【
前言:以前搭了个简单的ELK日志系统,以我个人的感觉来说,ELK日志系统还是非常好用的。以前没有弄这个ELK日志系统的时候,线上的项目出了bug,报错了,要定位错误是什么,错误出现在哪个java代码文件里,每次都要在服务器上使用linux命令打开日志文件查看错误,简直繁琐无比。
搭了这个ELK日志系统之后,项目中的所有日志打印都发送到了ELK里面,然后通过ELK中的kibana视图界面 搜索 或 查看 各个时间段的日志,以及什么级别的日志,巨方便。
当然上次搭建的ELK日志系统只是个简单的,今天打算把消息中间件kafka整合到ELK日志系统里。
》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》
目前还是借鉴这位老哥的博客,搭建一个高并发场景的ELK日志系统:https://blog.csdn.net/qq_22211217/article/details/80764568,最后搭建高并发ELK日志系统流程图如下:


】
1、先说说整个ELK日志系统的流程

2、开始搭建ELK日志系统
2.1、准备工作:
先准备3台机器:我的分别如下:
192.168.2.115
192.168.2.116
192.168.2.119
- 3台机器上都要配置jdk环境,因为elasticsearch是java开发的
- 3台机器上也全要安装elasticsearch,因为现在要搭建elasticsearch分布式集群,所以3台机器都要装
- 我用192.168.2.119作es的主节点,192.168.2.115、192.168.2.116作为数据节点
- 在主节点上安装kibana,192.168.2.115上安装logstash
ELK使用的版本:elk所有安装包都在官网下载到
3、ELK日志系统第一步:安装elasticsearch
3.1、目前我把elasticsearch-6.4.2.tar.gz安装包都放在三台机器的/usr/local/dev/es目录下,并解压

3.2、开始配置elasticsearch集群
3.2.1、配置192.168.2.119主节点上的elasticsearch配置文件
#打开elasticsearch的配置文件
vi elasticsearch-6.4.2/config/elasticsearch.yml
配置内容如下:
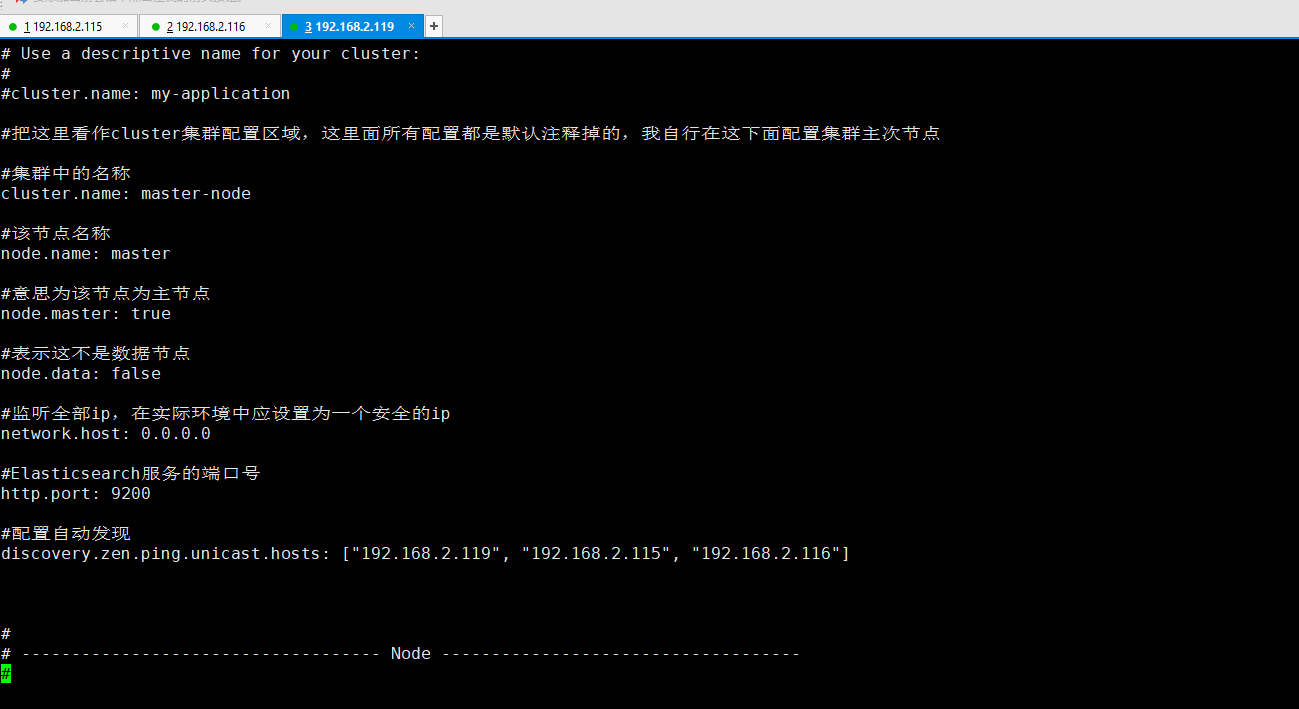
#集群中的名称 cluster.name: master-node #该节点名称 node.name: master #意思为该节点为主节点 node.master: true #表示这不是数据节点 node.data: false #监听全部ip,在实际环境中应设置为一个安全的ip network.host: 0.0.0.0 #Elasticsearch服务的端口号 http.port: 9200 #配置自动发现 discovery.zen.ping.unicast.hosts: ["192.168.2.119", "192.168.2.115", "192.168.2.116"]
192.168.2.119服务器主节点上的elasticsearch配置文件效果图:
3.2.2、配置192.168.2.115节点上的elasticsearch配置内容:
#该节点名称
node.name: data-node1
#意思为该节点为主节点
node.master: false
#表示这不是数据节点
node.data: true
3.2、3台服务器的elasticsearch都配置好了,现在来启动一下主节点192.168.2.119上的elasticsearch:
#启动命令
./elasticsearch-6.4.2/bin/elasticsearch
啊哦,启动报错!!!!!!!!!!!!
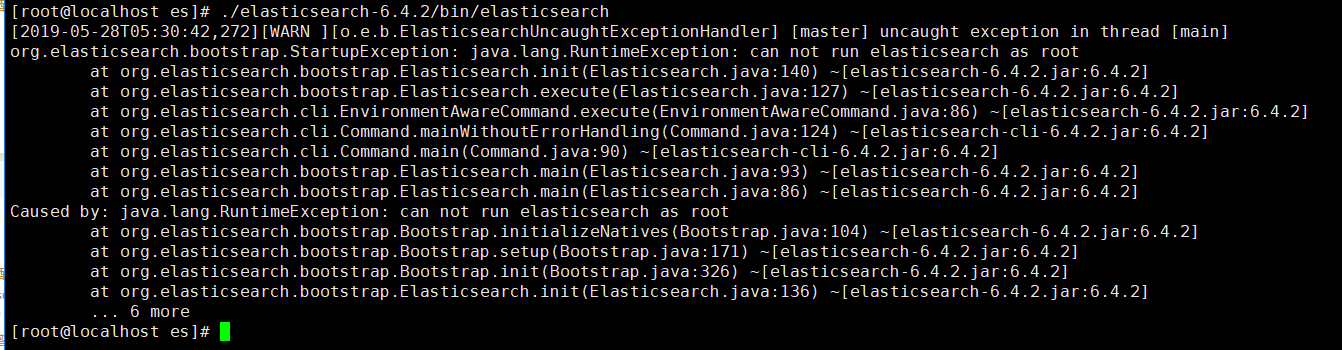
报错的原因:就是必须要再创建一个用户去操作elasticsearch,不能直接用root用户操作。
下班,明天断续。。。。
放牛咯!