文章目录
本文参考:
1. 计算模型
MapReduce是由Google提出的一个分布式计算模型,用来解决海量数据的计算问题。举个例子说明其解决问题的思想:
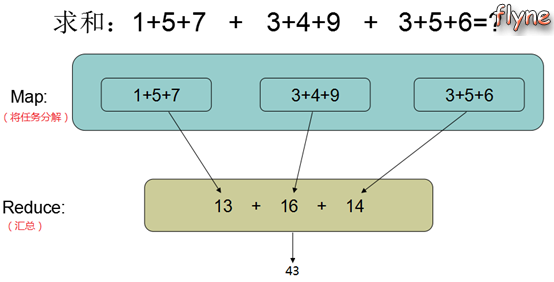
MapReduce由两个阶段组成:
- Map阶段:将一个大任务分解成小任务,并分发给每个节点,每个节点并行处理这些任务,处理速度很快;
- Reduce阶段:对Map的结果汇总即可,在不要求全局汇总的情况下Reduce阶段也可以并发
2. 编程接口
按官方文档给的说明,我们先来看看Mapper和Reducer接口,应用程序通常会实现它们以提供map和reduce方法。然后我们将讨论其他核心接口,包括Job,Partitioner,InputFormat,OutputFormat等。
最后,我们将讨论框架的一些有用功能,如DistributedCache,IsolationRunner等。
Hadoop MapReduce实现了很多可直接使用的InputFormat、Partitioner、OutputFormat,大部分情况下,用户只需编写Mapper和Reducer即可。
应用程序通常实现Mapper和Reducer接口以提供map和reduce方法。 这些构成了工作的核心。
MapReduce原理
mapper
-
mapper将key/value对映射到一组中间key/vallue对。 -
mapper过程是将输入记录转换为中间记录的各个任务。 转换后的中间记录不需要与输入记录的类型相同。 给定的输入对可以映射到零个或多个输出对。
-
MapReduce框架使用
InputFormat为每个map作业生成InputSplit。 -
总的来说,Mapper实现通过
Job.setMapperClass(Class)方法传递作业的Job。 然后,对于该InputSplit对应的task,调用map(WritableComparable,Writable,Context)处理InputSplit中的每个键/值对。 然后,应用程序可以重写cleanup(Context)方法以执行任何所需的清理。
有多少maps
- maps的数量通常由输入的总大小驱动,即输入文件的块总数。可以设置。
reducer
Reducer有3个主要阶段:shuffle,sort和reduce。
Shuffle
- Reducer的输入是
maps的排过序的输出。 在此阶段,框架通过HTTP获取所有maps的输出的相关分区。
sort
- 由于不同的maps会有相同的key,此阶段通过key进行分组,作为Reducer的输入。
shuffle和sort(可称洗牌和分拣)同时发生,有相同的map的key时,将会被合并。
Secondary Sort
reduce
- 在此阶段,为分组输入中的每个
<key,(list of values)>对调用reduce(WritableComparable,Iterable <Writable>,Context)方法。 reduce任务的输出通常通过Context.write(WritableComparable,Writable)写入FileSystem。
应用程序可以使用计数器报告其统计信息。
Reducer的输出未排序。
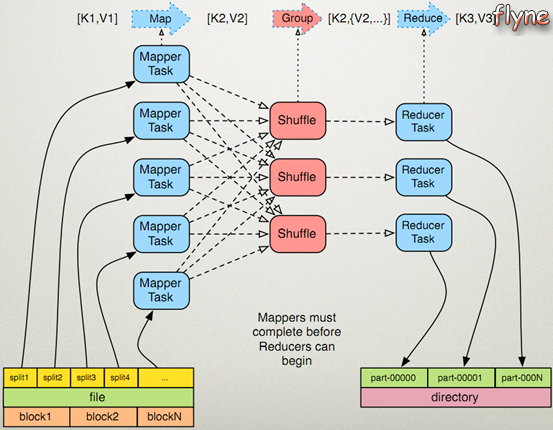
图解:
1)Mapper任务
- 读取输入文件内容(可以来自于本地文件系统,或HDFS文件系统等),对输入文件的每一行,解析成key-value对[K1,V1]。K1表示行起始偏移量,V1表示读取的一行内容。
- 调用map()方法,将[K1,V1]作为参数传入。在map()方法中封装了数据处理的逻辑,对输入的key、value进行处理。
map()方法处理的结果也用key-value的方式进行输出,记为[K2, V2]。
2)Reducer任务
- 在执行Reducer任务之前,有一个shuffle的过程对多个mapper任务的输出进行合并、排序,输出[K2, {V2, …}]。
- 调用reduce()方法,将[K2, {V2, …}]作为参数传入。在reducer()方法中封装了数据汇总的逻辑,对输入的key、value进行汇总处理。
reduce()方法的输出被保存到指定的目录下。
第一个MapReduce程序:WordCount
WordCount程序之于MapReduce就像HelloWorld程序之于任何编程语言,都是初学者接触的第一个程序。这儿不再赘述WordCount程序实现的功能。利用MapReduce实现的WordCount程序的思想如下图:

环境
进入本地hadoop包,启动namenode和datanode即可。
./sbin/hadoop-daemon.sh start namenode
./sbin/hadoop-daemon.sh start datanode
开始编程
如果你的项目是个Maven项目,直接在pom.xml文件中添加hadoop-common、mapreduce和yarn的依赖即可。
pom.xml:
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2-2323</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.2-2323</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.2-2323</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.7.2-2323</version>
</dependency>
</dependencies>
1) 编写WordCountMapper
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
/**
* 在执行Mapper任务之前,MapReduce框架中有一个组件(FileInputFormat的一个实例对象)会读取文件中的一行,将这一行的起始偏移量和行内容封装成key-value,作为参数传入map()方法。
*/
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//拿到一行的内容
String line = value.toString();
//将行内容切分成单词数组
String[] words = StringUtils.split(line, ' ');
for (String word : words) {
//输出 <单词,1> 这样的key-value对
context.write(new Text(word), new LongWritable(1L));
}
}
}
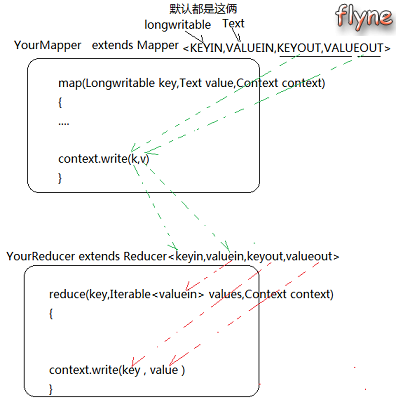
编写Mapper类应注意:
- Mapper类中的四个泛型分别表示
KEYIN、VALUEIN、KEYOUT和VALUEOUT。其中KEYIN、VALUEIN的类型默认为LongWritable和Text,表示MR程序输入文件中一行的起始偏移量和行内容。KEYOUT和VALUEOUT同map阶段的输出key-value类型一致。 - Hadoop中的
LongWritable、Text就相当于Java中的Long和String类型,它是Hadoop利用自己的序列化机制对Long和String的封装。在Hadoop中有自己的序列化机制(实现Writable接口),它比Java中的序列化机制更加简洁高效。
2) 编写WordCountReducer类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
/**
* 在调用reduce方法之前有个shuffle过程
* reduce()方法的输入数据来自于shuffle的输出,格式形如:<hello, {1,1,……}>
*/
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context)
throws IOException, InterruptedException {
//定义一个累加计数器
long counter = 0;
//统计单词出现次数
for (LongWritable value : values) {
counter += value.get();
}
//输出key表示的单词的统计结果
context.write(key, new LongWritable(counter));
}
}
下图是Mapper、Reducer类中泛型的说明:
3) 编写main入口
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 定义一个MapReduce程序的入口
* 本类中有一个Job对象,该对象用于描述一个MapReduce作业,如Mapper类、Reducer类,以及map/reduce过程的输出类型等等
*/
public class WordCount {
public static void main(String[] args) throws Exception {
//实例化一个Job对象
Configuration conf = new Configuration(); //加载配置文件
conf.set("fs.defaultFS","hdfs://localhost:9000");
// conf.set("fs.defaultFS","hdfs://cluster-host1:9000");
Job job = Job.getInstance(conf);
//设置Job作业所在jar包
job.setJarByClass(WordCount.class);
//设置本次作业的Mapper类和Reducer类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//设置Mapper类的输出key-value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置Reducer类的输出key-value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//指定本次作业要处理的原始文件所在路径(注意,是目录)
FileInputFormat.setInputPaths(job, new Path("/test/README.txt"));
// FileInputFormat.setInputPaths(job, new Path("/user/whb/hi.txt"));
//指定本次作业产生的结果输出路径(也是目录)
FileOutputFormat.setOutputPath(job, new Path("/test/t10"));
// FileOutputFormat.setOutputPath(job, new Path("/user/whb/hi-out"));
//提交本次作业,并打印出详细信息
job.waitForCompletion(true);
}
}
编写WordCount类应注意:
-
如果没有单独设置
Mapper类的输出key-value类型,那么setOutputKeyClass()、setOutputValueClass()方法对Mapper类也奏效。 -
在本例中MapReduce作业读写的是hdfs文件,这是较常见的,也可以读本地。
-
setInputPaths()指定输入的原始文件的路径时,是指文件所在的目录,该目录下的所有文件都会被当成输入文件;setOutputPath()方法指定输出文件的目录,一定要注意的是,不能指定一个已存在的目录作为输出目录,否则会报FileAlreadyExistsException的错误。 -
本例直接在程序中指定了路径仅仅是说明方便,但是实际开发时一般不直接在程序中指定路径,而是将输入输出路径作为main方法的参数传入(☆)。
Question:setInputPaths和setOutputPath中的路径是本地路径还是HDFS路径由什么决定?即判断一个MR作业使用何种文件系统
Answer:MR作业即job对象,一个job对象是通过Job.getInstance(conf)获得,在conf中可以设置fs.defaultFS属性,该属性即表示了MR作业所使用的文件系统。默认情况下MR作业使用本地文件系统,如果设置了fs.defaultFS为hdfs://xxxx:9000,则使用HDFS文件系统。
MR程序中可以使用本地文件系统和HDFS,这也表明MR程序和底层文件系统是解耦的,实际上在MR框架中是通过使用不同的FileSystem实现类访问不同的文件系统。
4) 运行方式
1.直接在idea中运行
查看结果:
./bin/hadoop fs -ls -R hdfs://localhost:9000/test/
-rw-r--r-- 3 didi supergroup 1366 2019-06-12 12:12 hdfs://localhost:9000/test/README.txt
-rw-r--r-- 3 didi supergroup 0 2019-08-07 10:15 hdfs://localhost:9000/test/t10/_SUCCESS
-rw-r--r-- 3 didi supergroup 1306 2019-08-07 10:15 hdfs://localhost:9000/test/t10/part-r-00000
执行结束后,在setOutputPath指定的目录下可以看到MR作业的输出文件:_SUCCESS和part-r-00000。part-r-00000文件内容如下:
./bin/hadoop fs -text hdfs://localhost:9000/test/t10/part-r-00000
(BIS), 1
(ECCN) 1
(TSU) 1
(see 1
5D002.C.1, 1
740.13) 1
<http://www.wassenaar.org/> 1
...
2.打包使用java -jar提交
打包的时候,需要在pom中添加打包插件,如assembly:
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals><goal>single</goal></goals>
</execution>
</executions>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<mainClass>cn.whbing.hadoop.mr.WordCount</mainClass> <!-- 你的主类名 -->
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
同时关于mapreduce的三个依赖 core、common、jobclient 都要加上:
如下:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.2-2323</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.7.2-2323</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.7.2-2323</version>
</dependency>
在WordCount.java中需要额外设置:
// 提交集群使用下边配置
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
并修改输入输出:
conf.set("fs.defaultFS","hdfs://cluster-host1:9000");
FileInputFormat.setInputPaths(job, new Path("/user/whb/hi.txt"));
FileOutputFormat.setOutputPath(job, new Path("/user/whb/hi-out"));
在集群运行:
java -jar demo-mr-1.0-SNAPSHOT-jar-with-dependencies.jar cn.whbing.hadoop.mr.WordCount
结果:
hadoop fs -text /user/whb/hi-out/part-r-00000
append 1
didi! 1
hello 1
second 1
说明:对于MR任务,hadoop封装了hadoop jar或者yarn jar命令,都能提交任务。如:
hadoop jar
hadoop jar demo-mr-1.0-SNAPSHOT-jar-with-dependencies.jar cn.whbing.hadoop.mr.WordCount
19/08/07 15:48:56 INFO client.RMProxy: Connecting to ResourceManager at cluster-host1/10.179.72.122:8032
19/08/07 15:48:56 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
19/08/07 15:48:57 INFO input.FileInputFormat: Total input paths to process : 1
19/08/07 15:48:57 INFO mapreduce.JobSubmitter: number of splits:1
19/08/07 15:48:57 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1565062438979_0002
19/08/07 15:48:57 INFO impl.YarnClientImpl: Submitted application application_1565062438979_0002
19/08/07 15:48:57 INFO mapreduce.Job: The url to track the job: http://cluster-host1:8088/proxy/application_1565062438979_0002/
19/08/07 15:48:57 INFO mapreduce.Job: Running job: job_1565062438979_0002
19/08/07 15:49:05 INFO mapreduce.Job: Job job_1565062438979_0002 running in uber mode : false
19/08/07 15:49:05 INFO mapreduce.Job: map 0% reduce 0%
19/08/07 15:49:11 INFO mapreduce.Job: map 100% reduce 0%
19/08/07 15:49:16 INFO mapreduce.Job: map 100% reduce 100%
19/08/07 15:49:16 INFO mapreduce.Job: Job job_1565062438979_0002 completed successfully
19/08/07 15:49:16 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=72
FILE: Number of bytes written=243243
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=132
HDFS: Number of bytes written=34
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=3800
Total time spent by all reduces in occupied slots (ms)=2469
Total time spent by all map tasks (ms)=3800
Total time spent by all reduce tasks (ms)=2469
Total vcore-milliseconds taken by all map tasks=3800
Total vcore-milliseconds taken by all reduce tasks=2469
Total megabyte-milliseconds taken by all map tasks=3891200
Total megabyte-milliseconds taken by all reduce tasks=2528256
Map-Reduce Framework
Map input records=2
Map output records=4
Map output bytes=58
Map output materialized bytes=72
Input split bytes=106
Combine input records=0
Combine output records=0
Reduce input groups=4
Reduce shuffle bytes=72
Reduce input records=4
Reduce output records=4
Spilled Records=8
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=372
CPU time spent (ms)=1530
Physical memory (bytes) snapshot=472371200
Virtual memory (bytes) snapshot=4603121664
Total committed heap usage (bytes)=354942976
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=26
File Output Format Counters
Bytes Written=34
yarn jar
与上述类似。