背景
分布式系统环境下,服务之间的依赖调动非常常见,一个业务调用通常依赖多个基础服务,如果调用某服务层,而这个服务层不可用或者因为网络等原因响应时间超出预期,请求线程被堵塞,当有大量的请求调用这个服务就会导致这个服务的资源被耗尽,无法继续对外提供服务,这也叫雪崩效应;
雪崩效应经常出现在,服务器宕机,光纤被挖断(如腾讯:https://baijiahao.baidu.com/s?id=1628812006479290058&wfr=spider&for=pc),异常流量,缓存穿透,JVM长时间FullGC,同步等待;
出现了雪崩效应,服务一个一个出问题,为了构建一个稳定可靠的分布式系统,我们的系统应该具备自我保护能力,避免雪崩效应;
服务短路(CircuitBreaker)
QPS (Query per second 每秒查询率)
QPS: 经过全链路压测,计算单机极限QPS,集群 QPS = 单机 QPS * 集群机器数量 * 可靠性比率;
全链路压测 除了压 极限QPS,还有错误数量;
全链路:一个完整的业务流程操作;
Hystrix
本文猪角Hystrix就是解决同步等待导致的雪崩问题;
对来自依赖的延迟和故障进行防护控制,一般都是通过网络调用导致的;
快速失败并迅速恢复;
停止分布式系统中的级联故障;
回退并优雅的降级;
https://github.com/Netflix/Hystrix/wiki#what-is-hystrix-for
Hystrix解决的问题
分布式系统中,各个系统错综复杂,一个系统依赖多个服务,一个服务出现问题,可能导致整个系统瘫痪;
官方文档写了,一个应用依赖30个微服务,并且他们可用率高达99.99%,得到以下结论:
99.99的30次方 = 99.7% 正常运行时间
如果有10亿次请求则有3,000,000次的失败请求
即使所依赖的30个服务都表现很棒,每个月还是有2小时的停机时间
https://github.com/Netflix/Hystrix/wiki#what-problem-does-hystrix-solve
原理图如下:
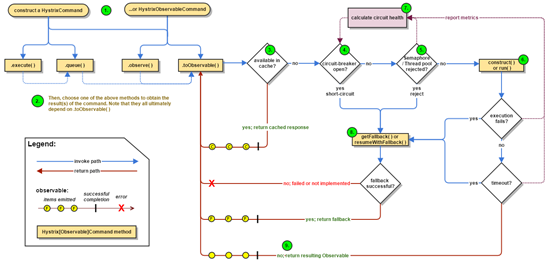
- 构建一个HystrixCommand或HystrixObservableCommand对象;前者逻辑在run()中,后者逻辑在construct()
- 执行命令
.execute():同步阻塞方式执行run()(HystrixObservableCommand无此方法)
.queue():异步非阻塞方式执行run()(HystrixObservableCommand无此方法)
.observe():事件注册前调用,run()/construct(),继承HystrixCommand,hystrix创建新线程非堵塞的执行run(),后者堵塞执行construct();注册成功则执行onNext()和onCompleted,失败则执行onError();
.toObservable():事件注册后调用,run()/construct();
这四个方法用来触run()/construct(),一个实例也只能执行一次,并且他们都会走toObservable()
- 判断缓存
- 是否熔断
- 信号量/线程池是否满了
- 执行run()/construct();
- Fallback(降级)
其他不做过多介绍,如有兴趣参考https://github.com/Netflix/Hystrix/wiki/How-it-Works详细工作原理
spring-cloud-hystrix-client-demo
start.spring.io引入actuator,web,hystrix
主程序入口添加,