论文简述
本文通过利用多尺度卷积,在特征维度上采用密集子矩阵来构建稀疏表示,并使用1×1的结构降维,从而在计算需求适度增加的情况下,质量显著提高。
论文要点
当前问题
最为直观的提升CNN网络性能的方式,便是增加它的尺寸,包括深度(网络层数)和宽度(每层的单元数),然而大尺寸网络意味着:
- 大量的参数,使网络更容易过拟合(dropout在一定程度上解决这个问题)
- 激增的计算资源使用量,如果增加的资源消耗没有有效利用,那么这些资源便浪费掉了。
解决方法
引入稀疏性并将全连接层,甚至是卷积层,替换成稀疏型。
- 实际中,稀疏矩阵需要更复杂的工程和计算基础设施
- 当前机器学习系统仅通过卷积来利用空间维度上的稀疏性(局部感受野,相关性强的部分,且共享参数大大降低计算量)
理论一:如果数据集的概率分布可以通过一个大型稀疏的深度神经网络表示,则最优的网络拓扑结构可以通过分析前一层激活的相关性统计和聚类高度相关的神经元来一层层的构建
理论二: Hebbian principle(neurons that fire together, wire together )
如果两个神经元常常同时产生动作电位,或者说同时激动(fire),这两个神经元之间的连接就会变强,反之则变弱。
–>将相关性强的特征聚集在一起。
如果将稀疏矩阵聚类为相对密集的子矩阵,则会有更佳的性能。原理及论文理解参考:https://blog.csdn.net/docrazy5351/article/details/78993269
因此,Inception结构提出的主要思想是考虑怎样近似卷积视觉网络的最优稀疏结构并用容易获得的密集组件进行覆盖。—特征维度上的稀疏连接
Inception结构:
- 多尺度卷积
各个尺度的卷积可看为稀疏分布的特征集(并不是图像的所有元素都会在该尺度上存在意义或者激活)会产生很多冗余信息,因此inception在多个尺度上提取特征(1×1,3×3,5×5),输出的特征就不再是均匀分布,而是相关性强的聚集在一起,这可以理解成多个密集分布的子特征集。 - 1×1卷积核
作用一:降维
在3×3和5×5卷积核前,先将维度降低,从而减少计算量。
作用二:增强非线性

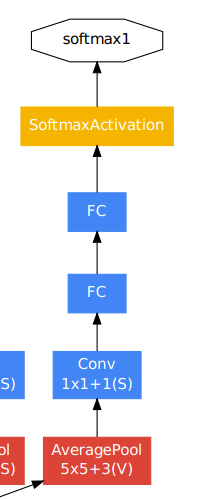
每层输出的通道数等于4个分支通道数的总和,且max pooling的stride均为1,不改变特征图的大小。最终生成的网络便是多个Inception的叠加。且最终结构中在分类器前使用了average pooling。
额外分类器:用来克服梯度消失问题以及提供正则项,这些loss在以0.3的权重加入到整体的loss中。
思考
- 稀疏矩阵表达形式以及利用密集子矩阵的方式很具有参考性
- 从这几篇论文可以看出,在实际训练过程,数据扩增(包括尺寸,平移,裁剪尺寸,光度畸变,色彩比例等等),还有模型融合都十分有效。
小吐槽
可能是因为论文涉及的很多数学概念都一知半解的,总觉得这篇论文读起来很吃力,就给我一种抓不到重点的感觉。
有部分待理解的内容需要等看完检测部分的基本知识才能理解。