神经网络输入层神经单元个数:784 (图像大小28*28)
输出层 :10 (10个类别分类,即10个数字)
隐藏层个数 :2
第1个隐藏层的神经单元数 :50
第2个隐藏层的神经单元数 :100
先定义get_data()、init_network()、predict()这3个函数:
1 def get_data(): 2 (x_train,t_train),(x_test,t_test)=load_mnist(nomalize=True,flatten=True,one_hot_label=False) 3 return x_test,t_test 4 5 def init_natwork(): 6 with open("sample_weight.pkl",'rb') as f: 7 network=pickle.load(f) 8 return network 9 10 def predict(network,x): 11 W1,W2,W3=network['W1'],network['W2'],network['W3'] 12 b1,b2,b3=network['b1'],network['b2'],network['b3'] 13 a1 = np.dot(x, W1) + b1 14 z1 = sigmoid(a1) 15 a2 = np.dot(z1, W2) + b2 16 z2 = sigmoid(a2) 17 a3 = np.dot(z2, W3) + b3 18 y = softmax(a3) 19 return y
init_network() 会读入保存在 pickle 文件 sample_weight.pkl 中的学习到的权重参数 {8[因为之前我们假设学习已经完成,所以学习到的参数被保存下来。假设保存在 sample_weight.pkl 文件中,在推理阶段,我们直接加载这些已经学习到的参数。——译者注]}。这个文件中以字典变量的形式保存了权重和偏置参数。剩余的 2 个函数,和前面介绍的代码实现基本相同,无需再解释。现在,我们用这 3 个函数来实现神经网络的推理处理。然后,评价它的识别精度(accuracy),即能在多大程度上正确分类。
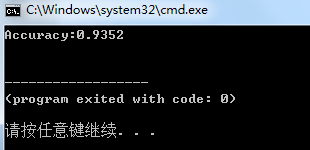
1 x, t = get_data() 2 network = init_network() 3 4 accuracy_cnt = 0 5 for i in range(len(x)): 6 y = predict(network, x[i]) 7 p = np.argmax(y) # 获取概率最高的元素的索引 8 if p == t[i]: 9 accuracy_cnt += 1 10 11 print("Accuracy:" + str(float(accuracy_cnt) / len(x)))
首先获得 MNIST 数据集,生成网络。接着,用 for 语句逐一取出保存在 x 中的图像数据,用 predict() 函数进行分类。predict() 函数以 NumPy 数组的形式输出各个标签对应的概率。比如输出 [0.1, 0.3, 0.2, ..., 0.04]的数组,该数组表示“0”的概率为 0.1,“1”的概率为 0.3,等等。然后,我们取出这个概率列表中的最大值的索引(第几个元素的概率最高),作为预测结果。可以用 np.argmax(x) 函数取出数组中的最大值的索引,np.argmax(x) 将获取被赋给参数 x 的数组中的最大值元素的索引。最后,比较神经网络所预测的答案和正确解标签,将回答正确的概率作为识别精度。
下面我们进行基于批处理的代码实现。这里用粗体显示与之前的实现的不同之处。
1 x, t = get_data() 2 network = init_network() 3 4 batch_size = 100 # 批数量 5 accuracy_cnt = 0 6 7 for i in range(0, len(x), batch_size): 8 x_batch = x[i:i+batch_size] 9 y_batch = predict(network, x_batch) 10 p = np.argmax(y_batch, axis=1) 11 accuracy_cnt += np.sum(p == t[i:i+batch_size])
我们来逐个解释粗体的代码部分。首先是 range() 函数。range() 函数若指定为 range(start, end),则会生成一个由 start 到 end-1 之间的整数构成的列表。若像 range(start, end, step) 这样指定 3 个整数,则生成的列表中的下一个元素会增加 step 指定的值。我们来看一个例子。
>>> list( range(0, 10) ) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> list( range(0, 10, 3) ) [0, 3, 6, 9]
在 range() 函数生成的列表的基础上,通过 x[i:i+batch_size] 从输入数据中抽出批数据。x[i:i+batch_n] 会取出从第 i 个到第 i+batch_n 个之间的数据。本例中是像 x[0:100]、x[100:200]……这样,从头开始以 100 为单位将数据提取为批数据。
然后,通过 argmax() 获取值最大的元素的索引。不过这里需要注意的是,我们给定了参数 axis=1。这指定了在 100 × 10 的数组中,沿着第 1 维方向(以第 1 维为轴)找到值最大的元素的索引(第 0 维对应第 1 个维度){9[矩阵的第 0 维是列方向,第 1 维是行方向。——译者注]}。这里也来看一个例子。
>>> x = np.array([[0.1, 0.8, 0.1], [0.3, 0.1, 0.6], ... [0.2, 0.5, 0.3], [0.8, 0.1, 0.1]]) >>> y = np.argmax(x, axis=1) >>> print(y) [1 2 1 0]
最后,我们比较一下以批为单位进行分类的结果和实际的答案。为此,需要在 NumPy 数组之间使用比较运算符(==)生成由True/False构成的布尔型数组,并计算True的个数。我们通过下面的例子进行确认。
>>> y = np.array([1, 2, 1, 0]) >>> t = np.array([1, 2, 0, 0]) >>> print(y==t) [True True False True] >>> np.sum(y==t) 3
仔细看过去,有很多内容之前不懂,看懂以后心里豁然开朗,不得不说真的是讲得很棒,清晰又容易理解。