Hadoop的工作模式:
(1)单机模式
不需要与其他节点交互,不需要使用HDFS,直接读写本地的文件系统
(2)伪分布模式
在一台单机上运行,用不同的进程模仿分布式运行中的各类节点
(3)分布式模式
在不同的机器上部署系统
Hadoop2.0的体系架构:
(1)公共组件Common
Common的定位:
Common的定位是其他模块的公共组件,定义了程序员取得集群服务的编程接口,为其他模块提供公用API。
作用:

降低Hadoop设计的复 杂 性 减少了其他模块之间的耦 合 性 增强了Hadoop的健 壮 性
功能:
(2)分布式文件系统HDFS
HDFS采用了master/slave架构来构建分布式存储集群,这种架构很容易向集群中任意添加或删除slave,具有很高的扩展性。
HDFS的架构:
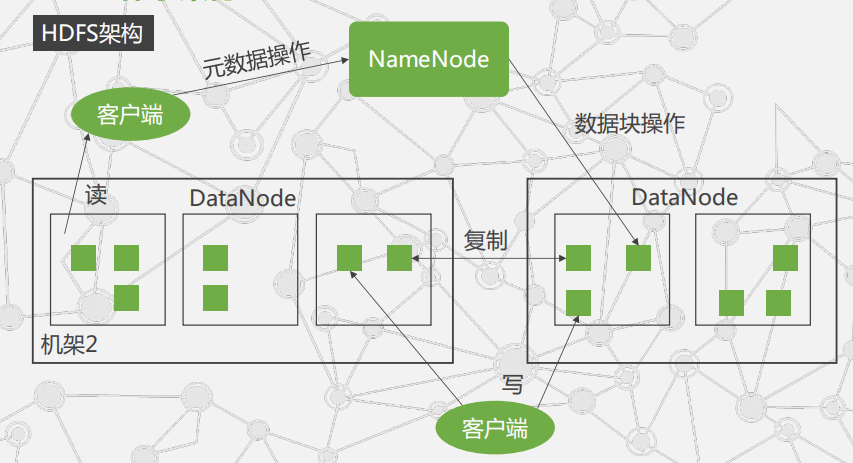
NameNode主控制服务器的作用:
负责维护文件系统的命名空间(Namespace)
协调客户端对文件的访问
记录命名空间内的任何改动或命名空间本身的属性改动
执行文件系统的命名空间操作
决定数据块到DataNode的映射
DataNode的作用:
负责它们所在的物理节点上的存储管理
HDFS开放文件系统的命名空间
HDFS采用master/slave体系来构建分布式存储服务
将文件分块存储
namenode统一管理
所有slave机器datanode存储空间,datanode以块为单位存储实际的数据
真正的文件I/O操作时客户端直接和datanode交互
客户端访问文件的操作: 客户端从NameNode获得组成文件的数据块的位置列表 ----> 客户端直接从DataNode上读取文件数据
NameNode使用事务日志(EditLog)记录HDFS元数据的变化,使用映象文件(FsImage)存储文件系统的命名空间
事务日志和映象文件都存储在NameNode的本地文件系统中。
将新的元数据刷新到本地磁盘的新的映象文件中,这样可以截去旧的事务日志,这个过程称为检查点(Checkpoint)
HDFS还有Secondary NameNode节点,它辅助NameNode处理映象文件和事务日志。
NameNode更新映象文件并清理事务日志,使得事务日志的大小始终控制在可配置的限度下
HDFS的典型拓扑:
一般拓扑:
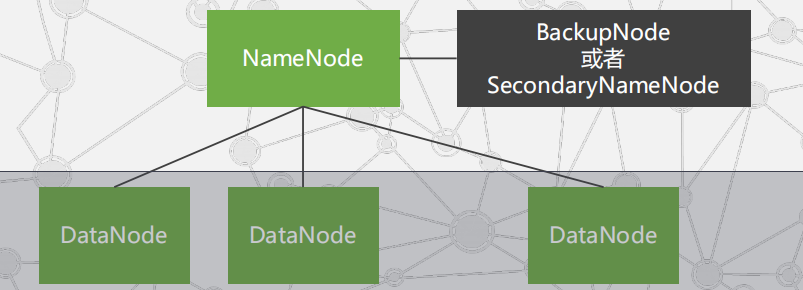
只有单个NameNode节点,使用SecondaryNameNode或BackupNode节点实时获取NameNode元数据信息,备份元数据。
商用拓扑:
有两个NameNode节点,并使用ZooKeeper实现NameNode节点间的热切换。
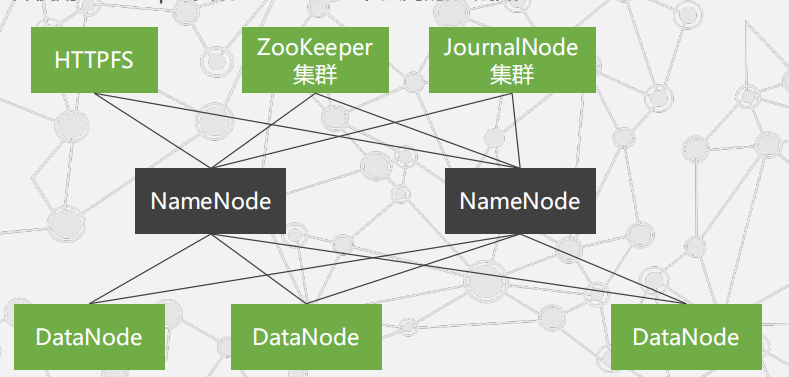
从架构上看HDFS存在单点故障,无论是一般拓扑还是商用拓扑,新增的实体几
乎都是
增强NameNode可靠性的组件:
JourNalNode集群: 至少三个,用于与两NameNode交换数据,也可使用NFS。
HTTPFS: 提供Web端读写HDFS功能
HDFS的内部特性:
1.冗余备份
2.副本存放
3.副本选择
4.心跳检测
5.数据完整性检测
6.元数据磁盘失效
7.简单一致性模型,流式数据访问
8.客户端缓存
9.流水线复制
10.机构特征
11.超大规模数据集
(3)分布式操作系统Yarn
(4)Hadoop2.0安全机制