上一篇中我们了解了MapReduce和Yarn的基本概念,这里就不再陈述,接下来带领大家搭建下Mapreduce-HA的框架。
结构图如下( ﹁ ﹁ ) ~→
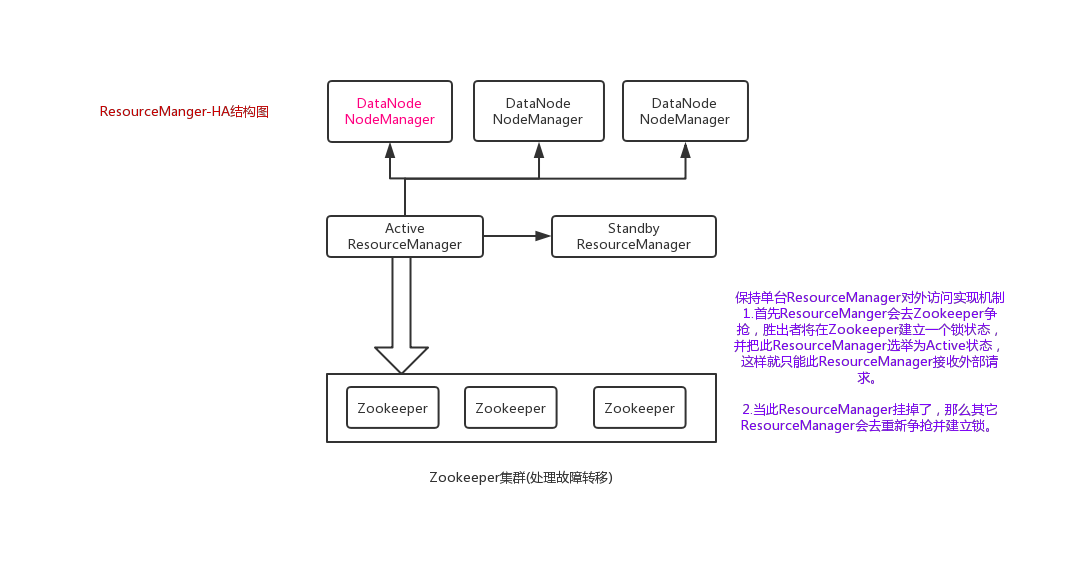
开始搭建( ﹁ ﹁ ) ~→
一.配置环境
注:可以现在一台计算机上进行配置,然后分发给其它服务器
1.1编辑mapred-site.xml文件:
进入目录 /opt/hadoop/hadoop-2.6.5/etc/hadoop
cd /opt/hadoop/hadoop-2.6.5/etc/hadoop
vim mapred-site.xml
添加如下配置:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value> <!--指定mapreduce通过yarn获取数据,还可以填写参数localhost-->
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
1.2编辑yarn-site.xml文件:
vim yarn-site.xml
添加如下配置:
<configuratoin>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value> <!--指定nodemanager可以拉取数据-->
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value><!--启动resourcemanager高可用-->
</property>
<property>
<name>hadoop.zk.address</name><!--配置zookeeper地址-->
<value>tuge1:2181,tuge2:2181,tuge3:2181,tuge4:2181</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value><!--配置resourcemanager虚拟地址到物理地址的映射-->
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>tuge1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>tuge2</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>tuge1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>tuge2:8088</value>
</property>
</configuration>
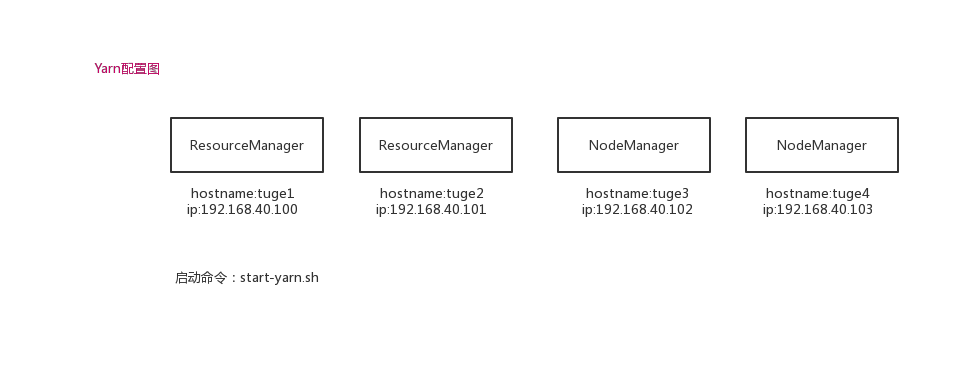
二.启动程序
在tuge1服务器启动:
vim /opt/hadoop/hadoop-2.6.5/sbin
start-yarn.sh
启动后,使用jps即可查看resourcemanager和nodemanager是否启动成功。
三.浏览效果
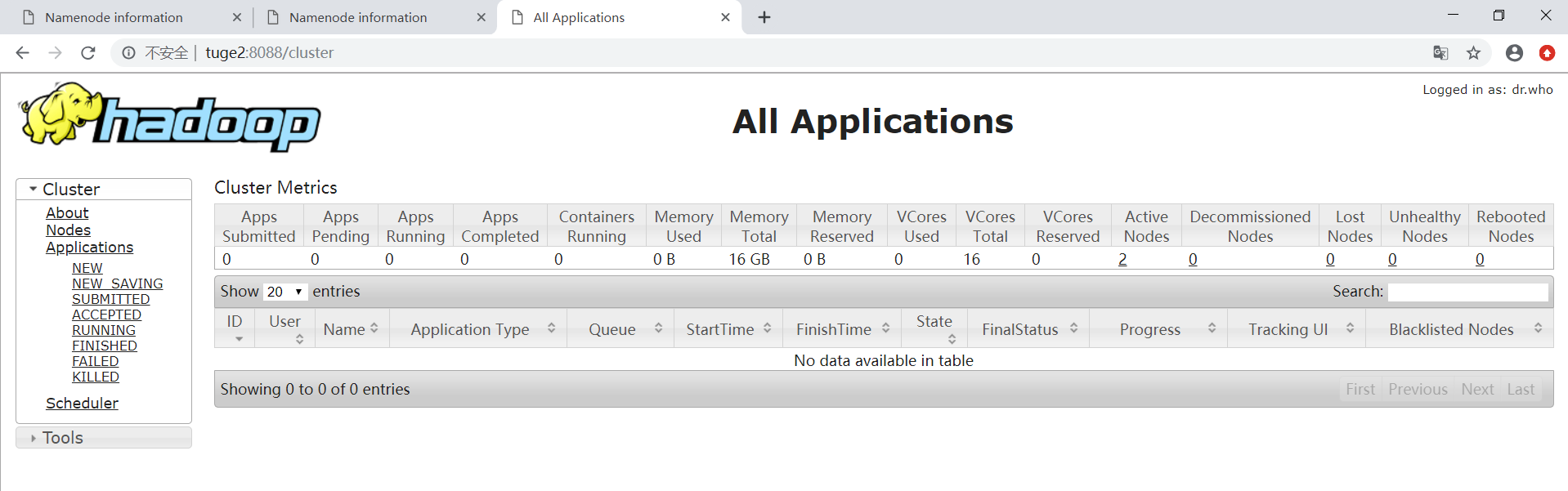
四.实现一个计算Demo
4.1在hdfs里面创建一个10000行的test.txt文件
使用命令:
--首先创建一个root文件夹
hadoop fs -mkdir /user/root/
--在linux随便找一个目录创建一个文件,并加入1万行What are you doing 123?
touch test.txt
vim test.txt
然后输入数字10000,再点击i进行输入What are you doing 123? ,然后按Esc 这时10000行What are you doing 123?就录入了,然后保存。
--将本地文件复制到hdfs上面
hadoop dfs -scpFromLocal test.txt /user/root/
4.2进入/opt/hadoop/hadoop-2.6.5/share/hadoop/mapreduce
cd /opt/hadoop/hadoop-2.6.5/share/hadoop/mapreduce
4.3 使用mapreduce统计刚刚上传文件里面的单词数量
hadoop jar hadoop-mapreduce-examples-2.6.5.jar /user/root/test.txt /user/root/result --意思是使用hadoop 运行jar环境,并执行程序,统计的文件路径,输出结果路径(这个路径必须是空的或者不存在的)
4.4 控制台执行效果图和web ui浏览效果图
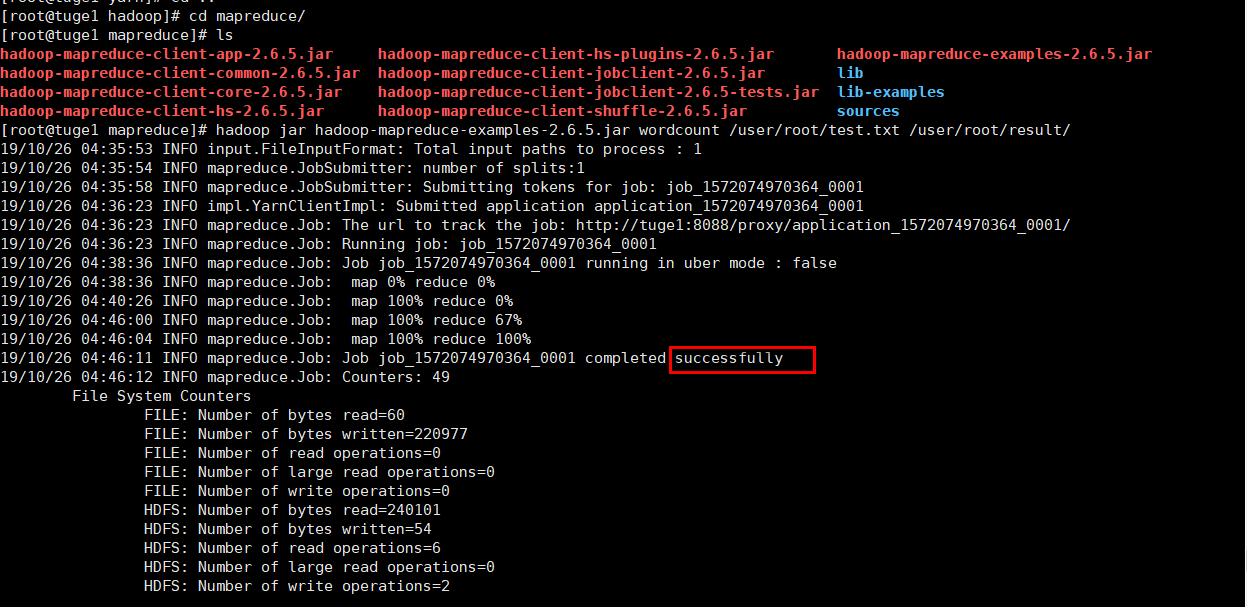
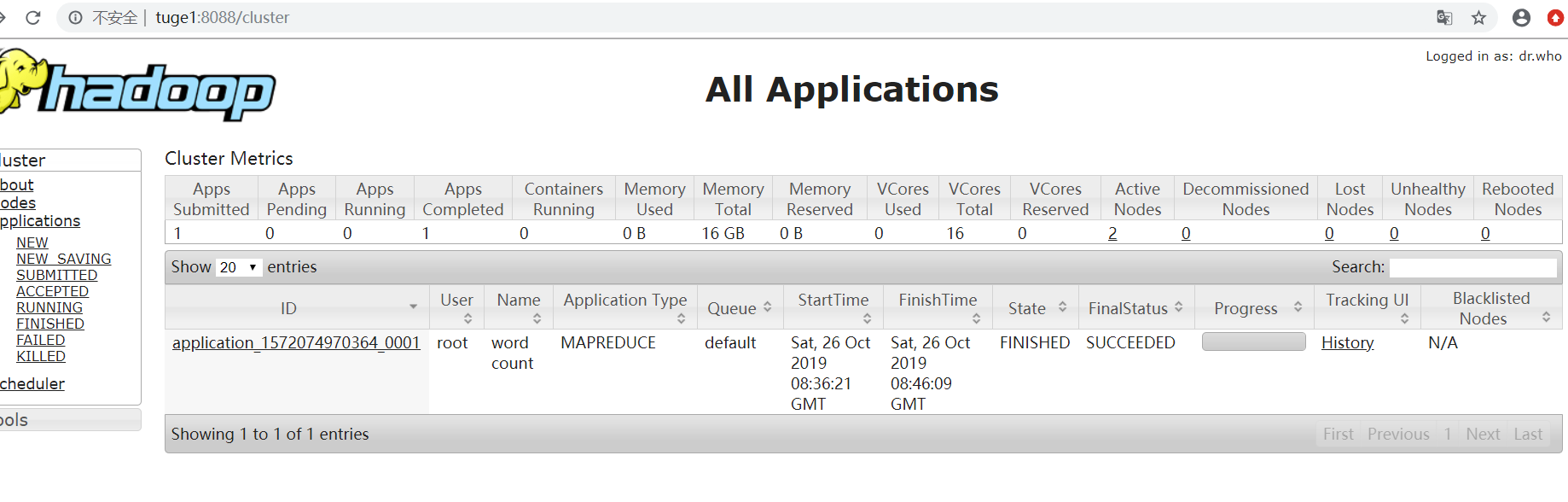
4.5最后我们可以在上面的输出目录查看统计结果
hadoop fs -cat /user/root/result/part-r-00000
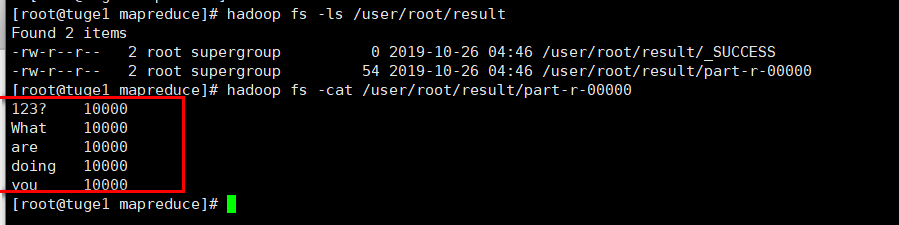
从上图可以看到,每个单词均输出10000,那么就哦了~