置
1. 集群环境:一个 master 主机,一个 slave 主机。其中选择主机 IP 为115.157.200.152 作为 master,IP 为 115.157.200.163 的主机作为 slave。安装单机部署的步骤完成以下工作:
· 在 master 节点上配置 hadoop 用户、安装 SSH server、安装 Java 环境
· 在 master 节点上安装 Hadoop,并完成配置
· 在其他 slave 节点上配置 hadoop 用户、安装 SSH server、安装 Java 环境· 将 master 节点上的 /usr/local/hadoop 目录复制到 slave 节点上
· 在 master 节点上开启 Hadoop
2. 检查主机名称是否为 master 和 slave,如果不是,修改配置文件/etc/hostname和/etc/hosts,修改完成后 reboot 重启服务器。
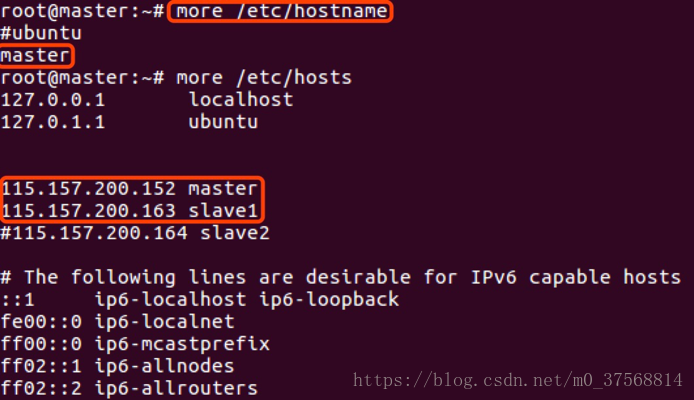
3. 按照单机部署方式安装 jdk,配置 SSH 登陆,配置 Hadoop。集群/分布式模式需要修改 /usr/local/hadoop/etc/hadoop 中的 5 个配置文件,更多设置项可点击查看官方说明,这里仅设置了正常启动所必须的设置项:core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、slaves。
1) 修改如下:core-site.xml

2) 修改 hdfs-site.xml
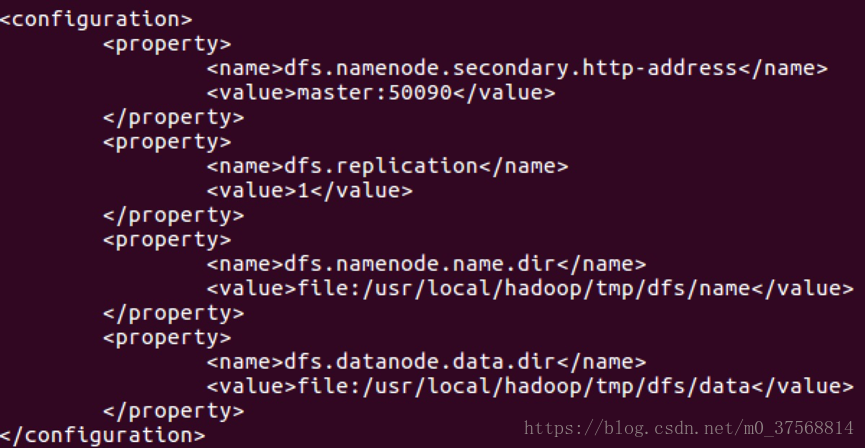
3) mapred-site.xml

4) yarn-site.xml
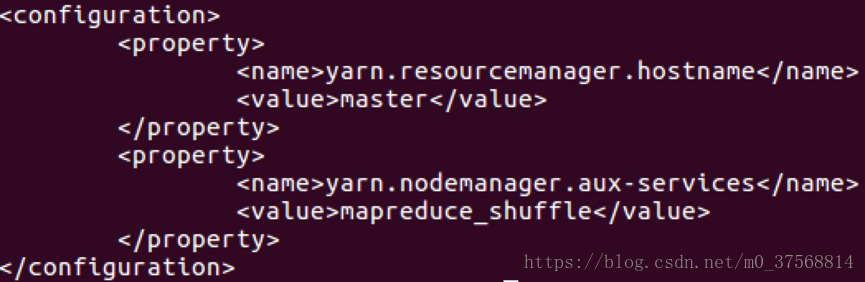
5) slaves

4. 配置好后,将 master 上的 /usr/local/hadoop 文件夹复制到 slave 节点上。因为之前有跑过伪分布式模式,建议在切换到集群模式前先删除之前的临时文件。
1) 在 master 节点上执行:
$cd /usr/local
$sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件
$sudo rm -r ./hadoop/logs/* # 删除日志文件
$tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
$cd ~
$scp ./hadoop.master.tar.gz slave1:/home/hadoop
2) 在 slave1 节点上执行:
$sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)
$sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
$sudo chown -R hadoop /usr/local/hadoop
5. 首次启动需要先在 master 节点执行 NameNode 的格式化:
$ hdfs namenode -format # 首次运行需要执行初始化,之后不需要
6. 启动 hadoop,在 master 节点上进行:
$start-dfs.sh
$start-yarn.sh
$mr-jobhistory-daemon.sh start historyserver
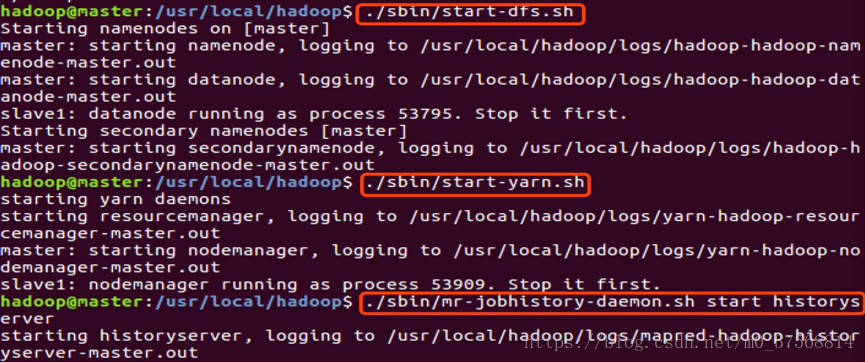
7. 通过命令 jps 可以查看各个节点所启动的进程。
1) 启动成功,在 master 节点上可以看到 NameNode、ResourceManager、SecondrryNameNode、JobHistoryServer 进程,如下图所示:

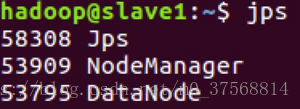
2) 在 slave 节点可以看到 DataNode 和 NodeManager 进程,如下图所示:
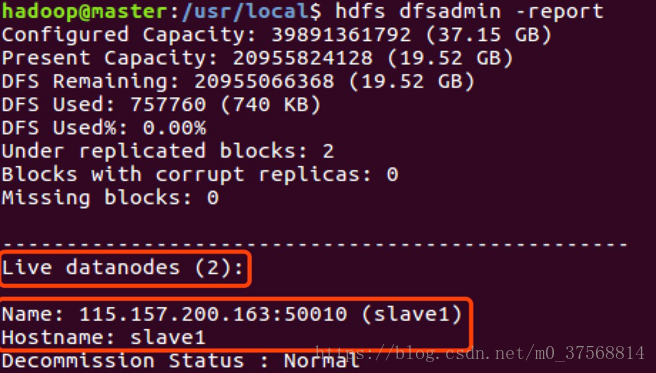
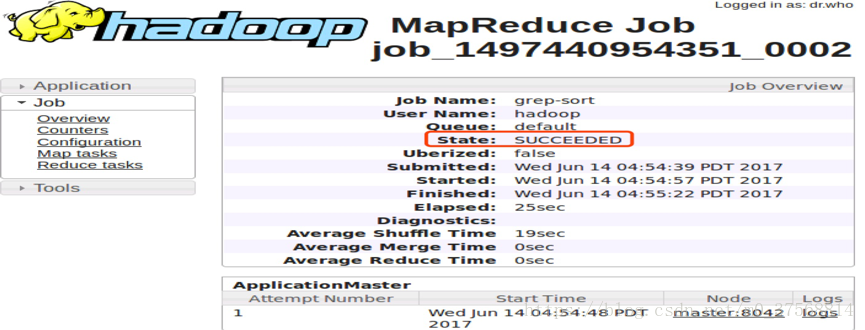
3) 在 master 节点上通过命令 hdfs dfsadmin -report 查看 DataNode 是否正常启动,如果 Live datanodes 不为 0 ,则说明集群启动成功。
8. 通过 Web 页面看到查看 DataNode 和 NameNode 的状态:http://master:50070/。


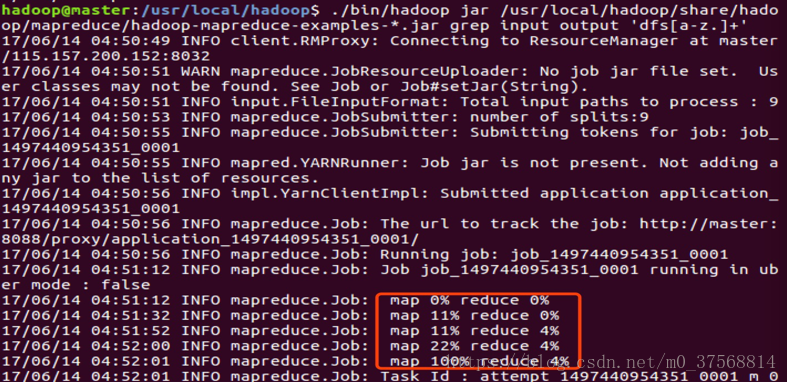
9. 在 Hadoop 分布式集群上运行示例如下。命令类似于伪分布式集群。
$hdfs dfs -mkdir -p /user/hadoop
$hdfs dfs -mkdir input
$hdfs dfs -put /usr/local/hadoop/etc/hadoop/*.xml input
$hadoop jar
/usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.j
ar grep input output 'dfs[a-z.]+'
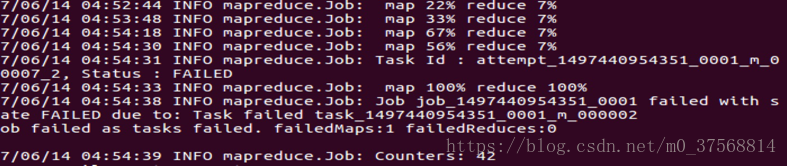
10. 通过 Web 界面查看任务进度 http://master:8088/cluster,在 Web 界面点击 Tracking UI 这一列的 History 连接,可以看到任务的运行信息,如下图所示:


至此,Hadoop 集群搭建完成。
五. Spark 集群的搭建
分别在 master 和 slave 机器上完成 scala 和 spark 的安装。
1. scala 安装:
1) 下载scala-2.11.11.tgz,解压到 /opt 目录下,即:/opt/scala-2.11.11。
2) root 用户修改 scala-2.11.11 目录所属用户和用户组为 hadoop,使用命令 sudo chown -R hadoop:hadoop scala-2.11.11,修改环境变量 vim ~/.bashrc,添加如下内容:

3) 添加完成后,使用命令 source ~/.bashrc 使其生效。
4) 测试 scala 安装是否成功,出现如下所示界面,测试验证成功。

2. Spark 的安装:
1) 下载 Spark-2.1.1-bin-hadoop2.7.tgz,解压到 /opt 目录下并重命名为spark。
修改 spark 目录所属用户和用户组$sudo chown -R hadoop:hadoop spark。
2) 修改环境变量 vim ~/.bashrc,添加如下内容:

3) 添加完成后,使用命令 source ~/.bashrc 使其生效。
4) 进入 Spark 安装目录下的 conf 目录,拷贝 spark-env.sh.template到 spark-env.sh。cp spark-env.sh.template spark-env.sh
编辑 spark-env.sh,在其中添加以下配置信息:
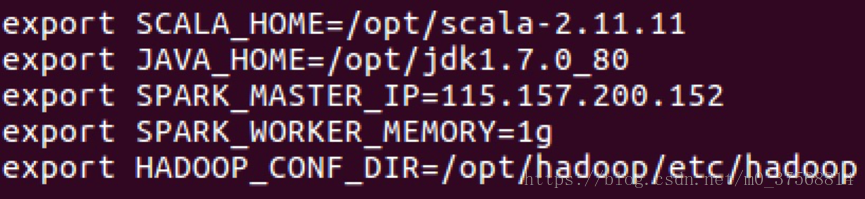
SCALA_HOME:指定 Scala 安装目录;
JAVA_HOME:指定 Java 安装目录;
SPARK_MASTER_IP:指定 Spark 集群 master 节点的 IP 地址;SPARK_WORKER_MEMORY: 指 定 的 是 Worker(Slave) 节 点 能 够 分 配 给Executors 的最大内存大小;
HADOOP_CONF_DIR:指定 Hadoop 集群配置文件目录。
5) 将 slaves.template 拷贝到 slaves, 编辑其内容为:

4. 启动 Spark 集群
1) 启动 hadoop 集群:在 hadoop 安装目录下,用命令./sbin/start-dfs.sh 启动hadoop 集群,用 jps 命令分别在 master 和 slave 上查看进程信息(参考 hadoop集群搭建相关介绍)。
2) 启动 spark 集群,在 master 节点上运行 start-master.sh,结果如下:

可以看到 master 上多了一个新进程 Master。
3) 在 master 节点上启动 worker(这里即为 slave),运行 start-slaves.sh,结果如下:
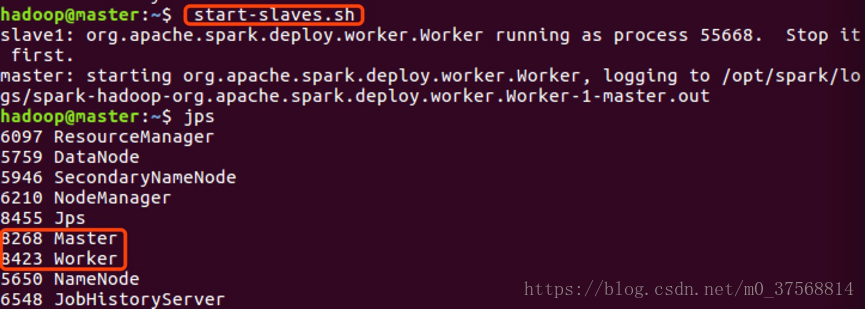
可以看到,多了一个 Worker 进程。
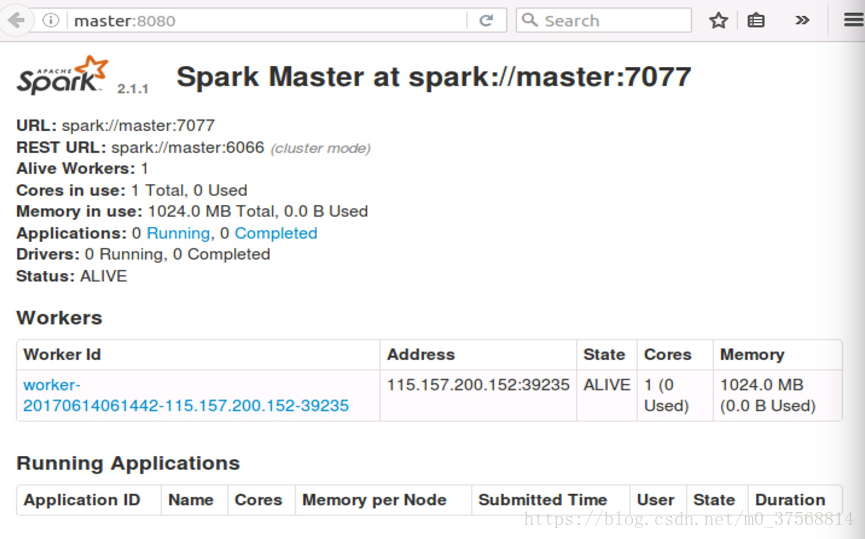
4) 前台界面查看 Spark 集群信息。浏览器中输入:http://master:8080, 如下图:
5) 运行 spark-shell,可以进入 Spark 的 shell 控制台,如下:

6) 浏览器访问 SparkUI
浏览器中输入: http://master:4040, 如下图:

可以从 SparkUI 上查看一些 如环境变量、Job、Executor 等信息。至此,整个 Spark 分布式集群的搭建完成。
7) 停止集群时,运行 stop-master.sh 来停止 Master 节点, 之后运行可以停止所有的 Worker 节点,Worker 进程停止完成后,最
后使用命令 停止 Hadoop 集群。
六. Spark 示例分析
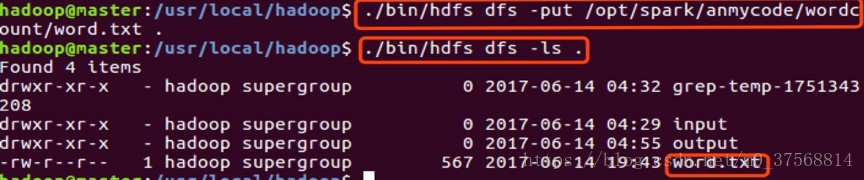
1. 编写一个 Spark 应用程序,对某个文件中的单词进行词频统计。hadoop 用户下执行如下命令:
stop-slaves.sh
$cd /opt/spark
./sbin/stop-dfs.sh
$mkdir anmycode
$cd anmycode
$mkdir wordcount
$cd wordcount
$vim word.txt
使用命令 spark-shell 启动 spark-shell 如下所示表示成功:
在 spark 终端,输入如下命令:
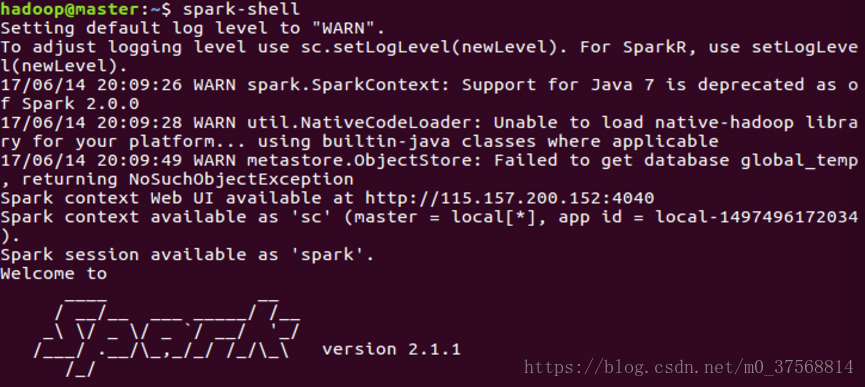
scala>val textFile = sc.textFile("file:///opt/spark/anmycode/wordcount/word.txt")
scala>textFile.first()

first()是一个“行动”(Action)类型的操作,会启动真正的计算过程,从文件中加载数据到变量 textFile 中,并取出第一行文本。屏幕上会显示很多反馈信息,这里不再给出,你可以从这些结果信息中,找到 word.txt 文件中的第一行的内容。Spark 采用了惰性机制,在执行转换操作的时候,即使我们输入了错误的语句,spark-shell 也不会马上报错,而是等到执行“行动”类型的语句时启动真正的计算,那个时候“转换”操作语句中的错误就会显示出来。如下所示:

4. 加载 HDFS 中的文件(参考 Hadoop 搭建介绍)
cd /opt/hadoop
./sbin/start-dfs.sh
./bin/hdfs dfs -mkdir -p /user/hadoop
注意:这个目录是在 HDFS 文件系统中,不在本地文件系统中。创建好以后,下面我们使用命令查看一下 HDFS 文件系统中的目录和文件:
./bin/hdfs dfs -ls .
5. 切换回到 spark-shell 窗口,编写语句从 HDFS 中加载 word.txt 文件,并显示第一行文本内容:
scala>val textFile = sc.textFile("hdfs://master:9000/user/hadoop/word.txt")
scala>textFile.first()

6) 将 HDFS 上的文本保存到 write back 目录下,并查看



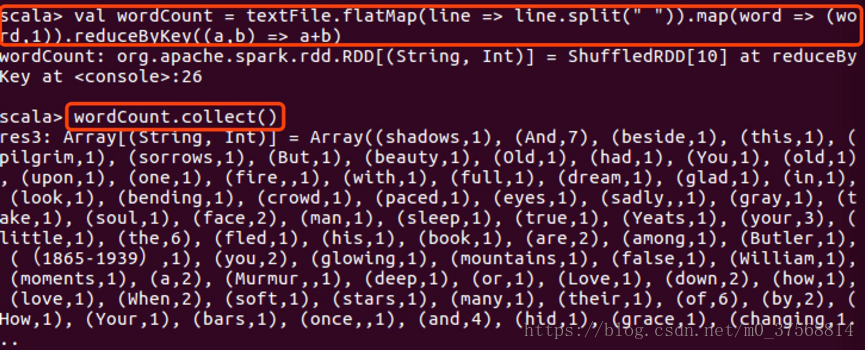
6. 词数统计:
scala>val textFile = sc.textFile("file:///opt/spark/anmycode/wordcount/word.txt")
scala>val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word,
1)).reduceByKey((a, b) => a + b)
scala>wordCount.collect()
测试完成。
七. 常用命令
常用 Hadoop 命令
1. 启动Hadoop(NameNode 和 DataNode 守护进程):
$hdfs namenode -format # 首次运行需要执行初始化,之后不需要
$ ./sbin/start-dfs.sh
2. 关闭 Hadoop:./sbin/stop-dfs.sh
3. 启动yarn: 先启动Hadoop,再使用命令 ./sbin/start-yarn.sh
4. 关闭yarn:
1) ./sbin/stop-yarn.sh
2) ./sbin/mr-jobhistory-daemon.sh stophistoryserver
5. 查看hadoop版本:/usr/local/hadoop下使用./bin/hadoopversion
6. 测试命令:/usr/local/hadoop下使用
./bin/hadoopjar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output'dfs[a-z.]+’
7. 查看运行结果的命令(查看的是位于 HDFS中的输出结果):
./bin/hdfs dfs -cat output/*
8. 集群的Master节点启Hadoop
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
9. 查看各个节点所启动的进程jps
常用Spark命令:
启动 Master 节点: Master主机上:start-master.sh
启动所有 Worker 节点:Master主机运行:start-slaves.sh
运行 spark-shell,可以进入 Spark 的 shell 控制台
测试命令:Spark中运行示例程序JavaWordCount.java,程序所在目录如下
(Spark安装目录):./examples/src/main/java/org/apache/spark/examples/JavaWordCount.java
常用Hadoop&YARN web界面URL:
1. http://localhost:50070 ---查看 NameNode 和 Datanode 信息,在线查看HDFS 中的文件
2. 查看任务的运行情况http://localhost:8088/cluster(单机)http://master:8088/cluster(集群)
常用Spark web界面URL:
http://master:8080---浏览器查看 Spark 集群信息
http://master:4040---浏览器访问 SparkUI
八. 遇到的问题及解决方法
1. 虚拟机 root用户默认密码修改: sudo passed 回车修改密码
hostname设置(master,slave1),修改/etc/hosts和/etc/hostname
ping命令无法使用:虚拟机设置,选择网络连接方式(桥接方式)
ssh命令报错: connect to host slave1 port 22: Connection refused
解决方法:安装并启动ssh服务,安装如下:apt-get install -f
apt-get install openssl-client---ubuntu 默认安装
apt-get install openssl-server
sudo /etc/init.d/ssh start—启动 ssh 服务
安装jdk时,手动下载软件包(jdk1.7版本:jdk-7u80-linux-x64),之后配置./bashrc文件。
安装过程中启动hadoop时报JAVA_HOME路径找不到。 解决方法:检查~/bashrc 设置正确。检查设置hadoop的安装路径下:/usr/local/hadoop/etc/hadoop中的hadoop-env.sh中JAVA_HOME需要设置为jdk所在的目录。
运行hdfs在/user下新建hadoop文件夹时报错:Unable to load native-hadooplibrary for your platform... using builtin-java classes where applicable
解决方法:下载对应的native-hadoop 64位的包,解压到hadoop安装目录下的lib和lib/native下,配置环境变量,并令其生效即可。
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
运行 Hadoop 程序时,为了防止覆盖结果,程序指定的输出目录(如output)不能存在,否则会 示错误,因此运行前需要先删除输出目录。在实际开发应用程序时,可考虑在程序中加上如下代码,能在每次运行时自动删除输出目录,避免繁琐的命令行操作
Configuration conf = new Configuration(); Job job = new Job(cont);
/* 删除输出目录 */
Path outputPath = new Path(args[1]); outputPath.getFileSystem(conf).delete(outputPath, true);./sbin/start-dfs.sh启动hadoop时,报以下错误'/usr/local/hadoop/logs':Operation not permitted 解决方式:检查/usr/local/hadoop/logs宿主为root用户,原因:chown -Rhadoop:hadoop hadoop/ 最后没加”/" 。 root用户修改/usr/local/hadoop/logs宿主为hadoop用户(chown -R hadoop hadoop/)即可。

10. 运行示例时,一直停留在如下界面,程序运行阻塞。
解决方法:增加虚拟机内存(从1G—>2G:OK) 即可。
九. 总结
学习入手各门语言或者框架,搭建环境是个基本的过程,也是学习的第一步。搭建环境过程中可能遇到各种问题,如:版本匹配问题,权限问题,莫名其妙的报错甚至连报错也没有的奇葩问题等等。
好的安装指导或资料能给我们带来很多方便。如果安装过程中遇到上诉各种问题,对于不同的问题,解决方式也不同。版本匹配问题,下载对应的版本重新安装即可。建议到官网下载版本,版本比较权威,后续搭建环境过程中因为版本出问题的可能性较小,省去一些不必要的麻烦。有报错的问题,根据报错信息耐心检查或者网上搜索资料,跟同学们一起讨论,这类问题往往都可以找到解决方法。对于一些莫名其妙的问题,如果没有具体报错信息,把问题现象 述清楚,到各大论坛(个人习惯:百度,CSDN,stackoverflow等)去找类似问题,耐心找找,也可以找到一些线索,或者供一些idea给我们。搭建环境如此,后续学习也是如此。