参考:https://blog.csdn.net/zilong_zilong/article/details/51703399
环境:
ZooKeeper 节点:hdp-01(192.168.1.126) , hdp-02(192.168.1.127),hdp-03(192.168.1.128)
NameNode 节点:hdp-01(192.168.1.126) , hdp-02(192.168.1.127)
datanode 节点:hdp-03(192.168.1.128),hdp-04(192.168.1.132)
1 准备工作
使用hadoop用户:
免密:https://blog.csdn.net/daoxu_hjl/article/details/85546333
NFS: https://blog.csdn.net/daoxu_hjl/article/details/85416475
DNS: https://blog.csdn.net/daoxu_hjl/article/details/85563551
ZooKeeper: https://blog.csdn.net/daoxu_hjl/article/details/85729512
JDK节点都要安装
2 Hadoop安装与配置
主节点hdp-01操作:
2.1 下载并解压安装包
百度下载hadoop 安装包 hadoop-2.9.0.tar.gz ,并上传服务器
#进入安装目录
cd /opt
#创建hadoop 目录
mkdir hadoop
#解压安装包
cd hadoop
tar -zxvf /opt/nfs_share/software/hadoop-2.9.0.tar.gz
2.2 修改配置文件
xml里的注释在配置的时候可以去掉,避免错误
2.2.1 core-site.xml
vim /opt/hadoop/hadoop-2.9.0/etc/hadoop/core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 开启垃圾回收站功能,HDFS文件删除后先进入垃圾回收站,垃圾回收站最长保留数据时间为1天,超过一天后就删除 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<!-- Hadoop HA部署方式下namenode访问地址,bigdatacluster-ha是名字可自定义,后面hdfs-site.xml会用到 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdatacluster-ha</value>
</property>
<!--hadoop访问文件的IO操作都需要通过代码库。因此,在很多情况下,io.file.buffer.size都被用来设置SequenceFile中用到的读/写缓存大小。不论是对硬盘或者是网络操作来讲,较大的缓存都可以提供更高的数据传输,但这也就意味着更大的内存消耗和延迟。这个参数要设置为系统页面大小的倍数,以byte为单位,默认值是4KB,一般情况下,可以设置为64KB(65536byte),这里设置128K-->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hdp-01:2181,hdp-02:2181,hdp-03:2181</value>
</property>
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>300000</value>
</property>
<!-- 指定Hadoop压缩格式,Apache官网下载的安装包不支持snappy,需要自己编译安装,如何编译参考:http://aperise.iteye.com/blog/2254487,不适用snappy的话可以不配置
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
-->
</configuration>
2.2.2 hdfs-site.xml
vim /opt/hadoop/hadoop-2.9.0/etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--指定hdfs的nameservice为bigdatacluster-ha,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>bigdatacluster-ha</value>
</property>
<!—指定磁盘预留多少空间,防止磁盘被撑满用完,单位为bytes -->
<property>
<name>dfs.datanode.du.reserved</name>
<value>10240000</value>
</property>
<!-- bigdatacluster-ha下面有两个NameNode,分别是namenode1,namenode2 -->
<property>
<name>dfs.ha.namenodes.bigdatacluster-ha</name>
<value>namenode1,namenode2</value>
</property>
<!-- namenode1的RPC通信地址,这里端口要和core-site.xml中fs.defaultFS保持一致 -->
<property>
<name>dfs.namenode.rpc-address.bigdatacluster-ha.namenode1</name>
<value>hdp-01:9000</value>
</property>
<!-- namenode1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.bigdatacluster-ha.namenode1</name>
<value>hdp-01:50070</value>
</property>
<!-- namenode2的RPC通信地址,这里端口要和core-site.xml中fs.defaultFS保持一致 -->
<property>
<name>dfs.namenode.rpc-address.bigdatacluster-ha.namenode2</name>
<value>hdp-02:9000</value>
</property>
<!-- namenode2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.bigdatacluster-ha.namenode2</name>
<value>hdp-02:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hdp-01:8485;hdp-02:8485;hdp-03:8485/bigdatacluster-ha</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.bigdatacluster-ha</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制,主要用户远程管理监听其他机器相关服务 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免密码登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop/journal</value>
</property>
<!--指定支持高可用自动切换机制-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--指定namenode名称空间的存储地址-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/hdfs/name</value>
</property>
<!--指定datanode数据存储地址-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/hdfs/data</value>
</property>
<!--指定数据冗余份数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--指定可以通过web访问hdfs目录-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hdp-01:2181,hdp-02:2181,hdp-03:2181</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>600</value>
<description>The number of server threads for the namenode.</description>
</property>
<property>
<name>dfs.datanode.handler.count</name>
<value>600</value>
<description>The number of server threads for the datanode.</description>
</property>
<property>
<name>dfs.client.socket-timeout</name>
<value>600000</value>
</property>
<property>
<!--这里设置Hadoop允许打开最大文件数,默认4096,不设置的话会提示xcievers exceeded错误-->
<name>dfs.datanode.max.transfer.threads</name>
<value>409600</value>
</property>
</configuration>
2.2.3 mapred-site.xml
#复制模板
cp /opt/hadoop/hadoop-2.9.0/etc/hadoop/mapred-site.xml.template /opt/hadoop/hadoop-2.9.0/etc/hadoop/mapred-site.xml
vim /opt/hadoop/hadoop-2.9.0/etc/hadoop/mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 配置MapReduce运行于yarn中 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.job.maps</name>
<value>12</value>
</property>
<property>
<name>mapreduce.job.reduces</name>
<value>12</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hdp-01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hdp-01:19888</value>
</property>
<!-- 下面暂时全部注释掉:指定Hadoop压缩格式,Apache官网下载的安装包不支持snappy,需要自己编译安装,如何编译安装参考:http://aperise.iteye.com/blog/2254487有讲解,不适用snappy的话可以不配置
<property>
<name>mapreduce.output.fileoutputformat.compress</name>
<value>true</value>
<description>Should the job outputs be compressed?
</description>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.type</name>
<value>RECORD</value>
<description>If the job outputs are to compressed as SequenceFiles, how should
they be compressed? Should be one of NONE, RECORD or BLOCK.
</description>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
<description>If the job outputs are compressed, how should they be compressed?
</description>
</property>
<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
<description>Should the outputs of the maps be compressed before being
sent across the network. Uses SequenceFile compression.
</description>
</property>
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
<description>If the map outputs are compressed, how should they be
compressed?
</description>
</property>
-->
</configuration>
2.2.4 yarn-site.xml
vim /opt/hadoop/hadoop-2.9.0/etc/hadoop/yarn-site.xml
<?xml version="1.0"?>
<configuration>
<!--日志聚合功能yarn.log start------------------------------------------------------------------------>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--在HDFS上聚合的日志最长保留多少秒。3天-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>259200</value>
</property>
<!--日志聚合功能yarn.log end-------------------------------------------------------------------------->
<!--resourcemanager失联后重新链接的时间-->
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<!--配置resourcemanager start------------------------------------------------------------------------->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hdp-01:2181,hdp-02:2181,hdp-03:2181</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>besttonecluster-yarn</value>
</property>
<!--开启resourcemanager HA,默认为false-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hdp-01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hdp-02</value>
</property>
<!--配置rm1-->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hdp-01:8088</value>
</property>
<!--配置rm2-->
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hdp-02:8088</value>
</property>
<!--开启故障自动切换-->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.zk-base-path</name>
<value>/yarn-leader-election</value>
</property>
<!--开启自动恢复功能-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!--配置resourcemanager end--------------------------------------------------------------------------->
<!--配置nodemanager start----------------------------------------------------------------------------->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!--配置nodemanager end------------------------------------------------------------------------------->
</configuration>
2.2.4 slaves
只会在namenode上起作用,datanode上配置也无用
记录的是集群里所有DataNode的主机名
相当于是一份对于DN的白名单,只有在白名单里面的主机才能被NN识别
vim /opt/hadoop/hadoop-2.9.0/etc/hadoop/slaves
hdp-03
hdp-04
2.2.5 hadoop-env.sh & yarn-env.sh
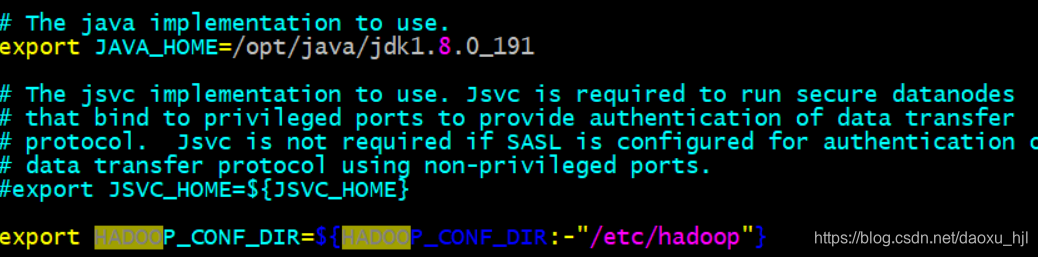
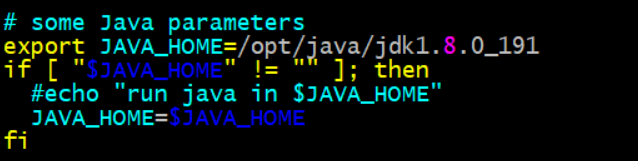
配置JAVA_HOME:此处不可以直接引用环境变量(${JAVA_HOME}):写JDK绝对路径
vim /opt/hadoop/hadoop-2.9.0/etc/hadoop/hadoop-env.sh
vim /opt/hadoop/hadoop-2.9.0/etc/hadoop/yarn-env.sh
2.2.6 配置环境变量
vim ~/.bash_profile
#添加
export HADOOP_HOME=/opt/hadoop/hadoop-2.9.0
export PATH=$HADOOP_HOME/bin:$PATH
source ~/.bash_profile
2.2.7 创建上述配置中定义的目录
mkdir -p /opt/hadoop/data
mkdir -p /opt/hadoop/tmp
mkdir -p /opt/hadoop/name
mkdir -p /opt/hadoop/journal
2.2.8 分发主节点hdp-01修改后的文件
scp -r /opt/hadoop/ hadoop@hdp-02:/opt/
scp -r /opt/hadoop/ hadoop@hdp-03:/opt/
scp -r /opt/hadoop/ hadoop@hdp-04:/opt/
scp -r ~/.bash_profile hadoop@hdp-02:~/.bash_profile
scp -r ~/.bash_profile hadoop@hdp-03:~/.bash_profile
scp -r ~/.bash_profile hadoop@hdp-04:~/.bash_profile
ssh hdp-02
source ~/.bash_profile
ssh hdp-03
source ~/.bash_profile
ssh hdp-04
source ~/.bash_profile
3 初次启动Hadoop HA
3.1 ZooKeeper集群启动并创建znode
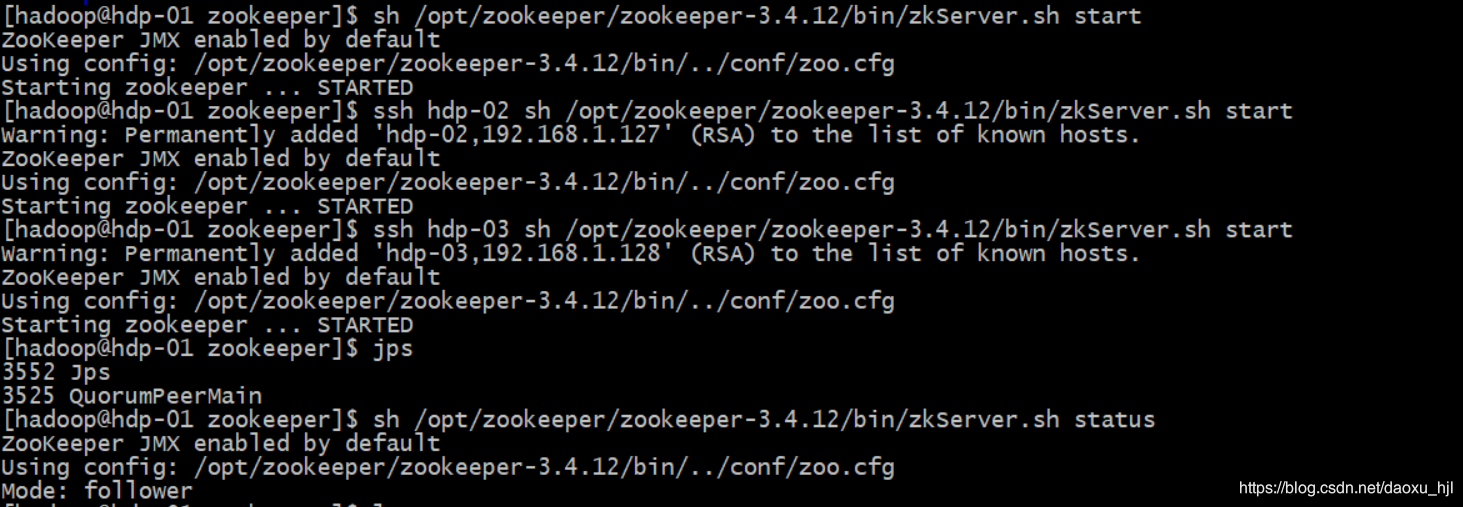
3.1.1 ZooKeeper集群启动
sh /opt/zookeeper/zookeeper-3.4.12/bin/zkServer.sh start
ssh hdp-02 sh /opt/zookeeper/zookeeper-3.4.12/bin/zkServer.sh start
ssh hdp-03 sh /opt/zookeeper/zookeeper-3.4.12/bin/zkServer.sh start
#查看状态
sh /opt/zookeeper/zookeeper-3.4.12/bin/zkServer.sh status
#验证进程:每个节点都要有 QuorumPeerMain进程
jps
3.1.2 格式化zookeeper上hadoop-ha目录
#格式化
hdfs zkfc -formatZK
#验证:检查zookeeper上是否已经有Hadoop HA目录
$ZOOKEEPER_HOME/bin/zkCli.sh -server hdp-01:2181,hdp-02:2181,hdp-03:2181
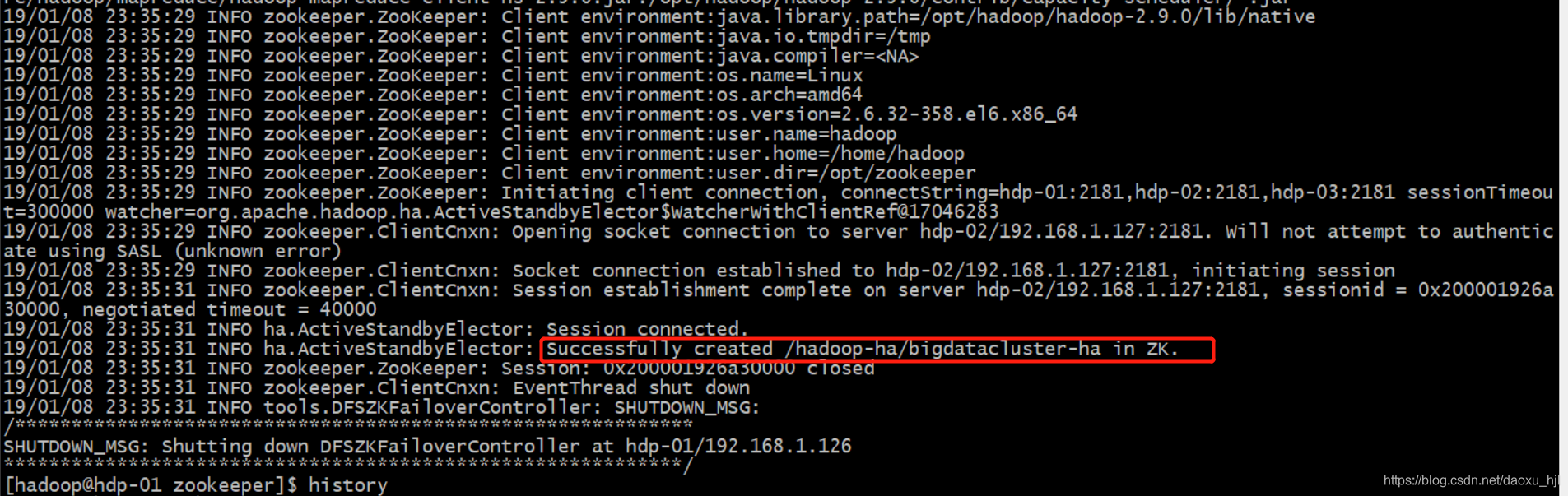
关键在与上面的“Successfully created /hadoop-ha/mycluster in ZK


3.1.3 启动namenode日志同步服务journalnode
所有ZooKeeper节点均启动
#当前节点
$HADOOP_HOME/sbin/hadoop-daemon.sh start journalnode
#其他节点
ssh hdp-02 $HADOOP_HOME/sbin/hadoop-daemon.sh start journalnode
ssh hdp-03 $HADOOP_HOME/sbin/hadoop-daemon.sh start journalnode


3.2 Hadoop集群格式化并启动
3.2.1 在主namenode节点格式化NAMENODE
hdfs namenode -format

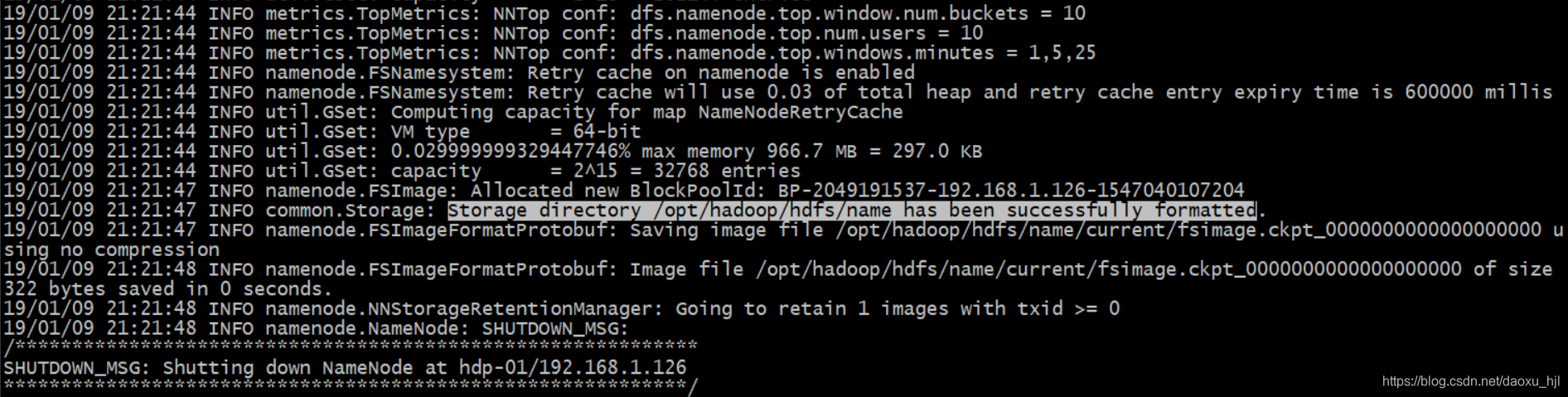
3.2.2 在主namenode节点启动namenode服务
$HADOOP_HOME/sbin/hadoop-daemon.sh start namenode

3.2.3 在备namenode节点同步元数据(此前一定要先启动主namenode) 并启动namenode 服务
#同步元数据
ssh hdp-02 $HADOOP_HOME/bin/hdfs namenode -bootstrapStandby


#备NameNode节点启动namenode服务
ssh hdp-02 $HADOOP_HOME/sbin/hadoop-daemon.sh start namenode

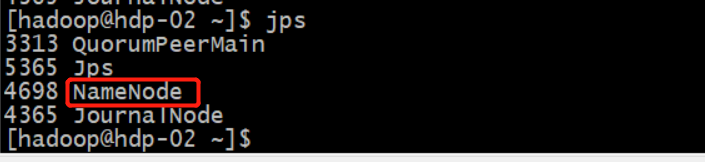
3.2.4 在所有namenode节点上启动DFSZKFailoverController
$HADOOP_HOME/sbin/hadoop-daemon.sh start zkfc
ssh hdp-02 $HADOOP_HOME/sbin/hadoop-daemon.sh start zkfc

3.2.5 启动datanode服务
#注意hadoop-daemons.sh datanode是启动所有datanode,而hadoop-daemon.sh datanode是启动单个datanode
$HADOOP_HOME/sbin/hadoop-daemons.sh start datanode

3.2.6 启动yarn
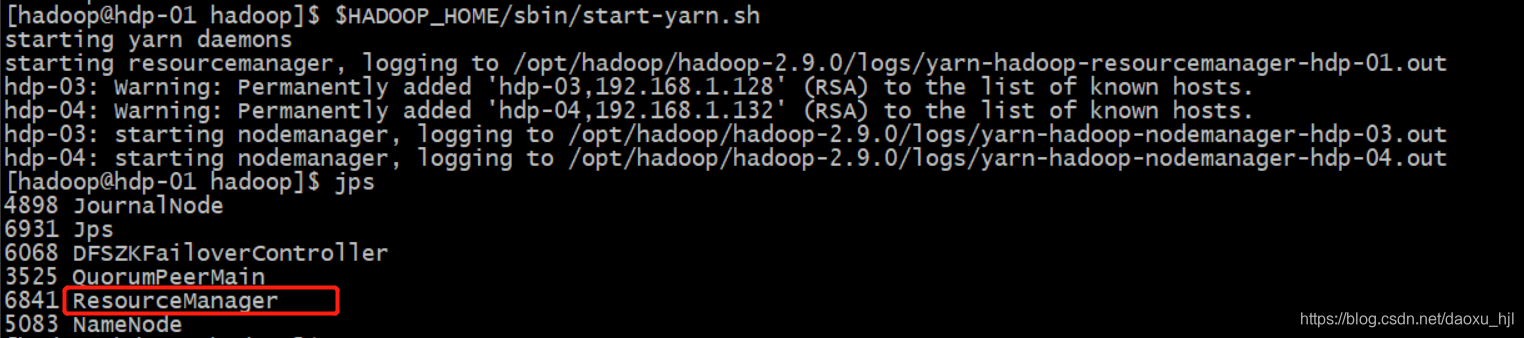
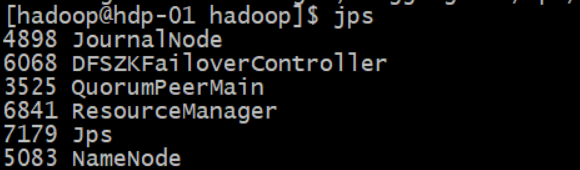
#主Namenode节点hdp-01启动resourcemanager,hdp-03/hdp-04启动nodemanager
$HADOOP_HOME/sbin/start-yarn.sh
#备Namenode节点hdp-02启动resourcemanager
ssh hdp-02 $HADOOP_HOME/sbin/yarn-daemon.sh start resourcemanager

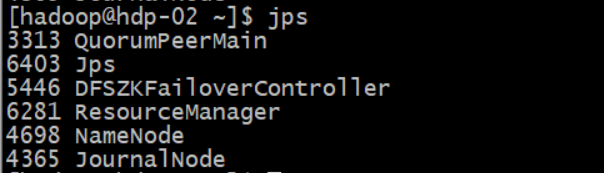
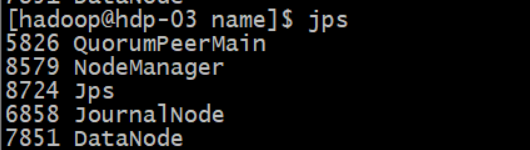
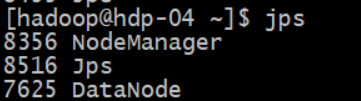
3.3 验证
3.3.1 主namenode状态(active)
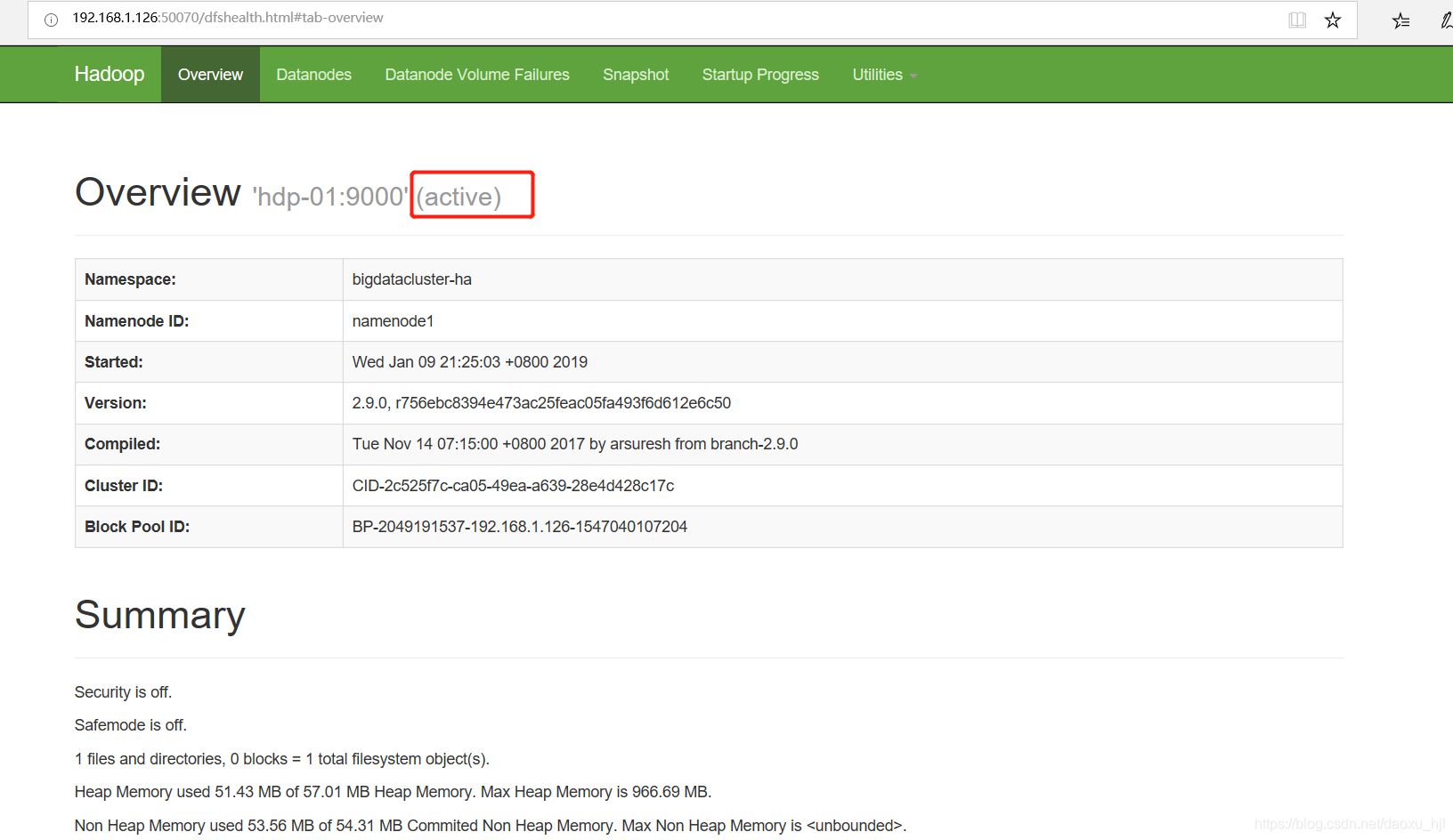
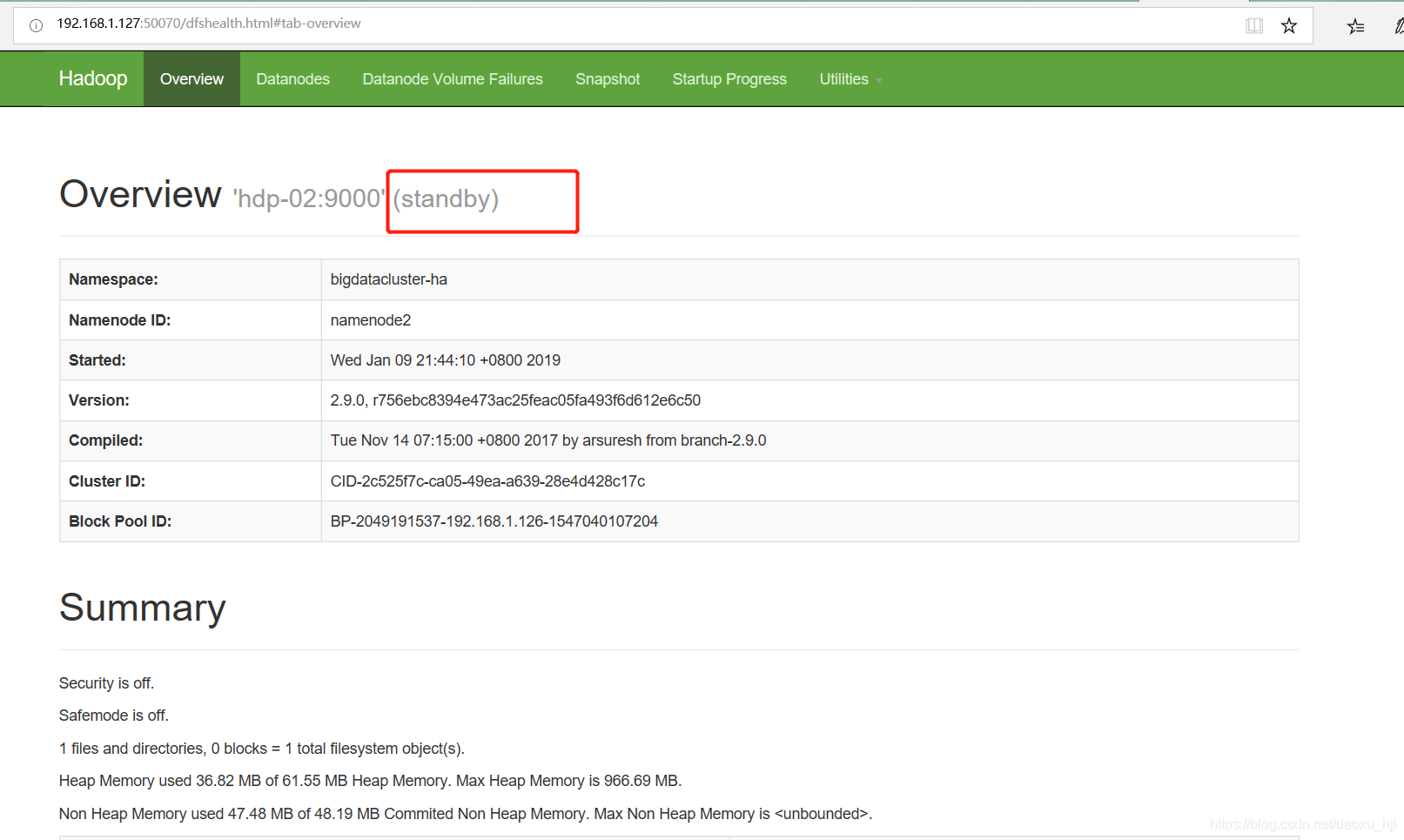
3.3.2 备namenode状态(standby)
yarn application:
192.168.1.126:50070
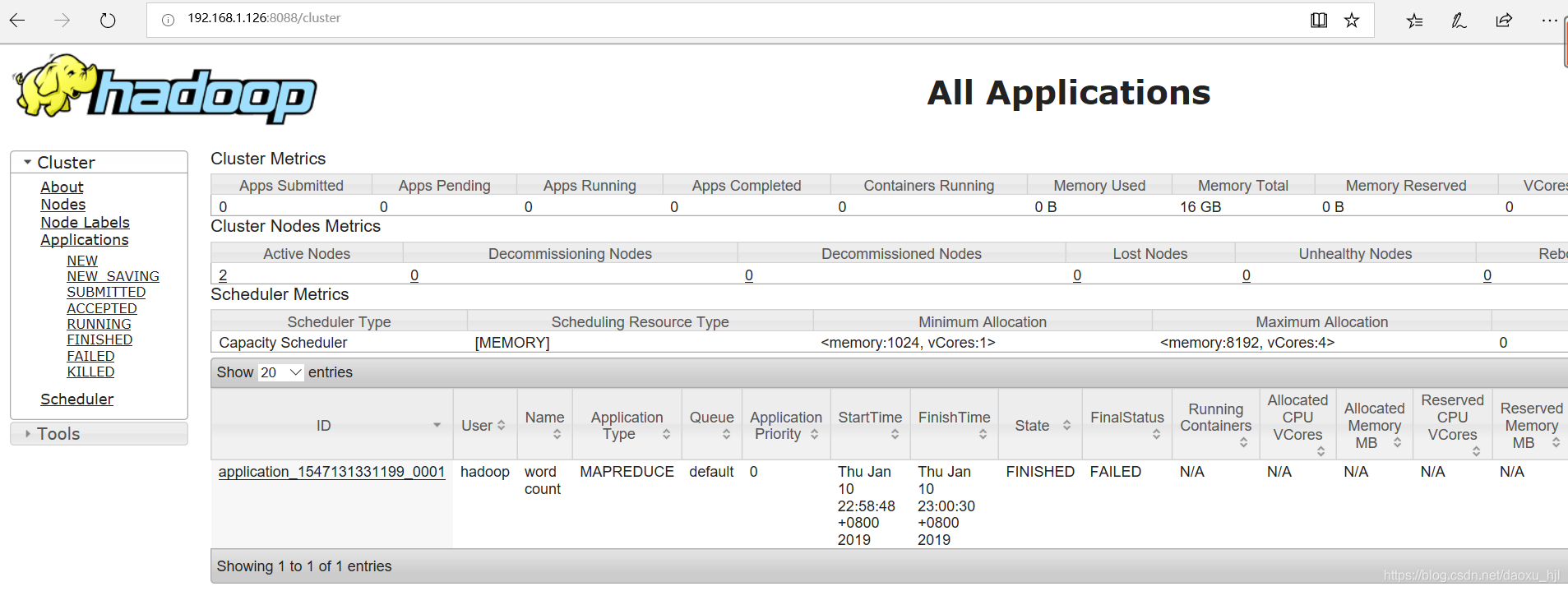
3.3.3 测试mapreduce程序
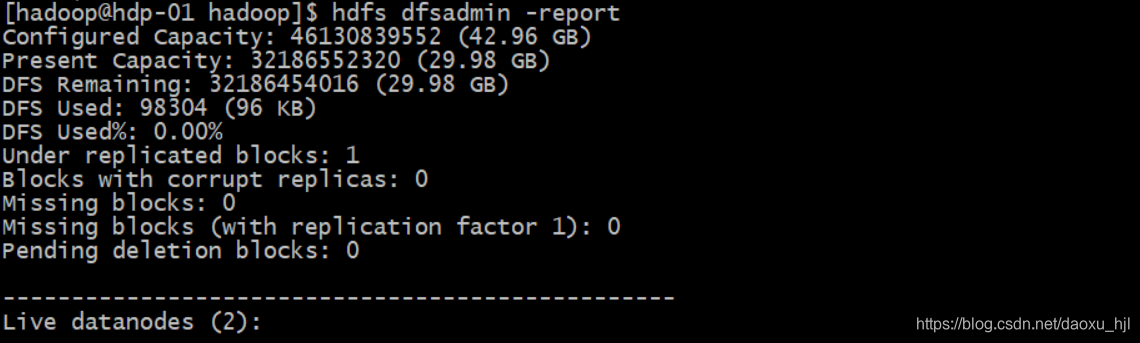
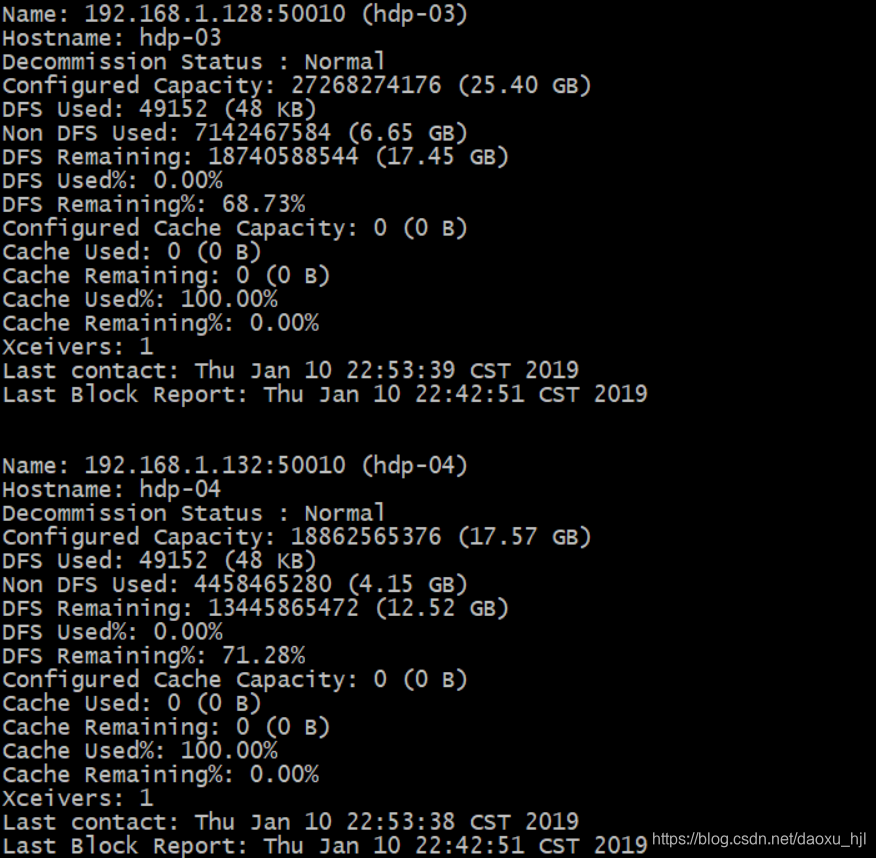
#datanode 报告
hdfs dfsadmin -report
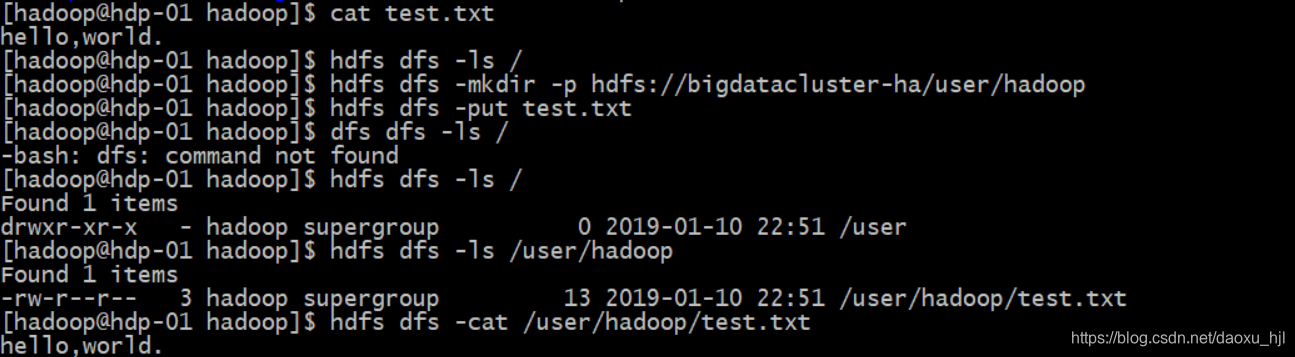
#创建hdfs 目录
hdfs dfs -mkdir -p hdfs://bigdatacluster-ha/user/hadoop
#上传测试文件
hdfs dfs -put test.txt
#可以查看上传后的文件
hdfs dfs -cat /user/hadoop/test.txt
#运行一个样例程序
hadoop jar /opt/hadoop/hadoop-2.9.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.0.jar wordcount /user/hadoop/test.txt /user/hadoop/out
3.3.3 重启集群
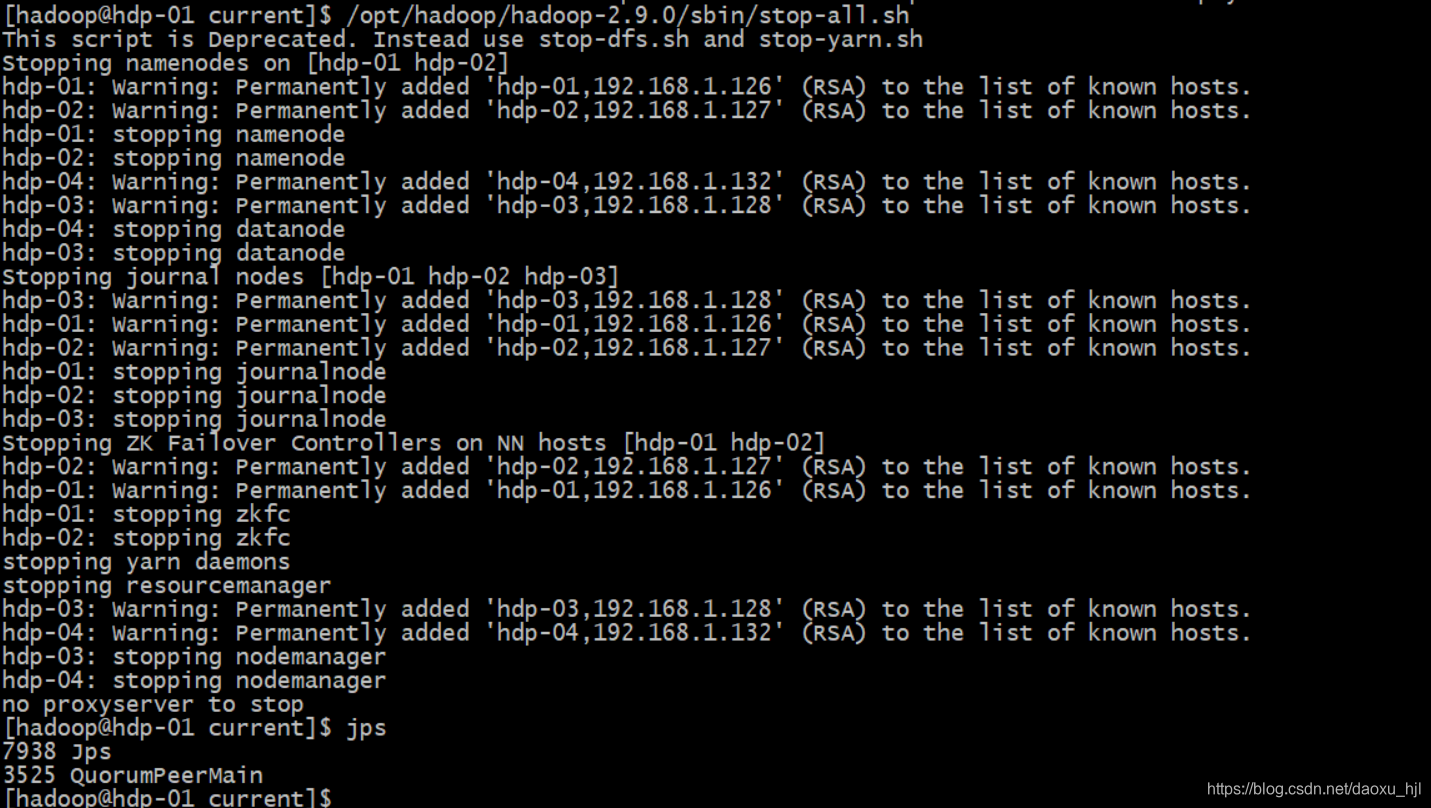
关闭:
/opt/hadoop/hadoop-2.9.0/sbin/stop-all.sh
启动ZooKeeper 集群:
各个zk节点都要:
$ZOOKEEPER_HOME/bin/zkServer.sh start
#验证是否有QuorumPeerMain进程
jps
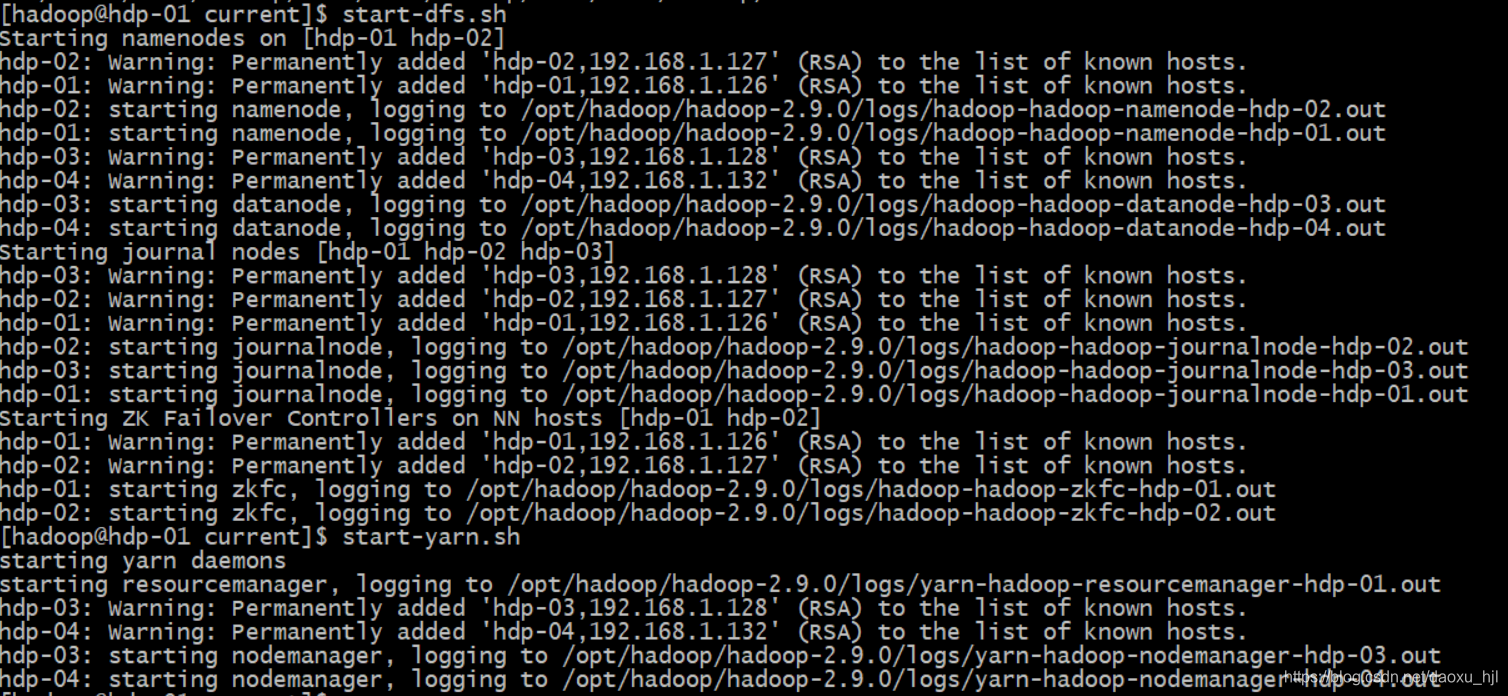
Hadoop HA集群正常启动:
start-dfs.sh
start-yarn.sh
4 问题
- Datanode的clusterID 与namenode不一致
namenode下 $HADOOP_HOME/name/current/VERSION 与 datanode节点下的$HADOOP_HOME/data/current/VERSION 中的clusterID不一致
解决:将datanode节点下的clusterID改成与namenode中的一致