1.前期知识储备
在线数据迁移,是指将正在提供线上服务的数据,从一个地方迁移到另一个地方,整个迁移过程中要求不停机,服务不受影响。根据数据所处层次,可以分为cache迁移和存储迁移;根据数据迁移前后的变化,又可以分为平移和转移。
平移是指迁移前后数据组织形式不变。比如Mysql从1个实例扩展为4个实例,Redis从4个端口扩展到16个端口,HBase从20台机器扩展到30台机器等等。如果在最初的设计里就为以后的扩容缩容提供了方便,那么数据迁移工作就会简单很多,比如Mysql已经做了分库分表,扩展实例的时候,只需要多做几个从库,切换访问,最后将多余的库表删除即可。更进一步,在实现上已经做到全自动数据迁移,如 HBase,就更简单了:添加机器,手工修改配置或者系统自动发现,然后等待系统完成迁移。
转移是指数据迁移前后,数据组织形式发生了变化。多年前,某社交平台曾经为ID升级做过一次数据迁移,将ID由最初的自增算法修改为巧妙设计的UUID算法,这次迁移最大的挑战是要修改数据的主键,主键本来是数据的唯一标识,它发生变化,也就意味着原来的数据不复存在,新的数据凭空产生,对于整个系统中所有业务流程、周边配套、上下游部门都会产生巨大的兼容性挑战。不过大部分数据迁移项目都不会修改主键,甚至不会修改数据本身,改变的只是数据的组织形式。 比如某社交平台计数器原本为了节约存储空间,使用redis hash进行存储,后来为了提升批量查询的性能,迁移成 KV 形式;又比如某社交平台的转发列表和粉丝列表,最初都使用Mysql存储,后来为了更好的扩展性和成本,都迁移到HBase存储。
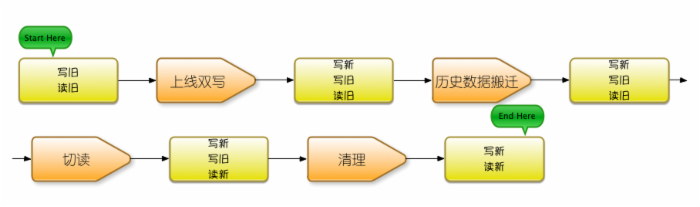
2.数据迁移步骤
- 上线双写,将数据同时写入新/旧两个系统。
- 历史数据离线搬迁,将历史存量数据从旧系统搬到新系统。
- 切读,即将读请求路由到新系统。
- 清理沉淀,包括清理旧的数据,回收资源,及清理旧的代码逻辑,旧的配套系统等等,将迁移过程中的经验教训进行总结沉淀,将过程中开发或使用的工具进行通用化改造,以备下次使用。
注意:某些情况下,步骤一和步骤二也可能倒过来,先做历史数据搬迁,然后再写入新数据,这时候就需要谨慎地处理搬迁这段时间里产生的新数据,一般使用queue缓存写入的方式,称为“追数据”。
转自:https://blog.csdn.net/zlfprogram/article/details/80735933