搜索结果排序是搜索引擎最核心的构成部分,很大程度上决定了搜索引擎的质量好坏。虽然搜索引擎在实际结果排序时考虑了上百个相关因子,但最重要的因素还是用户查询与网页内容的相关性。(ps:百度最臭名朝著的“竞价排名”策略,就是在搜索结果排序时,把广告客户给钱最多的排在前列,而不是从内容质量考虑,从而严重影响了用户体验)。这里要讲的就是:给定用户搜索词,如何从内容相关性的角度对网页进行排序。判断网页内容是否与用户查询相关,这依赖于搜索引擎所采用的检索模型,常见的检索模型有:布尔模型、向量空间模型、概率模型和机器学习排序算法等。在我的项目中,使用了向量空间模型(Vector Space Model,VSM),因此这篇文章主要总结一下向量空间模型相关的内容。
向量空间模型是一种文档表示和相似性计算的工具,不仅在搜索领域,在自然语言处理、文本挖掘等领域也是普遍采用的工具。
1. 文档表示
作为表示文档的工具,向量空间模型把每个文档看做是由 t 维特征组成的一个向量,特征的定义可以采取不同方式,最常见的是以单词作为特征,就是从一篇文档中抽取出 t 个关键词,其中每个特征会根据某种算法计算其权重,这 t 维带有权重的特征向量就用来表示这一篇文档。
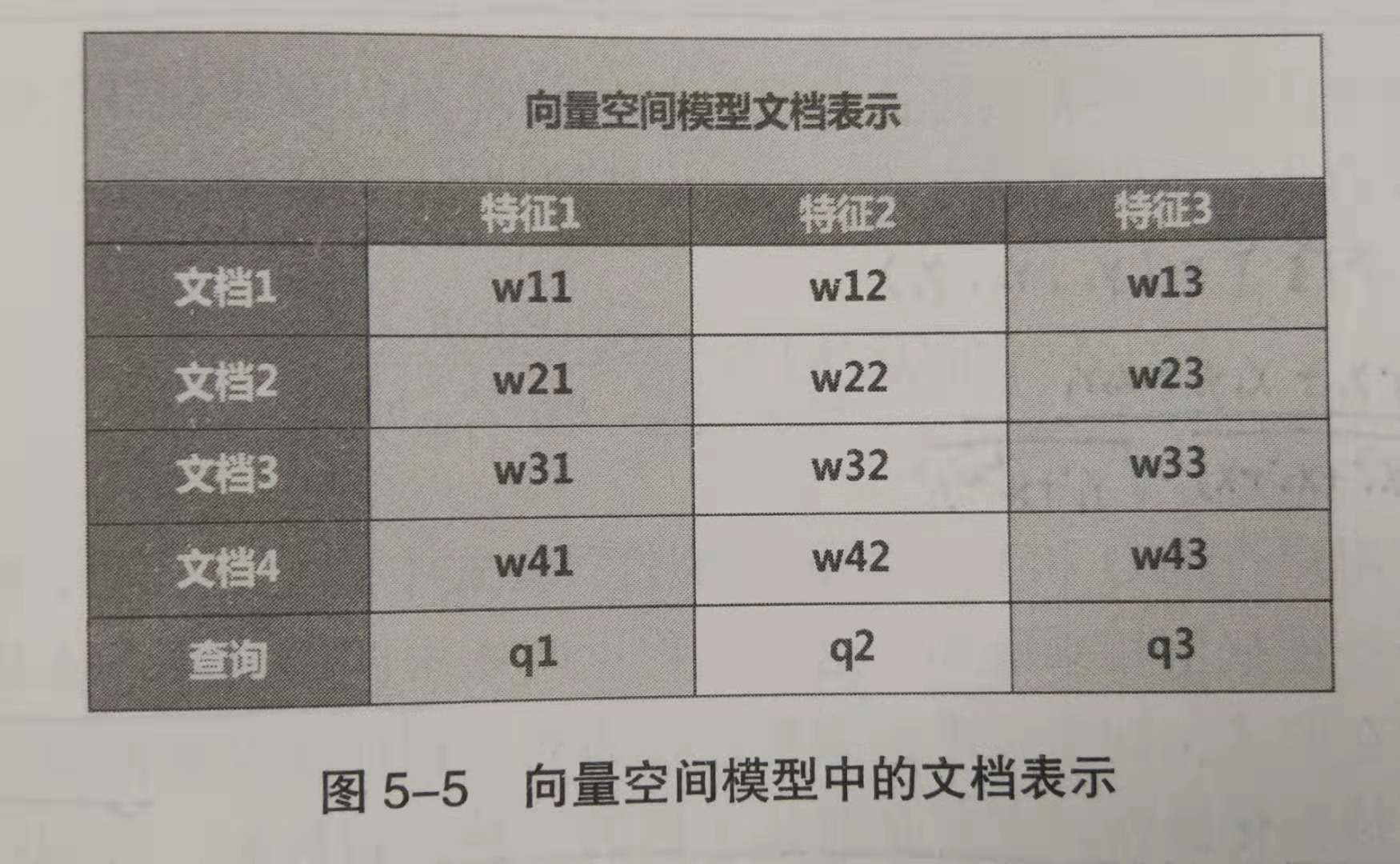
下图展示了4个文档在3维向量空间中如何表示,比如对于文档2,它由3个带有权重的特征组成{w21, w22, w23}。在实际应用中,维度通常是非常高的,达成千上万维,这里只是为了简化说明。用户查询也被看成是一个特殊的文档,也将其转换成 t 维的特征向量,之所以也将其转化为一个 t 维向量,是为了计算文档相似性,后面会说的。
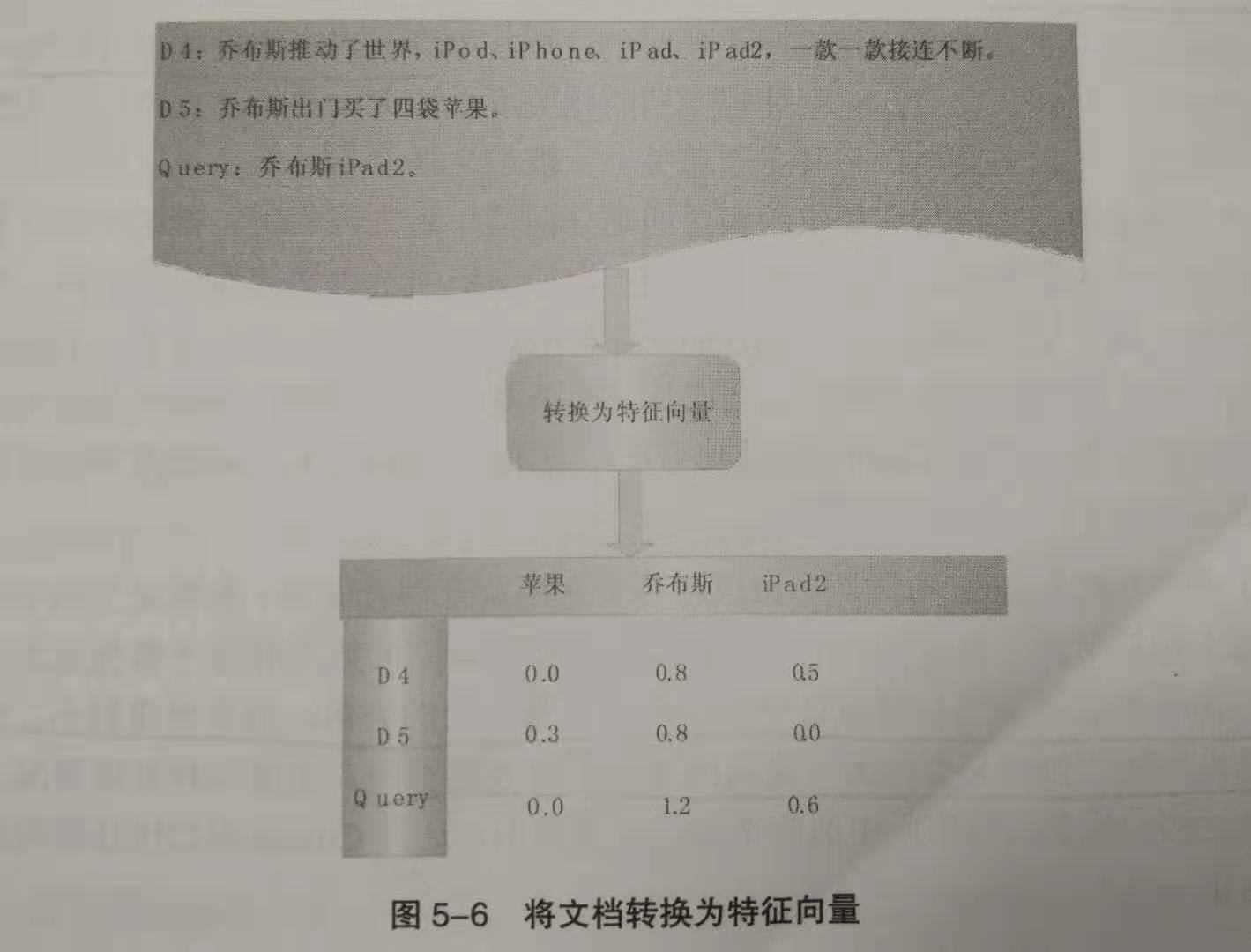
下面是一个文档表示的实例,对于文档D4、D5及用户查询,通过提取关键词进行特征转换,可表示如下。