
我们就识别上面的汉字。
安装软件tesseract和python库
https://www.cnblogs.com/sea-stream/p/10961580.html
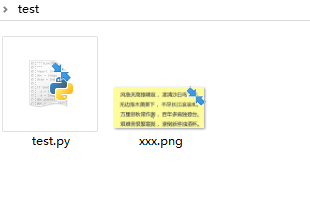
然后新建一个文件夹test,把上面那张图片放在文件夹里面,再新建一个test文件
写入如下内容
#coding=utf-8 from PIL import Image import pytesseract #上面都是导包,只需要下面这一行就能实现图片文字识别 text=pytesseract.image_to_string(Image.open('xxx.png'),lang='chi_sim') print(text)
目录如下:
运行可能会出现错误:
C:\Users\k\Desktop\test>python test.py Traceback (most recent call last): File "test.py", line 5, in <module> text=pytesseract.image_to_string(Image.open('xxx.png'),lang='chi_sim') File "C:\Users\k\Anaconda3\lib\site-packages\pytesseract\pytesseract.py", line 309, in image_to_string }[output_type]() File "C:\Users\k\Anaconda3\lib\site-packages\pytesseract\pytesseract.py", line 308, in <lambda> Output.STRING: lambda: run_and_get_output(*args), File "C:\Users\k\Anaconda3\lib\site-packages\pytesseract\pytesseract.py", line 218, in run_and_get_output run_tesseract(**kwargs) File "C:\Users\k\Anaconda3\lib\site-packages\pytesseract\pytesseract.py", line 194, in run_tesseract raise TesseractError(status_code, get_errors(error_string)) pytesseract.pytesseract.TesseractError: (1, 'Error opening data file C:\\Program Files (x86)\\Tesseract-OCR/tessdata/chi_sim.traineddata Please make sure the TESSDATA_PREFIX environment variable is set to the parent directory of your "tessdata" directory. Failed loading language \'chi_sim\' Tesseract couldn\'t load any languages! Could not initialize tesseract.')
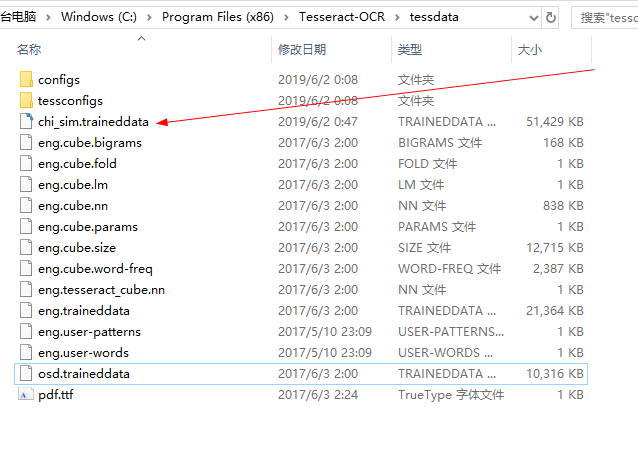
因为tesseract-ocr默认不支持中文识别。 将下载到的文件:chi_sim.traineddata 放到Tesseract-OCR安装目录 D:\Program Files (x86)\Tesseract-OCR\tessdata 下
链接:https://pan.baidu.com/s/1c-fveIYnm1sQHxX9WRpUZw
提取码:9ovq
再次运行
python test.py
下面是输出结果
C:\Users\k\Desktop\test>python test.py
风急天高猿啸衷′ 渚麦冒麦少丑弓飞口。
u边洛木萧萧下′ 不〖长江滚滚来。
万 悲禾火常作畜′ 年多病独登台。
艰难苦恨萦霜 渣倒新停澍酉木不=
参考: