文本处理三剑客
在 Shell 下使用这些正则表达式处理文本最多的命令有下面几个工具:
| 命令 | 描述 |
| grep | 默认不支持扩展表达式,加-E 选项开启 ERE。如果不加-E 使用花括号要加转义符\{\} |
| egrep | 支持基础和扩展表达式 |
| awk | 支持 egrep 所有的正则表达式 |
| sed | 默认不支持扩展表达式,加-r 选项开启 ERE。如果不加-r 使用花括号要加转义符\{\} |
sed详解
1. 前言
- 我们都知道,在Linux中一切皆文件,比如配置文件,日志文件,启动文件等等。如果我们相对这些文件进行一些编辑查询等操作时,我们可能会想到一些vi,vim,cat,more等命令。但是这些命令效率不高,而在linux中有三种工具:顶配awk,中配sed,标配grep。使用这些工具,我们能够在达到同样效果的前提下节省大量的重复性工作,提高效率。
- 文件内容可以是来自文件,也可以直接来自键盘或者管道等标准输入,最后的结果默认情况下是显示到终端的屏幕上,但是也可以输出到文件中。
- 编辑文件也是这样,以前我们修改一个配置文件,需要移动光标到某一行,然后添加点文字,然后又移动光标到另一行,注释点东西…….可能修改一个配置文件下来需要花费数十分钟,还有可能改错了配置文件,又得返工。这还是一个配置文件,如果数十个数百个呢?因此当你学会了sed命令,你会发现利用它处理文件中的一系列修改是很有用的。只要想到在大约100多个文件中,处理20个不同的编辑操作可以在几分钟之内完成,你就会知道sed的强大了。
2. 语法格式
sed [选项] [sed命令] [输入文件]
说明:
1,注意sed软件以及后面选项,sed命令和输入文件,每个元素之间都至少有一个空格。
2,sed -commands(sed命令)是sed软件内置的一些命令选项,为了和前面的options(选项)区分,故称为sed命令
3,sed -commands 既可以是单个sed命令,也可以是多个sed命令组合。
4,input -file (输入文件)是可选项,sed还能够从标准输入如管道获取输入。
3. sed的工作原理
sed读取一行,首先将这行放入到缓存中
然后,才对这行进行处理
处理完成以后,将缓冲区的内容发送到终端
存储sed读取到的内容的缓存区空间称之为:模式空间(Pattern Space)
4. 选项说明
| option[选项] | 解释说明(带*的为重点) |
|---|---|
| -n (no) | 取消默认的sed软件的输出,常与sed命令的p连用。* |
| -e (entry) | 一行命令语句可以执行多条sed命令 * |
| -r (ruguler) | 使用扩展正则表达式,默认情况sed只识别基本正则表达式 * |
| -i (inside) | 直接修改文件内容,而不是输出到终端,如果不使用-i选项sed软件只是修改在内存中的数据,并不会影响磁盘上的文件* |
| sed -commands[sed命令] | 解释说明(带*的为重点) |
|---|---|
| a (append) | 追加,在指定行后添加一行或多行文本 * |
| c (change) | 取代指定的行 |
| d (delete) | 删除指定的行 * |
| i (insert) | 插入,在指定行前添加一行或多行文本 * |
| p (print) | 打印模式空间内容,通常p会与选项-n一起使用* |
| 特殊符号 | 解释说明(带*的为重点) |
|---|---|
| ! | 对指定行以外的所有行应用命令* |
awk详解
awk不仅仅时linux系统中的一个命令,而且是一种编程语言,可以用来处理数据和生成报告(excel)。处理的数据可以是一个或多个文件,可以是来自标准输入,也可以通过管道获取标准输入,awk可以在命令行上直接编辑命令进行操作,也可以编写成awk程序来进行更为复杂的运用。
awk的格式
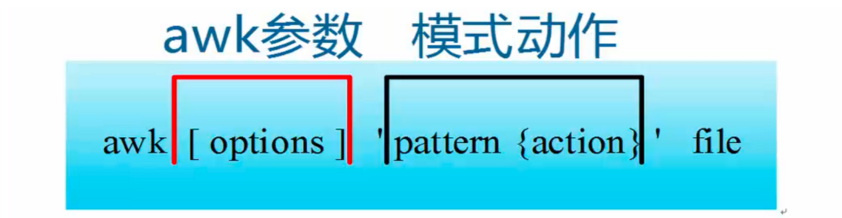
- awk指令是由模式,动作,或者模式和动作的组合组成。
- 模式既pattern,可以类似理解成sed的模式匹配,可以由表达式组成,也可以是两个正斜杠之间的正则表达式。比如NR==1,这就是模式,可以把他理解为一个条件。
- 动作即action,是由在大括号里面的一条或多条语句组成,语句之间使用分号隔开。比如awk使用格式:

awk处理的内容可以来自标准输入(<),一个或多个文本文件或管道。

-
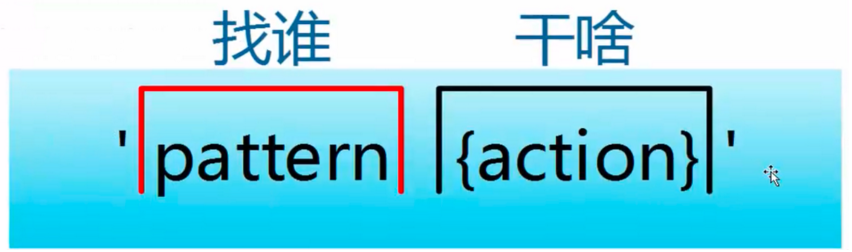
- pattern既模式,也可以理解为条件,也叫找谁,你找谁?高矮,胖瘦,男女?都是条件,既模式。
- action既动作,可以理解为干啥,找到人之后你要做什么。
模式和动作的详细介绍我们放在后面部分,现在大家先对awk结构有一个了解。
awk参数
-F:指定分隔符
几个小概念
记录(record):一行就是一个记录
分隔符(field separator):进行对记录进行切割的时候所使用的字符
字段(field):将一条记录分割成的每一段
FILENAME:当前处理文件的文件名
FS(Field Separator):字段分隔符(默认是以空格为分隔符=)
NR(Number of Rrecord):记录的编号(awk每读取一行,NR就加1==)
NF(Number of Field):字段数量(记录了当前这条记录包含多少个字段==)
ORS(Output Record Separator):指定输出记录分隔符(指定在输出结果中记录末尾是什么,默认是\n,也就是换行)
OFS(Output Field Separator):输出字段分隔符
RS:记录分隔符
输出字段的表示方式
$1 $2 … $n 输出一个指定的字段
$NF 输出最后一个字段
$0 输出整条记录
awk进阶–正则
正则表达式的运用,默认是在行内查找匹配的字符串,若有匹配则执行action操作,但是有时候仅需要固定的列来匹配指定的正则表达式,比如:我想取/etc/passwd文件中第五列{$5}这一列查找匹配mail字符串的行,这样就需要用另外两个匹配操作符,并且awk里面只有这两个操作符来匹配正则表达式。
awk特殊模式-BEGIN模式与END模式
BEGIN模块再awk读取文件之前就执行,一般用来定义我们的内置变量(预定义变量,eg:FS,RS)
需要注意的是BEGIN模式后面要接跟一个action操作块,包含在大括号内。awk必须在输入文件进行任何处理前先执行BEGIN里的动作(action)。我们可以不要任何输入文件,就可以对BEGIN模块进行测试,因为awk需要先执行完BEGIN模式,才对输入文件做处理。BEGIN模式常常被用来修改内置变量ORS,RS,FS,OFS等值。
awk数组
数组构成:
数组名[元素名]=值
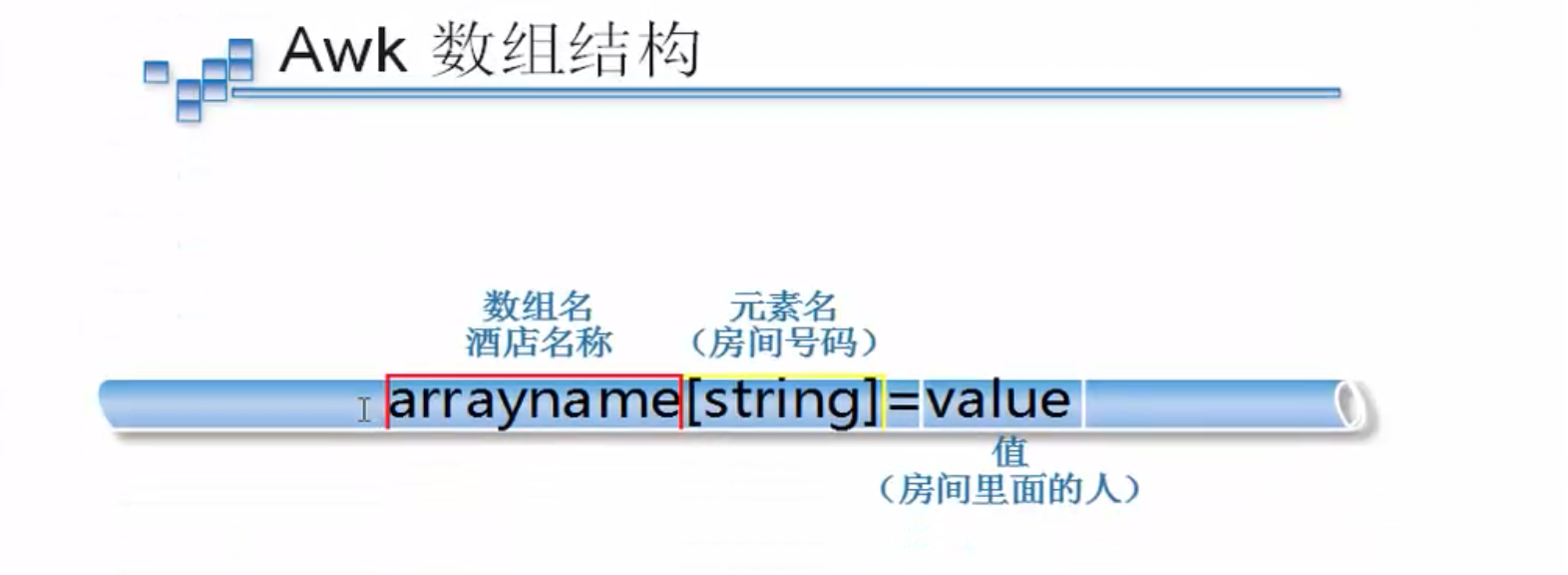

如图不难发现,awk数组就和酒店一样。数组的名称就像是酒店名称,数组元素名称就像酒店房间号码,每个数组元素里面的内容就像是酒店房间里面的人。
sed和awk实例
sed增删改查演示
- 增a
例子1:添加单行
[root@ken ~]# sed ‘1a nihao’ test
root:x:0:0:root:/root:/bin/bash
nihao
bin:x:1:1:bin:/bin:/sbin/nologin
例子2:添加单行
[root@ken ~]# sed ‘2a nihao’ test
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
nihao
例子3:添加多行
[root@ken ~]# sed ‘2a 1\n2\n3\n4\n5’ test
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
1
2
3
4
5
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
例子4:行尾添加
[root@ken ~]# sed ‘$a nihao’ test
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
nihao
增i
例子5:单行添加
[root@ken ~]# sed ‘1i nihao’ test
nihao
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
例子6:添加多行
[root@ken ~]# sed ‘1i 1\n2\n3\n4’ test
1
2
3
4
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
2.删d
例子1:删除指定行
[root@ken ~]# sed ‘1d’ test
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
例子2:删除多行
[root@ken ~]# sed ‘1,9d’ test
operator:x:11:0:operator:/root:/sbin/nologin
例子3:删除全文
[root@ken ~]# sed ‘d’ test
例子4:删除指定行到结尾的行
[root@ken ~]# sed ‘3,$d’ test
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
3.改 c
文本替换
接下来说的这个功能,有工作经验的同学应该非常的熟悉,因为使用sed软件80%的场景就是使用替换功能。
这里用到的sed命令,选项:
“s”:单独使用–>将每一行中第一处匹配的字符串进行替换==>sed命令
“g”:每一行进行全部替换–>sed命令s的替换标志之一(全局替换),非sed命令。
“-i”:修改文件内容–>sed软件的选项,注意和sed命令i区别。
例子1:改指定的行
[root@ken ~]# sed ‘1c nihao’ test
nihao
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
例子2:改指定的几行
[root@ken ~]# sed ‘1,3c nihao’ test
nihao
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
注意:以后再工作中如果你要修改一个配置文件,首先必须先要备份。
4.查p
例子1:打印第一行
[root@ken ~]# sed ‘1p’ test
root:x:0:0:root:/root:/bin/bash
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
例子2:不打印模式空间的内容
[root@ken ~]# sed -n ‘1p’ test
root:x:0:0:root:/root:/bin/bash
例子3:打印多行
[root@ken ~]# sed -n “1,5p” test
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sed替换
例子1:把所有行的第一个root替换为ken
[root@ken ~]# sed ‘s/root/ken/’ test
ken:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/ken:/sbin/nologin
例子2:把所有行的root替换为ken
[root@ken ~]# sed ‘s/root/ken/g’ test
ken:x:0:0:ken:/ken:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/ken:/sbin/nologin
sed正则
例子1:删除root开头的行
[root@ken ~]# sed ‘/^root/d’ test
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
例子2:删除以sync结尾的行
[root@ken ~]# sed ‘/sync$/d’ test
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
例子3:仅仅匹配以root开头的行的root
[root@ken ~]# sed ‘/^root/{s/root/ken/g}’ test
ken:x:0:0:ken:/ken:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
例子4:使用sed开启selinux
[root@ken ~]# sed -i “s/\(SELINUX=\)disabled/\1enforcing/g” /etc/sysconfig/selinux
[root@ken ~]# cat /etc/sysconfig/selinux
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing – SELinux security policy is enforced.
# permissive – SELinux prints warnings instead of enforcing.
# disabled – No SELinux policy is loaded.
SELINUX=enforcing
# SELINUXTYPE= can take one of three two values:
# targeted – Targeted processes are protected,
# minimum – Modification of targeted policy. Only selected processes are protected.
# mls – Multi Level Security protection.
SELINUXTYPE=targeted
sed多点操作
-e
例子1:删除空白行和井号注释的行
[root@ken ~]# sed -e “/^$/d” -e “/^#/d” test
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
i#adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
删除注释行和空白行
第一种方法:
[root@ken ~]# cp test{,.bak}
[root@ken ~]# ls
anaconda-ks.cfg a.out ken1 test test1 test2 test.bak test.txt
[root@ken ~]# grep -v -E “(^$)|(^#)” test.bak
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
i#adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@ken ~]# grep -v -E “(^$)|(^#)” test.bak > test
[root@ken ~]# cat test
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
i#adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
第二种方法:
[root@ken ~]# sed -i -e ‘/^$/d’ -e ‘/^#/d’ test.bak
[root@ken ~]# cat test.bak
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
i#adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
awk详解
例子1:打印出来行号
[root@ken ~]# awk ‘{print NR,$0}’ test
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 i#adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
7 halt:x:7:0:halt:/sbin:/sbin/halt
8 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
9 operator:x:11:0:operator:/root:/sbin/nologin
例子2:打印出来2,5行的内容
[root@ken ~]# awk ‘NR>=2&&NR<=5{print $0}’ test
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
i#adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
分析awk处理过程:
读取文本第一行,首先会和匹配模式进行相匹配,如果发现第一行内容不和模式相匹配的话,就继续读取下一行
读取到第二行发现和模式相匹配,就会执行花括号里面的动作
然后继续读取下一行,发现和模式相匹配,就会执行花括号里面的动作
…
依次读取全文
例子3:打印多余五个字段的行
[root@ken ~]# awk -F “:” ‘NF>=5{print $0}’ test
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
i#adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
例子4:打印一冒号为分隔符的最后一个字段
[root@ken ~]# awk -F “:” ‘{print $NF}’ test
/bin/bash
/sbin/nologin
/sbin/nologin
/sbin/nologin
/sbin/nologin
/sbin/shutdown
/sbin/halt
/sbin/nologin
/sbin/nologin
例子5:打印出来用户名以及对应的shell类型
[root@ken ~]# awk -F “:” ‘{print $1,$NF}’ test
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
i#adm /sbin/nologin
lp /sbin/nologin
shutdown /sbin/shutdown
halt /sbin/halt
mail /sbin/nologin
operator /sbin/nologin
[root@ken ~]# awk -F “:” ‘{print $1,$7}’ test
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
i#adm /sbin/nologin
lp /sbin/nologin
shutdown /sbin/shutdown
halt /sbin/halt
mail /sbin/nologin
operator /sbin/nologin
[root@ken ~]# awk -F “:” ‘NR==2{print $1,$7}’ test
bin /sbin/nologin
例子6:输出每行行号和该行有几个字段
[root@ken ~]# awk -F “:” ‘{print NR,NF}’ test
1 7
2 7
3 7
4 7
5 7
6 7
7 7
8 7
9 7
awk正则
例子1:打印出来以root开头的行
[root@ken ~]# awk ‘/^root/{print $0}’ test
root:x:0:0:root:/root:/bin/bash
[root@ken ~]# awk ‘/^root/’ test
root:x:0:0:root:/root:/bin/bash
例子2:打印出来以halt结尾的行
[root@ken ~]# awk ‘/halt$/{print $0}’ test
halt:x:7:0:halt:/sbin:/sbin/halt
例子3:第五个字段包含root的行
[root@ken ~]# awk -F “:” ‘$5~/root/{print $0}’ test
root:x:0:0:root:/root:/bin/bash
提示:
- $5表示第五个区域(列)
- ~表示匹配(正则表达式匹配)
- /root/表示匹配root这个字符串
$5~/root/表示第五个区域(列)匹配正则表达式/root/,既第5列包含root这个字符串,则显示这一行。
awk的BEGIN
例子1:
[root@ken ~]# awk -F “:” ‘BEGIN{print “user shell”}NR==2{print $1,$NF}’ test
user shell
bin /sbin/nologin
例子2:指定分隔符
[root@ken ~]# ip a | grep “global” | awk ‘BEGIN{FS=” +|/”}{print $3}’
192.168.64.4
awk的END
例子1:
[root@ken ~]# awk ‘{print $0}END{print “this is end”}’ test
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
i#adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
this is end
例子2:
[root@ken ~]# awk ‘BEGIN{i=0}/root/{i++}END{print i}’ test
2
或者
[root@ken ~]# awk ‘/root/{i++}END{print i}’ test
2
awk数组
统计域名出现的次数:
第一种方法:
[root@ken ~]# cat test | cut -d “/” -f 3 | sort | uniq -c | sort -rn
25 www.taobao.com
13 www.sina.com
7 www.qq.com
第二种方式:awk数组
[root@ken ~]# cat test | awk -F “/+” ‘{ken[$2]++}END{ for ( i in ken) print i,ken[i]}’
www.sina.com 13
www.qq.com 7
www.taobao.com 25
[root@ken ~]# cat test | awk -F “/+” ‘{ken[$2]++}END{ for ( i in ken) print ken[i],i}’ | sort -rn
25 www.taobao.com
13 www.sina.com
7 www.qq.com