企业运维的数据库最常见的是 mysql;但是 mysql 有个缺陷:当数据量达到千万条的时候,mysql 的相关操作会变的非常迟缓; 如果这个时候有需求需要实时展示数据;对于 mysql 来说是一种灾难;而且对于 mysql 来说,同一时间还要给多个开发人员和用户操作; 所以经过调研,将 mysql 数据实时同步到 hbase 中;
最开始使用的架构方案:
Mysql---logstash—kafka---sparkStreaming---hbase---web
Mysql—sqoop---hbase---web
但是无论使用 logsatsh 还是使用 kafka,都避免不了一个尴尬的问题: 他们在导数据过程中需要去 mysql 中做查询操作:
比如 logstash:
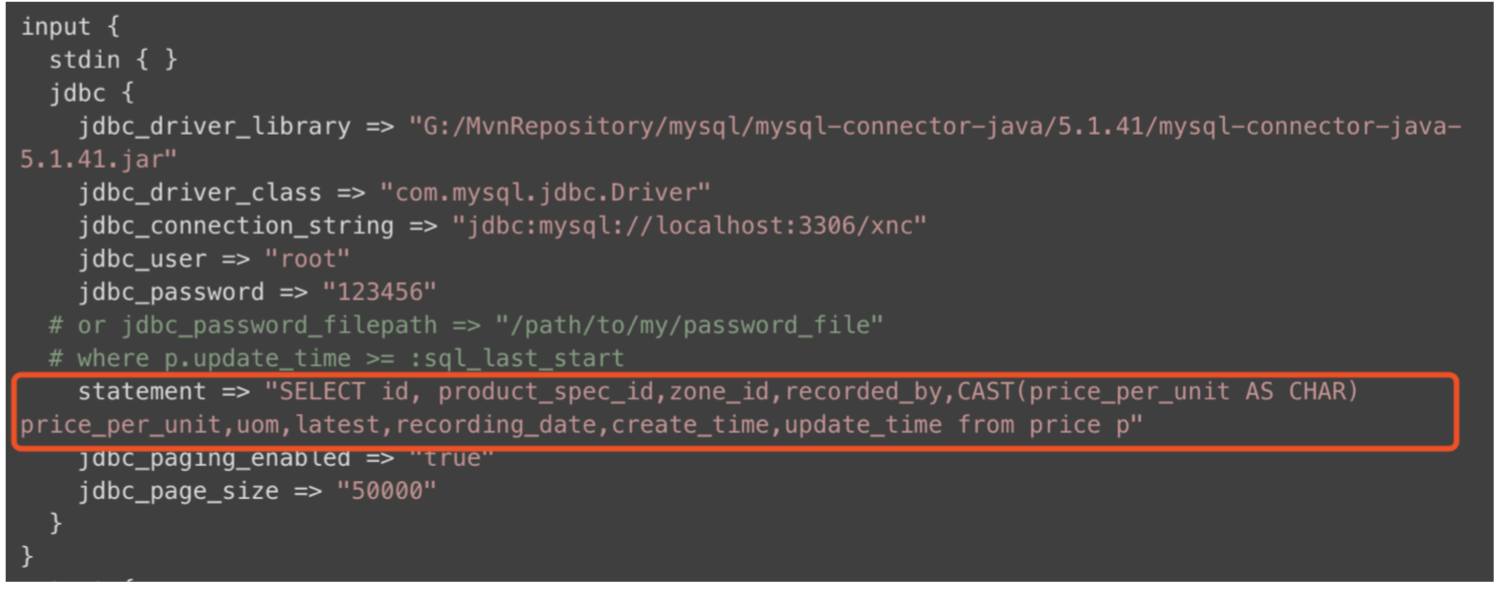
比如 sqoop:

不可避免的,都需要去 sql 中查询出相关数据,然后才能进行同步;这样对于 mysql 来说本身就是增加负荷操作; 所以我们真正需要考虑的问题是:有没有什么方法,能将 mysql 数据实时同步到 hbase;但是不增加 mysql 的负担; 答案是有的:可以使用 canal 或者 maxwell 来解析 mysql 的 binlog 日志
那么之前的架构就需要改动了:
Mysql---canal—kafka—flink—hbase—web
第一步:开启 mysql 的 binlog 日志
Mysql 的 binlog 日志作用是用来记录 mysql 内部增删等对 mysql 数据库有更新的内容的 记录(对数据库的改动),对数据库的查询 select 或 show 等不会被 binlog 日志记录;主 要用于数据库的主从复制以及增量恢复。
mysql 的 binlog 日志必须打开 log-bin 功能才能生存 binlog 日志
-rw-rw---- 1 mysql mysql 669 5 月 10 21:29 mysql-bin.000001
-rw-rw---- 1 mysql mysql 126 5 月 10 22:06 mysql-bin.000002
-rw-rw---- 1 mysql mysql 11799 5 月 15 18:17 mysql-bin.000003
(1):修改/etc/my.cnf,在里面添加如下内容
log-bin=/var/lib/mysql/mysql-bin 【binlog 日志存放路径】 binlog-format=ROW 【⽇日志中会记录成每⼀一⾏行行数据被修改的形式】 server_id=1 【指定当前机器的服务 ID(如果是集群,不能重复)】
(2):配置完毕之后,登录 mysql,输入如下命令:
show variables like ‘%log_bin%’

出现如下形式,代表 binlog 开启;
第二步:安装 canal
Canal 介绍 canal 是阿里巴巴旗下的一款开源项目,纯 Java 开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了 MySQL(也支持 mariaDB)。
起源:早期,阿里巴巴 B2B 公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求。不过早期的数据库同步业务,主要是基于 trigger 的方式获取增量变更,不过从 2010 年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅 &消费的业务,从此开启了一段新纪元。
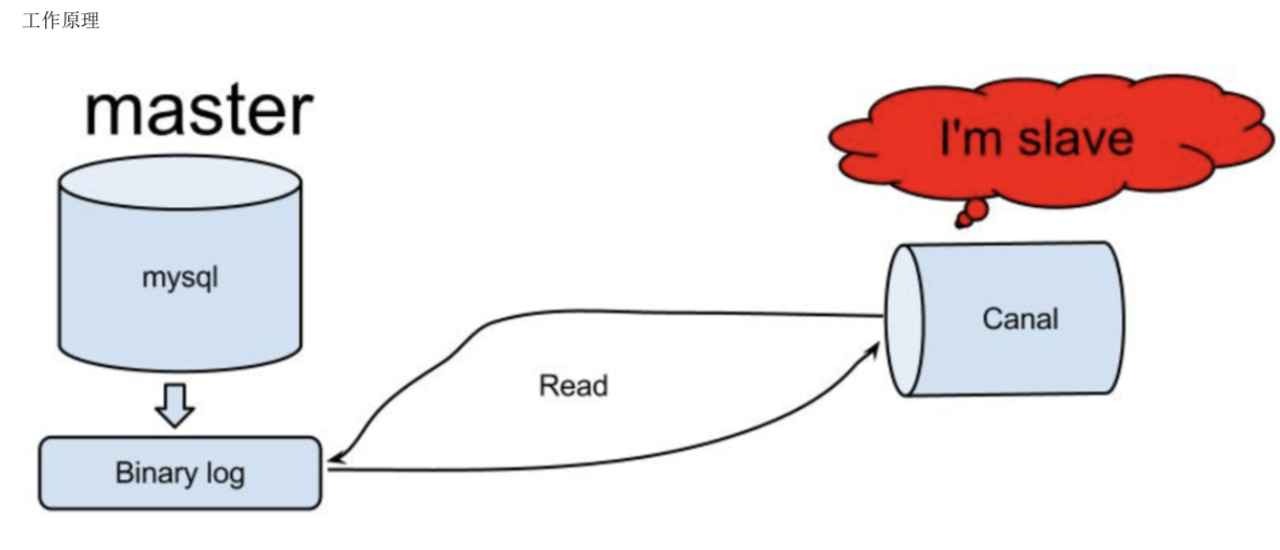
原理相对比较简单:
1、canal 模拟 mysql slave 的交互协议,伪装自己为 mysql slave,向 mysql master 发送 dump 协议
2、mysql master 收到 dump 请求,开始推送 binary log 给 slave(也就是 canal) 3、canal 解析 binary log 对象(原始为 byte 流)
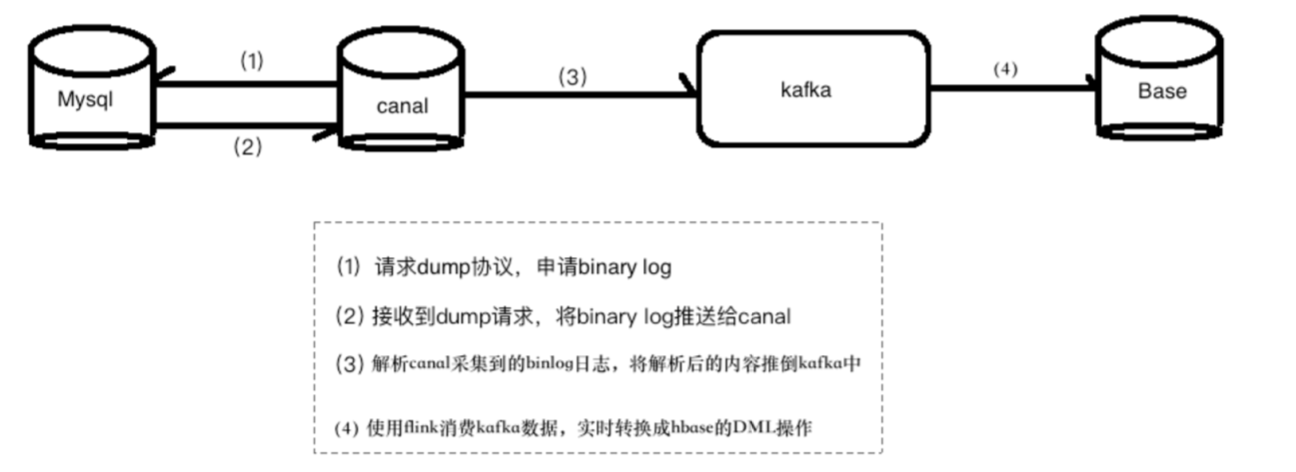
使用 canal 解析 binlog,数据落地到 kafka
(1):解压安装包:canal.deployer-1.0.23.tar.gz
tar -zxvf canal.deployer-1.0.23.tar.gz -C /export/servers/canal 修改配置文件:
vim /export/servers/canal/conf/example/instance.properties

(2):编写 canal 代码
仅仅安装了 canal 是不够的;canal 从架构的意义上来说相当于 mysql 的“从库”,此时还并不能将 binlog 解析出来实时转发到 kafka 上,因此需 要进一步开发 canal 代码;
Canal 已经帮我们提供了示例代码,只需要根据需求稍微更改即可;
Canal 提供的代码:
上面的代码中可以解析出 binlog 日志,但是没有将数据落地到 kafka 的代码逻辑,所以我们还需要添加将数据落地 kafka 的代码; Maven 导入依赖:

<groupId>com.alibaba.otter</groupId> <artifactId>canal.client</artifactId> <version>1.0.23</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka --> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.11</artifactId> <version>0.9.0.1</version> </dependency>
测试 canal 代码
1、 启动 kafka 并创建 topic
/export/servers/kafka/bin/kafka-server-start.sh /export/servers/kafka/config/server.properties >/dev/null 2>&1 & /export/servers/kafka/bin/kafka-topics.sh --create --zookeeper hadoop01:2181 --replication-factor 1 --partitions 1 --topic mycanal
2、 启动 mysql 的消费者客户端,观察 canal 是否解析 binlog
/export/servers/kafka/bin/kafka-console-consumer.sh --zookeeper hadoop01:2181 --from-beginning --topic mycanal 2、启动 mysql:service mysqld start
3、启动 canal:canal/bin/startup.sh
4、进入 mysql:mysql -u 用户 -p 密码;然后进行增删改
使用 flink 将 kafka 中的数据解析成 Hbase 的 DML 操作
 View Code
View Code
View Code
View Code
打包scala程序
将上述的maven依赖红色标记处修改成:
<**sourceDirectory**>**src/main/scala**</**sourceDirectory**> <**mainClass**>scala的驱动类</**mainClass**>
运行canal代码
View Code
运行flink代码
/opt/cdh/flink-1.5.0/bin/flink run -m yarn-cluster -yn 2 -p 1 /home/elasticsearch/flinkjar/SynDB-1.0-SNAPSHOT.jar