root权限密码:本机<15 Ubuntu的密码是:204
Spark的分布环境需要基于HDFS,所以在装spark之前我们需要先配置hadoop分布式系统:
1.实验做啥:
基本:配置完成hadoop环境
延伸:配置完成spark环境(实验二的部分内容)
Hadoop 集群的安装配置大致为如下流程:
1.选定一台机器作为 Master
2.在 Master 节点上配置 hadoop 用户、安装 SSH server、安装 Java 环境
3.在 Master 节点上安装 Hadoop,并完成配置
4.在其他 Slave 节点上配置 hadoop 用户、安装 SSH server、安装 Java 环境
5.将 Master 节点上的 /usr/local/hadoop 目录复制到其他 Slave 节点上
6.在 Master 节点上开启 Hadoop
步骤一:网络部分:
1.确认团队各自机子master和slave的身份分工,收集各自IP填入下表:如:
身份 Ip地址
master 192.1.1.1
slave1 192.1.1.2
slave2 192.1.1.3
查看ip的命令是:ifconfig

这里ip地址看inet addr就是:192.168.245.130,
2.网络正常确认:组间的成员看一下网络是否连通,测试命令用ping master的ip,如:

出现时间time = **(这里是27.2)说明网络正常开始下一步
3.为了方便后期操作,修改下/etc/hosts 中的IP地址映射(DNS):
Slave1的ip地址为192.168.123.131
那么我在master中用sudo gedit /etc/hosts 文件加入 192.168.123.131变成
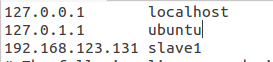
那么本来需要ping 192.168.123.131的现在只需要ping slave1就可以了

mastet和slave操作相同,都是在hosts文件中加入:
master的ip master
Slave1 的ip slave1
Slave2 的ip slave2
然后直接利用名字在进行看下是否可以ping 通。
网络配置完成,开始执行下一步。(注后面命令中master和slave1,slave2.都是对相应ip地址的映射)
步骤二:创建hadoop用户和用户组:
1.创建一个名为hadoop的用户组
$ sudo addgroup hadoop
2.创建一个名为hadoop的用户,归到hadoop用户组下
$ sudo adduser --ingroup hadoop hadoop
(注:前一个hadoop为用户组名,后面的是用户名,之所以名字一样是为了方便统一管理)
结果会类似如下图:

注:为方便密码可以统一为:123456,执行后会有一些信息需要填写,可以不填,都敲回车,用系统默认的即可)
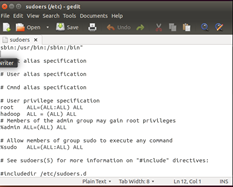
3.修改sudoers文件,为了让hadoop组拥有使用sudo的能力:
利用命令:$ sudo gedit /etc/sudoers 打开编辑器
然后用在 root ALL=(ALL) ALL 下面添加如下一行hadoop ALL=(ALL) ALL,如下图,然后保存关闭
4.切换到hadoop用户,使用命令:
$ su hadoop 然后输入刚才设置的密码,进行切换
切换成功标记为:

@字符前面变成相关的用户名,即hadoop
5.切换到hadoop用户之后,进行修改主机的名字:
其中@前面hadoop是用户的名字,后面的字符就是主机名,修改一方面是为了后期好分辨,另一方面是hadoop就是利用主机名来查找网络的ip映射的。
使用命令:sudo gedit /etc/hostname
将原来的名字删除写上你们的名字,例如这里是slave1,保存然后重启
使用命令:sudo reboot
重新登入注意@后面的名称应该和你写入的名字一样。:

步骤三:安装SSH协议,使得master和slave之间可以无密钥登入:
1.安装ssh,用命令$ sudo apt-get install ssh
2.配置无密码传输
1)master和slave都要生成你自己的私钥和公钥(你想无密码登入哪一个,你就将生成的 密钥考给它)
用命令:$ ssh-keygen -t rsa
2)进入当前用户的.ssh 目录:
用命令:cd /home/hadoop/.ssh
然后ls会看到id_rsa 和 id_rsa.pub 文件
3)master复制id_rsa.pub 文件(公钥)
用命令:cp id_rsa.pub authorized_keys
4)master收集所有slave的的密钥拷到 authorized_keys 里面,
4.1:先拷贝文件,用命令:
$scp slave1:/home/hadoop/.ssh/id_rsa ./slave1_rsa
(这个命令的意思是:从slave1的/home/hadoop/.ssh/下面拷贝文件id_rsa 到当前目录下并改其名字为slave1_rsa,同理在从slave2,slave3拷贝id_rsa文件)
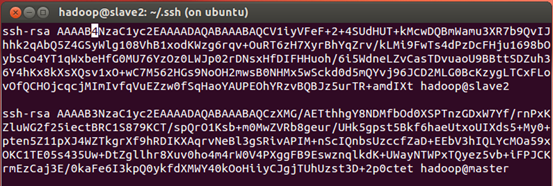
4.2:复制各个slave*_rsa里面的内容到authorized_keys里面,用命令:
$cat slave1_rsa slave2_rsa (加入你要拷贝内容的文件名)>> authorized_keys

最后结果如图:
5)拷贝后将authorized_keys文件发给所有的slave ,放其/home/hadoop/.ssh的文件夹下
$ cd /home/hadoop/.ssh
$ scp authorized_keys slave1:/home/hadoop/.ssh/ (复制密钥文档)
$ scp authorized_keys slave2:/home/hadoop/.ssh/
6)所有slave和master都进行测试ssh是否需要密码
用ssh hadoop@master 测试一下。
第一次可能还需要密码,第二次如果不需要密码登入就可以了。如果还不行,则修改authorized_keys 的权限为644,sudo chmod 644 authorized_keys
原理:Master(NameNode | JobTracker)作为客户端,要实现无密码公钥认证,连接到服务器Salve(DataNode | Tasktracker)上时,需要在Master上生成一个密钥对,包括一个公钥和一个私钥,而后将公钥复制到所有的Slave上。当Master通过SSH连接Salve时,Salve就会生成一个随机数并用Master的公钥对随机数进行加密,并发送给Master。Master收到加密数之后再用私钥解密,并将解密数回传给Slave,Slave确认解密数无误之后就允许Master进行连接了。这就是一个公钥认证过程,其间不需要用户手工输入密码。重要过程的一种是实现方式是将客户端Master的公钥复制到Slave的authorized_keys上,将slave的公钥复制到master上的authorized_keys上。
注意:第一次还是需要登入密码的,遇到问题看附录。
步骤四:安装JDK(java):
1使用apt-get install安装,如下:
(旧版ubuntu使用) sudo apt-get install openjdk-7-jre openjdk-7-jdk
(新版ubuntu使用) sudo apt-get install openjdk-8-jre openjdk-8-jdk
2.修改环境变量:
gedit ~/.bashrc # 设置JAVA_HOME

如果是旧版ubuntu在文件最前面添加如下单独一行:
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64 (旧版)
如果是新版则看下你的/usr/lib/jvm下的java文件夹的名称做相应的修改。
然后 export JAVA_HOME=/usr/lib/jvm/java文件夹的名称
注意:由于我测试的机子是旧版,所以下面路径我是以旧版为例,类似出现这个路径新版都需相应更改
3.使 JAVA_HOME 变量生效:
source ~/.bashrc # 使变量设置生效
4.验证java是否安装成功,使用命令:
$java -version 如果出现

就算安装成功。
步骤五(master先做,然后拷贝给所有slaves):安装Hadoop:
1.去官网下载hadoop安装包,这里由U盘拷贝。
2.先将hadoop的压缩文件拷贝到/usr/local/,用命令
mv hadoop-2.6.5.tar.gz /usr/local/
3.用命令解压:
sudo tar -zxvf hadoop-2.6.5 ./
4.为了和下面打印的配置文件相同,将解压完的hadoop-2.6.5的文件名变为hadoop
sudo mv hadoop-2.6.5 hadoop
5.修改hadoop文件夹的权限,将其可读写权限增加给hadoop组
sudo chown -R hadoop:hadoop /usr/local/hadoop
接下来开始修改hadoop的配置文件,利用gedit命令这里就不在赘述:
集群/分布式模式需要修改 /usr/local/hadoop/etc/hadoop 中的5个配置文件,更多设置项可点击查看官方说明,这里仅设置了正常启动所必须的设置项: slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
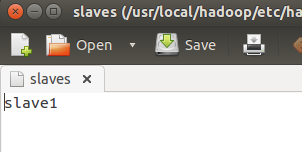
1)文件 slaves,将作为 DataNode 的主机名写入该文件,每行一个,默认为 localhost,所以在伪分布式配置时,节点即作为 NameNode 也作为 DataNode。分布式配置可以保留 localhost,也可以删掉,让 Master 节点仅作为 NameNode 使用。
使用命令 gedit /usr/local/hadoop/etc/hadoop/slaves
然后删除掉localhost加入你的各个slave的名字,我下面就只有slave1,你们应该是到slave6左右。
2)文件 core-site.xml 改为下面的配置:
fs.defaultFS
hdfs://Master:9000
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
Abase for other temporary directories.
-
文件 hdfs-site.xml,dfs.replication 一般设为 3
dfs.namenode.secondary.http-address
Master:50090
dfs.replication
3
dfs.namenode.name.dir
file:/usr/local/hadoop/tmp/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop/tmp/dfs/data
-
文件 mapred-site.xml (可能需要先重命名,使用cp mapred-site.xml.template mapred-site.xml),
然后配置修改如下:
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
Master:10020
mapreduce.jobhistory.webapp.address
Master:19888
-
文件 yarn-site.xml:
yarn.resourcemanager.hostname
Master
yarn.nodemanager.aux-services
mapreduce_shuffle
配置完5个文件之后,Master需要将你配置好的整个hadoop文件夹拷贝给各个slave,如下命令顺序执行:
cd /usr/local
sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件
sudo rm -r ./hadoop/logs/* # 删除日志文件
tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
cd ~
scp ./hadoop.master.tar.gz slave1:/home/hadoop #注意这一步master要多次执行, 并将slave1 做相应的修改
Master 传输完后,各个slave执行如下命令:
sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)
sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
sudo chown -R hadoop /usr/local/hadoop
到这里所有的master和slaves配置完了hadoop的相关设置。那么验证是否成功(这一步只需master来完成启动):
0)cd /usr/local/hadoop/#进入到相应的hadoop启动脚本目录
1)首次启动需要先在 Master 节点执行 NameNode 的格式化,用命令:
bin/hdfs namenode -format # 首次运行需要执行初始化,之后不需要
2)依次执行下面启动命令
sbin/start-dfs.sh
sbin/start-yarn.sh
sbin/mr-jobhistory-daemon.sh start historyserver
利用jps命令查看,正确的话,在 Master 节点上可以看到 NameNode、ResourceManager、SecondrryNameNode、JobHistoryServer 进程,如下图所示:
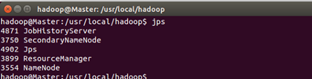
在 Slave 节点可以看到 DataNode 和 NodeManager 进程,如下图所示:

参考网址:http://www.powerxing.com/install-hadoop-cluster/
(注:到这里就配置完hadoop了。如果有时间可以将下一次的试验spark也进行配置,对于已经配置完hadoop来说,spark配置相对比较简单)
Spark 集群的安装配置大致为如下流程:
我们配置的环境如下:jdk1.7+hadoop2.6.5+scala2.11.8+spark1.6.1
Master 修改完spark配置文件,在传给slaves。
http://blog.csdn.net/qq_28945021/article/details/51549116
Master做(除了第七步):
1.在/usr/local/ 下面创建一个文件夹 spark,并修改其权限:
sudo mkdir /usr/local/spark
sudo chown -R hadoop /usr/local/spark
2.将压缩文件scala-2.11.8.tgz 和spark-1.6.1-bin-hadoop2.6.tgz 拷贝到/usr/local/spark/下,并解压
sudo tar -zxvf scala-2.11.8.tgz
sudo tar -zxvf spark-1.6.1-bin-hadoop2.6.tgz
3.修改环境配置文件:
sudo gedit /etc/profile
在里面添加:
export SCALA_HOME=/usr/local/spark/scala-2.11.8
export PATH=
PATH
export SPARK_HOME=/usr/local/spark/spark-1.6.1-bin-hadoop2.6
export PATH=
PATH
保存退出
4.马上执行更新配置文件:source /etc/profile
5.修改在/usr/local/spark/spark-1.6.1-bin-hadoop2.6/conf/下面的配置文件spark-env.sh
cd /usr/local/spark/spark-1.6.1-bin-hadoop2.6/conf/
cp spark-env.sh.template spark-env.sh
sudo gedit spark-env.sh
加入如下内容:
export SCALA_HOME=/usr/local/spark/scala-2.11.8
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export SPARK_MASTER_IP=master
export SPARK_WORKER_MEMORY=512m
export master=spark://master:7070
6.修改/usr/local/spark/spark-1.6.1-bin-hadoop2.6/conf/下面的配置文件slaves
cp slaves.template slaves
sudo gedit slaves
将里面的内容改为slave1,slave2…每个一行,如:
保存退出
7.(这一步slave做):slaves在相同的目录即/usr/local/下创建spark文件夹并修改权限:
sudo mkdir /usr/local/spark
sudo chown -R hadoop /usr/local/spark
8.(这一步又转为master做):master将配置好的spark文件传输给各个slaves(执行多次):
scp -r /usr/local/spark/spark-1.6.1-bin-hadoop2.6 hadoop@slave1:/usr/local/spark/
9.进入到spark目录下面,执行spark:
cd /usr/local/spark/spark-1.6.1-bin-hadoop2.6/
sbin/star-all.sh
如果成功,则在master处使用jps会出现Master进程:

在slave机子上使用jps会出现worker:

到这里配置环境告一段落