1 Zookeeper简介-分布式服务框架
ZooKeeper为分布式应用程序提供高效且可靠的分布式协调服务,提供的服务:配置管理、统一命名服务、分布式同步、组服务等,是Google Chubby的开源实现,Hadoop和Hbase的重要组件;是一个典型的分布式数据一致性的解决方案,分布式应用程序可基于它实现诸如数据发布/订阅、负载均衡、分布式协调/通知、集群管理、Master选举、分布式锁和分布式队列等功能。
ZooKeeper的设计目标就是将复杂易出错的分布式一致性服务封装起来,构成高效可靠的原语集,并以一系列简单易用的接口提供给用户使用,支持Java和C的接口。
ZooKeeper代码版本中,提供了分布式独享锁、选举、队列的接口。其中分布锁和队列有Java和C两个版本,选举只有Java版本。
ZooKeeper是以Fast Paxos算法为基础的,Paxos 算法存在活锁的问题,即当有多个proposer交错提交时,有可能互相排斥导致没有一个proposer能提交成功,而Fast Paxos作了一些优化,通过选举产生一个leader (领导者),只有lead才能提交proposer[申请]。在解决分布式数据一致性方面,ZooKeeper并没有直接采用Paxos算法,而是使用ZAB的一致性协议 。
ZooKeeper的基本运转流程:
1、选举Leader。 2、同步数据。
3、选举Leader过程中算法有很多,但要达到的选举标准是一致的。
4、Leader要具有最高的zxid。
5、集群中大多数的机器得到响应并follow选出的Leader
2 常用命令
| 四字命令 | 功能描述 |
| conf | 输出相关服务配置的详细信息。 |
| cons | 列出所有连接到服务器的客户端的完全的连接 / 会话的详细信息。包括“接受 / 发送”的包数量、会话 id 、操作延迟、最后的操作执行等等信息 |
| dump | 列出未经处理的会话和临时节点。 |
| envi | 输出关于服务环境的详细信息(区别于 conf 命令)。 |

8 Zookeeper结构
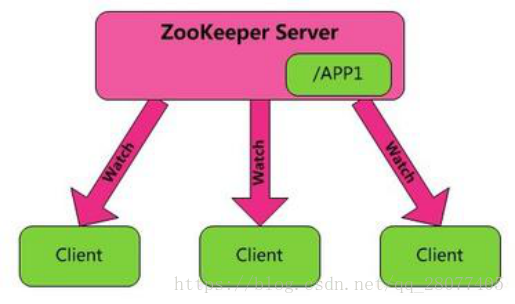
角色:Zookeeper=服务端+客户端

功能:Zookeeper=文件系统+通知机制

8.2通知机制
Zookeeper 的客户端和服务器通信采用长连接方式,客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点增加删除)时,每个客户端和服务器通过心跳来保持连接,zookeeper会通知客户端。
8.3总结



注:Zoopkeeper 提供了一套很好的分布式集群管理的机制,从而可以设计出多种多样的分布式的数据管理模型,而不仅仅局限于下面提到的几个常用应用场景。
原文转自:https://blog.csdn.net/qq_28077405/article/details/81699823
转载请注明出处!