可以使用人工打码平台进行破解:
本文不是讲如何破解谷歌的reCAPTCHA(实际上我们也办不到),而是介绍在程序中借助第三方(人工)打码平台顺利通过reCAPTCHA验证。
由于使用人工打码会产生费用,并且费用是和调用次数成正比的,所以本方法仅适用于reCAPTCHA出现频率比较低的场景,例如:
1)网站登录使用了reCAPTCHA。比如,有时Linkedin登录就会出现reCAPTCHA(如下图所示),验证当前客户端是否是“真人”。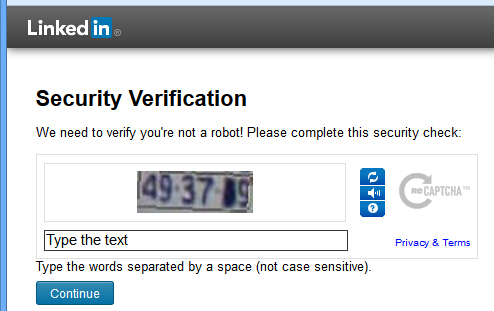
2)网站对访问频率过快的客户端返回reCAPTCHA,通过验证后即可继续访问。比如Zocdoc.com这个网站。
下面进入正题。如何在程序中借助第三方(人工)打码平台通过reCAPTCHA验证?
因为reCAPTCHA表单是JS动态创建的,我们遇到的第一个难题就是如何获取到reCAPTCHA表单中的验证码图片的路径及各隐藏表单域的值。
1)一个办法就是使用类似webkit的浏览器模拟工具(例如,phantomjs)加载页面,这样就能直接获取到JS生成的HTML源码。但是实现起来比较复杂,还需要借助第三方的软件。
2)查看源码会发现如果页面禁用了JS,reCAPTCHA将使用iframe模式加载(如下示),此时验证码图片路径和各表单项都是直接可见的。
所以我们直接请求“https://www.google.com/recaptcha/api/noscript?k=******”即可获取到验证码的图片路径和其它隐藏表单域的值。
这个问题解决了。接下来我们要获取到验证码图片对应的明文。如何调用第三方打码平台进行图片验证码识别呢?
我们需要先下载验证码图片,再把图片的二进制数据上传给打码平台,然后等待平台人工打码返回明文。打码平台一般都提供了供各种常见语言调用的API,所以该过程也比较简单。
现在我们已经获取到验证码图片对应的明文,只要我们将其和其它隐藏表单域参数一起提交就能完成验证过程了。
闲话不多说,还是直接上代码比较实在(Python实现, 这是我们真实项目中用到的):
- # coding: utf-8
- # recaptcha.py
- import sys
- import os
- os.chdir(os.path.dirname(os.path.realpath(sys.argv[0])))
- import re
- import StringIO
- import deathbycaptcha
- from urlparse import urljoin
- from webscraping import common, xpath
- DEATHBYCAPTCHA_USERNAME = '******'
- DEATHBYCAPTCHA_PASSWORD = '******'
- def read_captcha(image):
- """image - fileobj, the captcha to be recognized
- """
- client = deathbycaptcha.SocketClient(DEATHBYCAPTCHA_USERNAME, DEATHBYCAPTCHA_PASSWORD)
- try:
- balance = client.get_balance()
- # Put your CAPTCHA file name or file-like object, and optional
- # solving timeout (in seconds) here:
- common.logger.info('Submit captcha to http://deathbycaptcha.com/.')
- captcha = client.decode(image)
- if captcha:
- # The CAPTCHA was solved; captcha["captcha"] item holds its
- # numeric ID, and captcha["text"] item its text.
- common.logger.info("CAPTCHA %s solved: %s" % (captcha["captcha"], captcha["text"]))
- return captcha["text"].strip()
- except deathbycaptcha.AccessDeniedException:
- # Access to DBC API denied, check your credentials and/or balance
- common.logger.info('Access to DBC API denied, check your credentials and/or balance')
- def solve_recaptcha(html, D):
- """To solve the Google recaptcha
- """
- m = re.compile(r']+src="(https?://www\.google\.com/recaptcha/api/noscript\?k=[^"]+)"', re.IGNORECASE).search(html)
- if m:
- common.logger.info('Need to solve the recaptcha.')
- # need to solve the captcha first
- iframe_url = m.groups()[0]
- # load google recaptcha page
- iframe_html = D.get(iframe_url, read_cache=False)
- # extract recaptcha_challenge_field value for future use
- recaptcha_challenge_field = xpath.get(iframe_html, '//input[@id="recaptcha_challenge_field"]/@value')
- if recaptcha_challenge_field:
- # extract captcha image link
- captcha_image_url = xpath.get(iframe_html, '//img/@src')
- if captcha_image_url:
- captcha_image_url = urljoin(iframe_url, captcha_image_url)
- # download captcha
- captcha_bytes = D.get(captcha_image_url, read_cache=False)
- if captcha_bytes:
- #open('captcha.jpg', 'wb').write(captcha_bytes)
- fileobj = StringIO.StringIO(captcha_bytes)
- # read the captcha via deathbycaptcha
- recaptcha_response_field = read_captcha(fileobj)
- if recaptcha_response_field:
- common.logger.info('Have got the captcha content = "%s".' % str(recaptcha_response_field))
- url = 'https://www.linkedin.com/uas/captcha-submit'
- post_data = {}
- captcha_form = xpath.get(html, '//form[@name="captcha"]')
- for input_name, input_value in re.compile(r']+type="hidden"\s+name="([^<>\"]+)"\s+value="([^<>\"]+)"').findall(captcha_form):
- post_data[input_name] = input_value
- post_data['recaptcha_challenge_field'] = recaptcha_challenge_field
- post_data['recaptcha_response_field'] = recaptcha_response_field
- return D.get(url, data=post_data, read_cache=False)